
Ephemere Workloads für Datenverarbeitung und AI/ML haben deutlich an Bedeutung gewonnen – getrieben durch die rasante Entwicklung dynamischer, workflow-basierter Anwendungen, in denen kurzlebige Workloads eine Schlüsselrolle spielen. Diese Prozesse verlangen hochskalierbare und flexible Compute-Ressourcen, um ihre temporären, aber oft ressourcenintensiven Aufgaben zu bewältigen. Kubernetes-Pods sind von Haus aus ephemer und unveränderlich – und damit wie geschaffen für diese Art von Anwendung. Sobald wir uns jedoch von Standard-Kubernetes-Workloads wie Deployments oder Daemonsets entfernen, entstehen neue Herausforderungen, und klassische Kubernetes-Modelle und ‑Strategien stoßen schnell an ihre Grenzen.
Wenn Sie diesen Artikel lesen, kennen Sie vermutlich die Tücken im Umgang mit dynamischen K8s-Umgebungen – und vielleicht auch Fragen wie diese:
- Betreibe ich meine ephemeren Workloads effizient, ohne über zu provisionieren oder Ressourcenengpässe zu riskieren?
- Ist mein Monitoring so aufgesetzt, dass Performance und Ressourcenverbrauch zuverlässig erfasst werden?
- Falls 1 und 2 mit Ja zu beantworten sind: Wie lässt sich das mit belastbaren Datenpunkten belegen?
Tauchen wir tiefer in das Thema ephemere Workloads ein, beleuchten typische Stolpersteine und finden konkrete Strategien, um sie zu lösen.
Was verstehen wir unter "ephemeren Workloads"?
Wie eingangs erwähnt: Alle Kubernetes-Pods sind von Natur aus ephemer (sofern sie nicht Teil eines StatefulSets sind). Wenn wir hier jedoch von ephemeren Workloads sprechen, meinen wir die (relativ) kurzlebigen, zustandslosen Tasks, die Ressourcen dynamisch nutzen und nicht von einer Standard-API-Ressource wie Job oder CronJob verwaltet werden. Im Kern handelt es sich um eigenständige Pods, die von Custom Controllern wie Knative, Airflow Kubernetes Executor oder Spark Operator erzeugt werden. Oder auch um CI/CD-Execution-Pods, die von Gitlab oder Jenkins ausgelöst werden. Diese Pods laufen nur bei Bedarf und beenden sich automatisch, sobald ihre Aufgabe erledigt ist – ideal für dynamische Umgebungen.
Die Orchestrierung solcher Workloads ist essenziell, um dynamische, kurzlebige Prozesse in Daten- und AI-Pipelines zuverlässig zu steuern. Sie eignen sich hervorragend für Big-Data-Verarbeitung und für Machine-Learning-Aufgaben wie das Modelltraining. Daraus lässt sich ableiten: Diese Workloads bringen die nötige Flexibilität und Skalierbarkeit mit, um komplexe, temporäre und ressourcenintensive Operationen effizienter zu bewältigen.
Doch sind Ihre dynamischen Workloads tatsächlich effizient?
Warum treiben ephemere Workloads meine Kosten in die Höhe?
Beim Betrieb von AI/ML-Anwendungen können unerwartete Kostenspitzen auftreten. Sie kommen oft aus dem Nichts – besonders bei ephemeren (kurzlebigen) Workloads, die ständig hoch- und herunterskalieren, um die Nachfrage zu decken. Egal, ob die Anwendung zu schnell skaliert oder nicht: Ressourcen wirklich effektiv zu nutzen, kann zur Geduldsprobe werden. Zu verstehen, warum ephemere Workloads die Kosten in die Höhe treiben, ist der erste Schritt, um Ihre Cloud-Ausgaben in den Griff zu bekommen und nachhaltig Effizienz zu schaffen.
Wir haben uns diese Fälle genauer angesehen und mehrere zentrale Gründe identifiziert, warum eine auf den ersten Blick effiziente Lösung schnell zum großen Treiber von Cloud-Waste werden kann.
Uns ist aufgefallen, dass viele Kunden Schwierigkeiten haben, den Ressourcenverbrauch in Echtzeit nachzuverfolgen – schlicht aufgrund der Dynamik ephemerer Workloads, deren Laufzeit und Ressourcenbedarf kaum vorhersehbar sind. Die fehlende Sichtbarkeit führt häufig zu Über-Provisionierung in Hochlastphasen und zu Unterauslastung in ruhigen Phasen – und damit zu unnötigen Kosten. Da diese Workloads stark fragmentiert sind und je nach Bedarf hochgefahren werden, greifen klassische Monitoring-Strategien nicht mehr – und Teams sehen oft nur die Spitze des Eisbergs.
Unser Team hat außerdem eine Art "guilty pleasure" beobachtet, das aus mangelndem Verständnis dynamischer Workloads und Bedarfsspitzen resultiert und zu Ineffizienzen führt. Ein klassisches Beispiel: Über-Provisionierung, um in Stoßzeiten Performance zu garantieren – obwohl der Workload die Ressourcen womöglich gar nicht voll ausschöpft.
Und nicht zu vergessen: jene Situation, in der ephemere Workloads ihre Aufgabe längst beendet haben, aber weiterhin Ressourcen wie Memory oder CPU belegen, die kaum genutzt werden – mit unnötigen Kosten als Folge. Ohne Automatisierung, die ungenutzte Ressourcen zügig herunterfährt, wachsen die Kosten, ohne irgendeinen Mehrwert zu liefern.
Effizienz steigern, statt K8s-Kosten!
Das Problem klar zu benennen, schafft Fokus für die Lösung – und macht deutlich, dass es den richtigen Ansatz braucht, der all diese Aspekte abdeckt. Genau aus diesen Herausforderungen heraus freuen wir uns, einen einzigartigen Ansatz für das autonome Right-Sizing ephemerer Workloads vorzustellen: PerfectScale by DoiT.
Die Automatisierung von PerfectScale ermöglicht eine mühelose Optimierung von K8s-Workloads – auch in dynamischen und komplexen Umgebungen. Sie eliminiert ungenutzte Kapazitäten, senkt Cloud-Kosten signifikant und sichert Spitzenperformance ohne Latenzen oder Engpässe.
Mit zwei einfachen Schritten starten Sie in die Optimierung ephemerer Workloads wie SparkJobs, Airflow, Temporal und weiterer.
Schritt 1: Ephemere Workloads gruppieren
PerfectScale bringt eine ausgefeilte Logik mit, um dynamische Workloads zu gruppieren und so die Datenaggregation für transiente Entitäten zu vereinfachen. Das schafft mehr Sichtbarkeit und bessere Analysen, lenkt den Blick auf das Wesentliche – auf Basis handlungsrelevanter Datenpunkte – und senkt letztlich die Cloud-Ausgaben. Sie müssen lediglich die nötigen Labels an Ihre Workloads vergeben. Sobald das erledigt ist, übernimmt PerfectScale den Rest automatisch.
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobSind Ihre Workloads beispielsweise zu einem Workload vom Typ Custom_SparkJob zusammengefasst, lassen sich das Rauschen chaotischer Daten ausblenden, ihre Unvorhersehbarkeit entschärfen und ephemere Workloads deutlich effektiver steuern – oder Sie gehen den nächsten Schritt und automatisieren den Prozess vollständig für unmittelbare Ergebnisse.
Schritt 2: Flexible Automatisierung konfigurieren
Sie sind nur noch einen Schritt davon entfernt, Ihren Optimierungs-Flow vollständig zu automatisieren. Es fehlt lediglich die Konfiguration der Automatisierung für Ihren Custom_SparkJob-Workload. An dieser Stelle stellt PerfectScale eine Reihe hochgradig anpassbarer Automatisierungsoptionen bereit, die Sie über eine Custom Resource (CR) einrichten können.
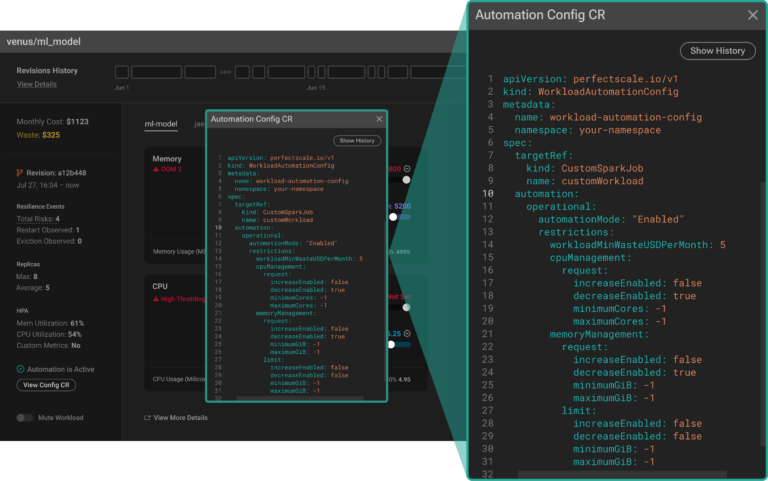
Dieser Ansatz schafft Flexibilität und erlaubt eine präzise Konfiguration der Automatisierung – einfach anpassbar an Ihre konkreten Use Cases und betrieblichen Anforderungen.
Im Anschluss verfeinert unser KI-gestützter Algorithmus zusammen mit ausgefeilten Analysen die Vorhersage von Workload-Mustern und passt die Ressourcenzuweisung anhand historischer Daten an.
Wie hilft mir dieses Feature konkret?
Use Case 1: Airflow Kubernetes Executor
Apache Airflow® ist die führende Open-Source-Plattform für die Orchestrierung von Daten-Pipelines und ML-Workflows. Airflow verwaltet Workflows als gerichtete azyklische Graphen (DAG), die aus diskreten Tasks bestehen. Der Kubernetes Executor für Airflow lässt jede Task-Instanz in einem eigenen Pod auf einem Kubernetes-Cluster laufen.
Reicht ein DAG einen Task ein, fordert der Kubernetes Executor einen Worker-Pod über die Kubernetes-API an. Der Worker-Pod führt den Task aus, meldet das Ergebnis und beendet sich anschließend.
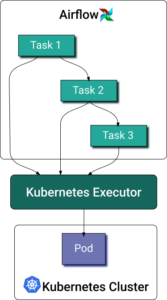
Wie bei jedem anderen Pod ist die Ressourcenzuweisung für Python-basierte Airflow-Tasks alles andere als trivial. Manche brauchen mehr Memory, um große Datenmengen zu laden, andere sind aufgrund komplexer Berechnungen CPU-intensiver. Container-Resource-Requests und ‑Limits im Vorfeld zu definieren, ist angesichts der Dynamik von Datenverarbeitungs-Tasks schwierig. Tatsächlich werden die meisten Data Engineers darauf wohl ganz verzichten. Ein Blick in die offiziellen Beispiele in der Dokumentation des Airflow Kubernetes Executors zeigt: Keines davon enthält Resource-Spezifikationen. Andererseits ist auch das Messen schwierig – wegen der ephemeren Natur der Airflow-Worker-Pods.
Der einzige Weg, die Ressourcenzuweisung für Airflow-Worker zu steuern, ist, sie über eine gemeinsame Eigenschaft (z. B. ein Pod-Label) zu gruppieren und ihre Resource-Requests und ‑Limits automatisch beim Erstellen im Cluster zu setzen.
So lassen sich Empfehlungen auf Basis der Metriken zuvor existierender Pods ableiten und auf die neu von Airflow erzeugten Pods anwenden. Glücklicherweise ist genau das das, was die neue Automatisierung für gruppierte Workloads von PerfectScale mühelos ermöglicht.
Use Case 2: Spark Driver- und Executor-Pods für den Spark Operator
Der Kubernetes Operator für Apache Spark hat das Ziel, das Spezifizieren und Ausführen von Spark-Anwendungen ebenso einfach und idiomatisch zu gestalten wie das Ausführen anderer Workloads auf Kubernetes. Er nutzt Kubernetes Custom Resources, um den Status von Spark-Anwendungen zu spezifizieren, auszuführen und sichtbar zu machen.
Wann immer eine SparkApplication-Custom-Resource erstellt oder aktualisiert wird, reagiert der Spark-Controller auf die Watch-Events – wodurch Spark-Driver- und Executor-Pods erzeugt werden.
Werfen wir einen Blick auf das folgende Diagramm, das zeigt, wie die einzelnen Komponenten interagieren und zusammenspielen.
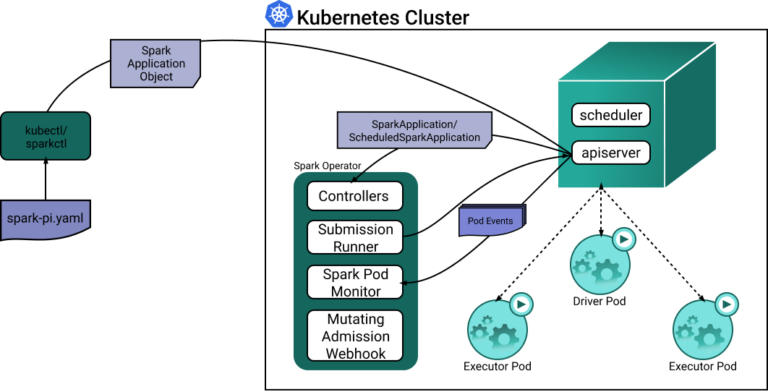
Während Spark-Driver-Pods im Ressourcenverbrauch ziemlich gleichförmig sind, verarbeiten Executor-Pods dynamische Payloads und können bei statischer Konfiguration sehr ineffizient laufen. Hier ein Beispiel, wie der Spark Operator die Ressourcenzuweisung für Executor-Pods konfiguriert:
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkMan sieht: Es lassen sich nur Requests, aber keine Limits setzen – und die Definitionen sind statisch. Um die richtige Menge an Ressourcen für die ephemeren Spark-Workloads zuzuweisen, können wir die Ressourcenzuweisung für die Executor-Pods zunächst überspringen und sie in PerfectScale über entsprechende Labels gruppieren, z. B.:perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
Anschließend können wir nahtlos die Automatisierung aktivieren, um die Ressourcen für Executors zu setzen, sobald sie vom Operator erzeugt werden.
### Use Case 3: Jenkins Jobs
Das [Jenkins Kubernetes Plugin](https://plugins.jenkins.io/kubernetes/) ermöglicht das Skalieren von Jenkins-Agents, die in Kubernetes laufen. Das Plugin erstellt für jeden gestarteten Agent einen Kubernetes-Pod und beendet ihn nach jedem Build.
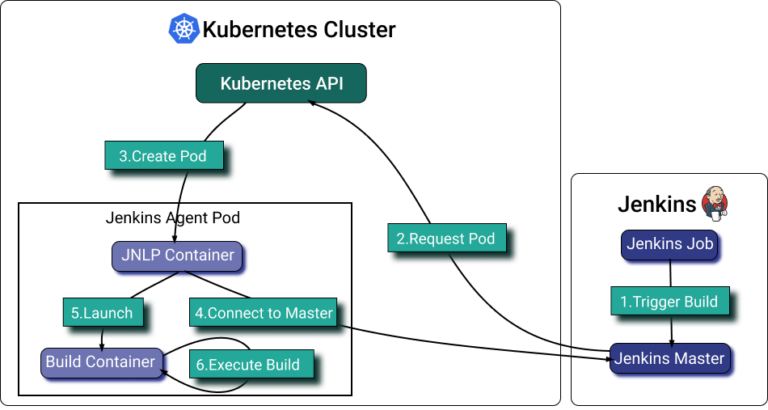
Zwar erlauben Jenkins-Pod-Templates das Setzen der Ressourcenzuweisungen pro Container, doch das sauber hinzubekommen ist sehr schwer. Was wir tun können: Pod-Labels setzen, alle relevanten Jenkins-Agent-Pods in PerfectScale gruppieren und ihre Ressourcenzuweisung anhand der tatsächlichen Auslastung automatisieren.
Fazit: Das Betreiben, Skalieren und Optimieren dynamischer AI/ML-Anwendungen ist alles andere als trivial. Es kann Teams vor erhebliche Herausforderungen stellen und liefert nicht immer die gewünschten Ergebnisse. Unser Team ist überzeugt: Mit den richtigen Tools und Strategien lassen sich diese Prozesse auf ein neues Level heben und Ziele effektiv erreichen.
Mehr erfahren Sie in unserer [Dokumentation](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads) – oder vereinbaren Sie eine [Technical Session](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs) mit unserem Team, um zu sehen, wie Sie das Feature konkret unterstützt.
Noch nicht mit PerfectScale by DoiT unterwegs? [Jetzt kostenlos starten](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads)!