
Los workloads efímeros, los enfocados en procesamiento de datos y en IA/ML, han ganado mucho terreno gracias al rápido auge de las aplicaciones dinámicas basadas en flujos de trabajo, donde los workloads de corta duración cumplen un rol clave. Estos procesos exigen recursos de cómputo altamente escalables y flexibles para responder a tareas temporales y, muchas veces, intensivas en recursos. Los pods de Kubernetes son efímeros e inmutables por diseño, lo que los vuelve una excelente opción para este tipo de aplicaciones. Sin embargo, cuando se va más allá de los workloads estándar de Kubernetes —como Deployments o Daemonsets— aparecen nuevos desafíos y, lamentablemente, los modelos y estrategias tradicionales de Kubernetes pueden quedarse cortos.
Si estás leyendo esto, lo más probable es que ya hayas enfrentado estos retos al gestionar entornos dinámicos de K8s e incluso te hayas topado con preguntas como:
- ¿Estoy gestionando los workloads efímeros de forma eficiente, sin sobreaprovisionar ni quedarme corto de recursos?
- ¿Mi monitoreo está bien configurado para medir el rendimiento y el uso de recursos de manera efectiva?
- Si la respuesta es sí en 1 y 2, ¿cómo puedo confirmarlo con datos confiables?
Vamos a profundizar en los workloads efímeros, repasar los desafíos que pueden surgir y explorar estrategias prácticas para resolverlos.
¿A qué le llamamos "workloads efímeros"?
Como ya mencionamos, todos los pods de Kubernetes son efímeros por naturaleza (a menos que formen parte de un StatefulSet). Sin embargo, cuando hablamos de workloads efímeros nos referimos a tareas (relativamente) cortas, sin estado, que usan recursos de forma dinámica y no pertenecen a un recurso estándar de la API como Job o CronJob. En esencia, son pods independientes creados por controladores personalizados como Knative, Airflow Kubernetes Executor o Spark Operator. También entran aquí los pods de ejecución de CI/CD activados por Gitlab o Jenkins. Estos pods se ejecutan solo cuando hace falta y se apagan automáticamente al terminar, lo que encaja a la perfección con los entornos dinámicos.
La orquestación de este tipo de workload es esencial para manejar procesos dinámicos y de corta duración en pipelines de datos e IA. Resultan útiles para procesar big data y para gestionar tareas de machine learning, como el entrenamiento de modelos. Podemos concluir entonces que estos workloads aportan la flexibilidad y escalabilidad necesarias para ejecutar operaciones complejas, temporales e intensivas en recursos de forma más eficiente.
Pero ¿realmente tus workloads dinámicos son eficientes?
¿Por qué los workloads efímeros disparan mis gastos?
Al ejecutar tus aplicaciones de IA/ML pueden aparecer picos inesperados de costos. Suelen tomarte por sorpresa, sobre todo cuando usas workloads efímeros (de corta duración) que escalan constantemente para responder a la demanda. Escale rápido o no, usar bien los recursos puede convertirse en un dolor de cabeza. Entender por qué los workloads efímeros pueden disparar los costos es el primer paso para controlar el gasto en la nube y, en última instancia, mejorar la eficiencia.
Analizamos a fondo varios casos y detectamos algunas razones clave por las que una solución que parece eficiente a primera vista puede convertirse rápidamente en una de las mayores fuentes de pérdida en la nube.
Notamos que muchos clientes tienen problemas para hacer seguimiento del uso de recursos en tiempo real por la naturaleza dinámica de los workloads efímeros, que tienden a ser impredecibles tanto en cuándo se ejecutan como en cuántos recursos consumen. Esa falta de visibilidad suele derivar en sobreaprovisionamiento durante los picos de demanda y en subutilización en los valles, lo que se traduce en costos desperdiciados. Como estos workloads pueden estar muy fragmentados y levantarse según la necesidad, las estrategias tradicionales de monitoreo dejan de ser efectivas y, lamentablemente, en muchos casos los equipos solo ven la punta del iceberg.
Nuestro equipo también identificó una especie de "placer culpable" derivado de no comprender bien los workloads dinámicos ni la demanda en momentos de tráfico pico, lo que termina generando ineficiencias. Sobreaprovisionar para asegurar el rendimiento en los momentos de mayor carga —cuando el workload tal vez no aproveche todos los recursos— es un ejemplo clásico.
Por último, está el caso en que los workloads efímeros terminan sus tareas pero siguen ocupando recursos como memoria o CPU que no se aprovechan al máximo, lo que genera gastos innecesarios. Sin automatización para reducir rápidamente los recursos sin uso, los costos crecen sin entregar valor.
¡Mejora la eficiencia, no los costos de K8s!
Tener claro el problema ayuda a enfocarse en resolverlo y deja en evidencia la necesidad de una solución adecuada que cubra los aspectos mencionados. Inspirados por estos desafíos, nos entusiasma presentar un enfoque único para hacer right-sizing autónomo de workloads efímeros, parte de PerfectScale by DoiT.
La automatización de PerfectScale permite optimizar workloads de K8s sin esfuerzo, incluso en entornos dinámicos y complejos. Elimina la capacidad sin uso, reduce significativamente los costos en la nube y garantiza un rendimiento al máximo nivel, sin latencias ni cuellos de botella.
Bastan dos pasos sencillos para empezar a optimizar workloads efímeros como SparkJobs, Airflow, Temporal y otros.
Paso 1: Agrupa los workloads efímeros
PerfectScale incorpora inteligencia avanzada para agrupar workloads dinámicos y facilitar la agregación de datos de entidades transitorias. Así obtienes mejor visibilidad y análisis, te enfocas en lo que importa con datos accionables y, en consecuencia, reduces el gasto en la nube. Solo tienes que añadir las etiquetas necesarias a tus workloads. Una vez listo, PerfectScale se encarga del resto del proceso automáticamente.
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobUna vez que tus workloads estén agrupados en uno de tipo, digamos, Custom_SparkJob, podrás filtrar el ruido de los datos caóticos, mitigar su naturaleza impredecible y gestionar workloads efímeros de forma más efectiva, o pasar al siguiente paso para automatizar todo el proceso y obtener resultados inmediatos.
Paso 2: Configura una automatización flexible
Estás a un paso de automatizar por completo tu flujo de optimización. Lo único que falta es configurar la automatización para tu workload Custom_SparkJob. En esta etapa, PerfectScale ofrece un abanico de opciones de configuración altamente personalizables que puedes aplicar mediante un Custom Resource (CR).
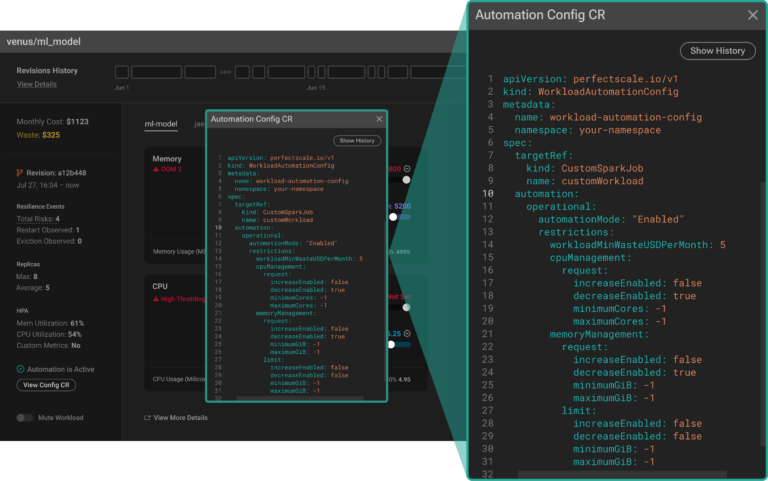
Este enfoque aporta flexibilidad y te permite ajustar la automatización con precisión, adaptándola fácilmente a tus casos de uso y a las necesidades operativas de tu aplicación.
A continuación, nuestro algoritmo basado en IA y nuestras analíticas avanzadas mejoran la predicción de patrones de workload y ajustan la asignación de recursos a partir de datos históricos.
¿Cómo me sirve esta funcionalidad?
Caso de uso 1: Airflow Kubernetes Executor
Apache Airflow® es la principal plataforma open-source para orquestar pipelines de datos y flujos de ML. Airflow gestiona los flujos como grafos acíclicos dirigidos (DAG) compuestos por tareas discretas. El executor de Kubernetes para Airflow permite que cada instancia de tarea se ejecute en su propio pod dentro de un cluster de Kubernetes.
Cuando un DAG envía una tarea, el executor de Kubernetes solicita un pod worker a la API de Kubernetes. Ese pod worker ejecuta la tarea, reporta el resultado y se termina.
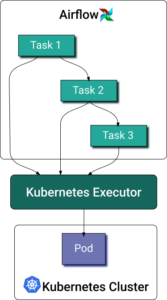
Como con cualquier otro pod, asignar recursos a tareas de Airflow basadas en Python no es trivial. Algunas necesitan más memoria para cargar grandes volúmenes de datos, mientras que otras son más intensivas en CPU por sus cálculos complejos. Definir de antemano los requests y limits de recursos del contenedor es difícil debido a la naturaleza dinámica de las tareas de procesamiento de datos. De hecho, la mayoría de los data engineers probablemente decida no definirlos. Si revisas los ejemplos oficiales de la documentación de Airflow Kubernetes Executor, ninguno incluye especificaciones de recursos. Por otro lado, medirlo es complicado por la naturaleza efímera de los pods worker de Airflow.
La única forma de gestionar la asignación de recursos para los workers de Airflow es agruparlos por alguna propiedad común (por ejemplo, una etiqueta de pod) y configurar automáticamente sus requests y limits cuando se crean en el cluster.
De esta manera, se pueden obtener recomendaciones basadas en las métricas de pods previos y aplicarlas a los nuevos pods que cree Airflow. Por suerte, eso es justo lo que la nueva funcionalidad de automatización de workloads agrupados de PerfectScale te permite hacer sin esfuerzo.
Caso de uso 2: Pods Driver y Executor de Spark con Spark Operator
El Kubernetes Operator para Apache Spark busca que especificar y ejecutar aplicaciones Spark sea tan sencillo e idiomático como ejecutar otros workloads en Kubernetes. Usa recursos personalizados de Kubernetes para especificar, ejecutar y exponer el estado de las aplicaciones Spark.
Cada vez que se crea o actualiza un recurso personalizado SparkApplication, el controlador de Spark actúa sobre los watch events, lo que dispara la creación de los pods driver y executor de Spark.
Veamos el siguiente diagrama, que muestra cómo interactúan y trabajan en conjunto los distintos componentes.
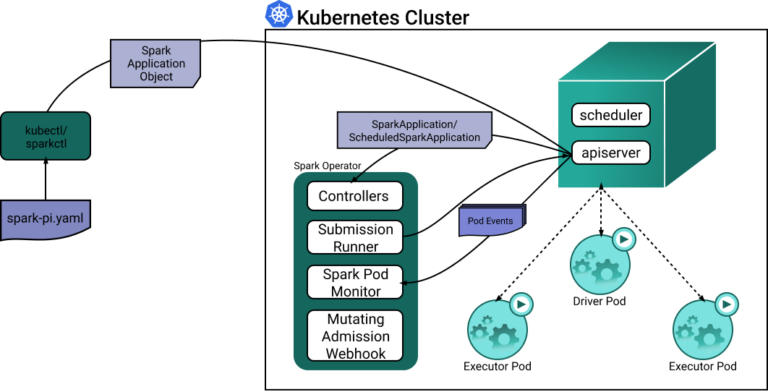
Mientras que los pods driver de Spark son bastante uniformes en su consumo de recursos, los pods executor procesan cargas dinámicas y pueden ser muy ineficientes si corren con una configuración estática. Aquí un ejemplo de cómo el Spark operator configura la asignación de recursos del pod executor:
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkComo se ve, esto solo permite configurar requests y no limits, además de que las definiciones son estáticas. Para asignar la cantidad correcta de recursos a los workloads efímeros de Spark, podemos omitir inicialmente la asignación de recursos de los pods executor y agruparlos en PerfectScale mediante etiquetas como, por ejemplo:perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
Después, podemos habilitar sin fricción la automatización para configurar los recursos de los executors cada vez que el operator los cree.
### Caso de uso 3: Jenkins Jobs
El [plugin Jenkins Kubernetes](https://plugins.jenkins.io/kubernetes/) permite escalar los agentes de Jenkins que corren en Kubernetes. El plugin crea un Pod de Kubernetes por cada agente que se inicia y lo detiene tras cada build.
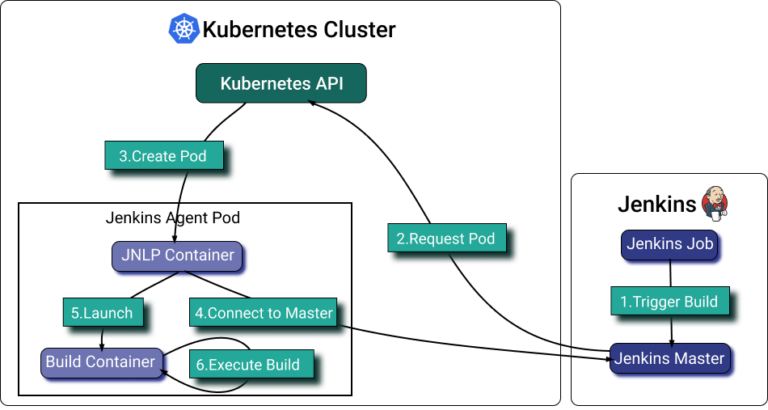
Aunque los pod templates de Jenkins permiten configurar las asignaciones de recursos por contenedor, acertar es muy difícil. Lo que sí podemos hacer es definir etiquetas en los pods, agrupar todos los pods de agentes Jenkins relevantes en PerfectScale y automatizar la asignación de recursos según el uso real.
En conclusión, gestionar, escalar y optimizar aplicaciones dinámicas de IA/ML no es trivial. Puede ser un reto para los equipos y no siempre da los resultados esperados. Nuestro equipo está convencido de que con las herramientas y estrategias correctas, estos procesos pueden llevarse al máximo nivel y los objetivos se alcanzan de manera efectiva.
Conoce más en nuestra [documentación](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads) o agenda una [sesión técnica](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs) con nuestro equipo para ver cómo esta funcionalidad puede ayudarte.
¿Aún no usas PerfectScale by DoiT? [Empieza hoy mismo, es gratis](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads).