
Les workloads éphémères, dédiés au traitement de données et à l'IA/ML, ont vu leur part progresser fortement avec l'essor des applications dynamiques basées sur des workflows, dans lesquelles les tâches de courte durée jouent un rôle clé. Ces processus exigent des ressources de calcul hautement scalables et flexibles pour absorber des charges temporaires, mais souvent gourmandes. Les pods Kubernetes étant éphémères et immuables par nature, ils se prêtent parfaitement à ce type d'application. Toutefois, dès que l'on sort des workloads Kubernetes standards comme les Deployments ou les Daemonsets, de nouveaux défis apparaissent et, malheureusement, les modèles et stratégies traditionnels de Kubernetes peuvent montrer leurs limites.
Si vous lisez ces lignes, vous avez probablement déjà été confronté à la gestion d'environnements K8s dynamiques, et peut-être même à des questions de ce type :
- Mes workloads éphémères sont-ils gérés efficacement, sans surdimensionnement ni risque de pénurie de ressources ?
- Mon monitoring est-il correctement configuré pour suivre les performances et la consommation de ressources ?
- Si oui aux deux questions précédentes, comment le confirmer avec des données fiables ?
Penchons-nous de plus près sur les workloads éphémères, les défis qu'ils soulèvent et les stratégies concrètes pour y répondre.
Qu'entend-on par workloads éphémères ?
Comme indiqué plus haut, tous les pods Kubernetes sont éphémères par nature (sauf s'ils font partie d'un StatefulSet). Mais quand on parle de workloads éphémères, on désigne les tâches (relativement) courtes et sans état, qui consomment des ressources de manière dynamique et ne dépendent pas d'une ressource API standard comme Job ou CronJob. Concrètement, il s'agit de pods autonomes créés par des contrôleurs personnalisés tels que Knative, Airflow Kubernetes Executor ou Spark Operator. On peut aussi citer les pods d'exécution CI/CD déclenchés par GitLab ou Jenkins. Ces pods s'exécutent uniquement à la demande et s'arrêtent automatiquement une fois la tâche terminée, ce qui convient parfaitement aux environnements dynamiques.
L'orchestration de ce type de workload est essentielle pour gérer des processus dynamiques et de courte durée dans les pipelines de données et d'IA. Elle s'avère précieuse pour le traitement de big data et la gestion de tâches de machine learning, comme l'entraînement de modèles. On peut donc en conclure que ces workloads apportent la flexibilité et la scalabilité nécessaires pour gérer plus efficacement des opérations complexes, temporaires et exigeantes en ressources.
Mais vos workloads dynamiques sont-ils réellement efficaces ?
Pourquoi les workloads éphémères font-ils grimper mes dépenses ?
Des pics de coûts inattendus peuvent survenir lors de l'exécution de vos applications IA/ML. Ils prennent souvent au dépourvu, en particulier avec des workloads éphémères (de courte durée) qui scalent en permanence pour suivre la demande. Que l'application monte trop vite en charge ou non, l'utilisation efficiente des ressources peut vite tourner au casse-tête. Comprendre pourquoi les workloads éphémères font grimper les coûts est la première étape pour maîtriser vos dépenses cloud et, à terme, gagner en efficacité.
Nous avons examiné ces cas de plus près et identifié plusieurs raisons clés pour lesquelles une solution efficace au premier abord peut rapidement devenir une source majeure de gaspillage cloud.
Nous avons constaté que de nombreux clients peinent à suivre la consommation de ressources en temps réel, du fait du caractère dynamique des workloads éphémères, dont les moments d'exécution et le niveau de consommation restent souvent imprévisibles. Ce manque de visibilité conduit fréquemment à un surdimensionnement en période de forte demande et à une sous-utilisation en période creuse, d'où des coûts inutiles. Comme ces workloads peuvent être très fragmentés et lancés à la volée, les stratégies de monitoring traditionnelles ne suffisent plus : malheureusement, dans bien des cas, les équipes ne voient que la pointe de l'iceberg.
Notre équipe a également observé une forme de plaisir coupable, lié à un manque de visibilité claire sur les workloads dynamiques et les besoins lors des pics de trafic, qui se traduit souvent par des inefficacités. Le surdimensionnement pour garantir les performances en période de forte affluence — alors même que le workload n'exploite pas pleinement les ressources — en est un exemple bien connu.
Enfin, il y a le cas où les workloads éphémères ont terminé leurs tâches mais continuent d'occuper des ressources comme la mémoire ou le CPU, sans réelle utilisation, ce qui génère des dépenses superflues. Sans automatisation pour libérer rapidement les ressources inutilisées, les coûts grimpent sans aucune valeur en retour.
Boostez l'efficacité, pas les coûts K8s !
Bien cerner le problème permet de mieux le traiter et met en évidence le besoin d'une solution adaptée capable de couvrir l'ensemble des aspects évoqués. Inspirés par ces défis, nous sommes ravis de vous présenter une approche unique pour le right-sizing autonome des workloads éphémères, signée PerfectScale by DoiT.
L'automatisation de PerfectScale optimise sans effort les workloads K8s, même dans les environnements dynamiques et complexes. Elle élimine la capacité inutilisée, réduit fortement les coûts cloud et garantit des performances optimales, sans latence ni goulots d'étranglement.
Deux étapes simples suffisent pour commencer à optimiser les workloads éphémères tels que SparkJobs, Airflow, Temporal et bien d'autres.
Étape 1 : regrouper les workloads éphémères
PerfectScale s'appuie sur une intelligence avancée pour regrouper les workloads dynamiques et faciliter l'agrégation des données pour les entités transitoires. Vous gagnez ainsi en visibilité, en pertinence d'analyse, vous concentrez vos efforts sur l'essentiel grâce à des données exploitables et, in fine, vous réduisez vos dépenses cloud. Il vous suffit d'ajouter les labels nécessaires à vos workloads. Une fois cette étape effectuée, PerfectScale prend automatiquement le relais.
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobUne fois vos workloads regroupés sous un type, par exemple Custom_SparkJob, vous pouvez facilement faire le tri dans le bruit des données, atténuer leur caractère imprévisible et gérer les workloads éphémères plus efficacement — ou passer directement à l'étape suivante pour automatiser entièrement le processus et obtenir des résultats immédiats.
Étape 2 : configurer une automatisation flexible
Vous n'êtes plus qu'à une étape de l'automatisation complète de votre flux d'optimisation. Il ne vous reste qu'à configurer l'automatisation pour votre workload Custom_SparkJob. À ce stade, PerfectScale propose toute une série d'options de configuration hautement personnalisables, à appliquer via une Custom Resource (CR).
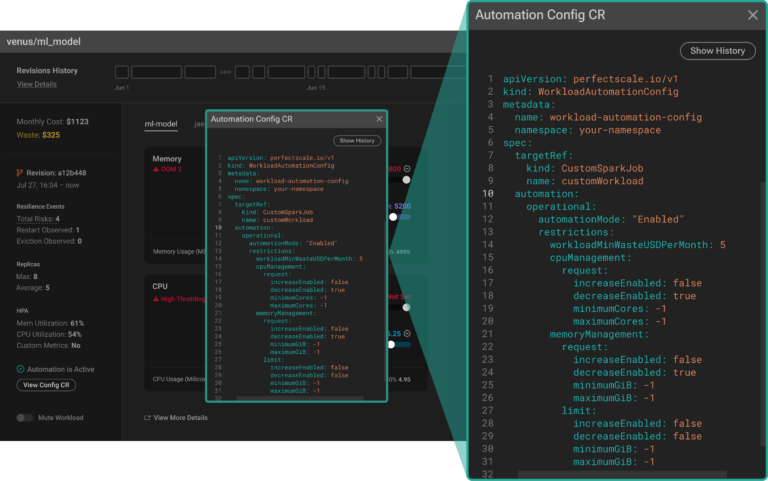
Cette approche apporte de la flexibilité et permet de configurer l'automatisation avec précision, pour s'adapter facilement à vos cas d'usage et aux besoins opérationnels de votre application.
Notre algorithme propulsé par l'IA et nos analyses avancées affinent ensuite la prédiction des schémas de workloads et ajustent l'allocation des ressources à partir des données historiques.
En quoi cette fonctionnalité peut-elle m'être utile ?
Cas d'usage 1 : Airflow Kubernetes Executor
Apache Airflow® est la principale plateforme open source d'orchestration de pipelines de données et de workflows ML. Airflow gère les workflows sous forme de graphes orientés acycliques (DAG) composés de tâches discrètes. L'exécuteur Kubernetes pour Airflow permet à chaque instance de tâche de s'exécuter dans son propre pod sur un cluster Kubernetes.
Lorsqu'un DAG soumet une tâche, l'exécuteur Kubernetes demande un worker pod à l'API Kubernetes. Le worker pod exécute la tâche, en remonte le résultat, puis s'arrête.
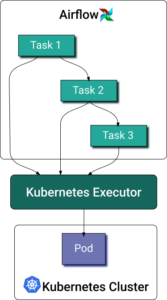
Comme pour tout autre pod, l'allocation de ressources pour les tâches Airflow en Python n'a rien de trivial. Certaines auront besoin de plus de mémoire pour charger de gros volumes de données, tandis que d'autres seront plus gourmandes en CPU à cause de calculs complexes. Définir à l'avance les requests et limits de ressources des conteneurs reste ardu, étant donné la nature dynamique des tâches de traitement de données. De fait, la plupart des data engineers choisiront probablement de ne pas les définir. En consultant les exemples officiels de la documentation Airflow Kubernetes Executor, vous constaterez qu'aucun ne précise les ressources. À l'inverse, mesurer cette consommation est tout aussi complexe en raison de la nature éphémère des worker pods Airflow.
La seule façon de gérer l'allocation de ressources pour les workers Airflow consiste à les regrouper selon une propriété commune (par exemple un label de pod) et à définir automatiquement leurs requests et limits dès leur création dans le cluster.
On peut ainsi obtenir des recommandations basées sur les métriques des pods précédents et les appliquer aux nouveaux pods créés par Airflow. C'est précisément ce que la nouvelle fonctionnalité d'automatisation des workloads regroupés de PerfectScale vous permet de faire sans effort.
Cas d'usage 2 : pods driver et executor de Spark pour Spark Operator
Le Kubernetes Operator pour Apache Spark vise à rendre la déclaration et l'exécution d'applications Spark aussi simples et naturelles que celles d'autres workloads sur Kubernetes. Il s'appuie sur des ressources personnalisées Kubernetes pour spécifier, exécuter et exposer le statut des applications Spark.
Chaque fois qu'une ressource personnalisée SparkApplication est créée ou mise à jour, le contrôleur Spark réagit aux événements observés, ce qui déclenche la création des pods driver et executor de Spark.
Examinons le diagramme suivant, qui illustre l'interaction et la coopération des différents composants.
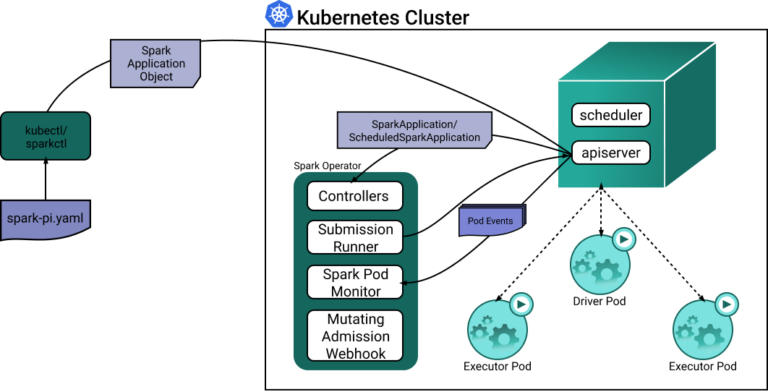
Si les pods driver Spark présentent une consommation de ressources plutôt uniforme, les pods executor traitent des charges dynamiques et peuvent se révéler très inefficaces avec une configuration statique. Voici un exemple de configuration de l'allocation de ressources des pods executor par l'opérateur Spark :
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkOn constate que cela permet uniquement de définir des requests, pas de limits, et que les définitions sont statiques. Pour allouer la bonne quantité de ressources aux workloads Spark éphémères, on peut dans un premier temps ne pas spécifier d'allocation pour les pods executor, puis les regrouper dans PerfectScale à l'aide de labels comme :perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
Il ne reste plus qu'à activer l'automatisation pour définir les ressources des executors dès leur création par l'opérateur.
### Cas d'usage 3 : Jobs Jenkins
Le [plugin Kubernetes pour Jenkins](https://plugins.jenkins.io/kubernetes/) permet de scaler les agents Jenkins exécutés dans Kubernetes. Le plugin crée un pod Kubernetes pour chaque agent démarré, qui s'arrête après chaque build.
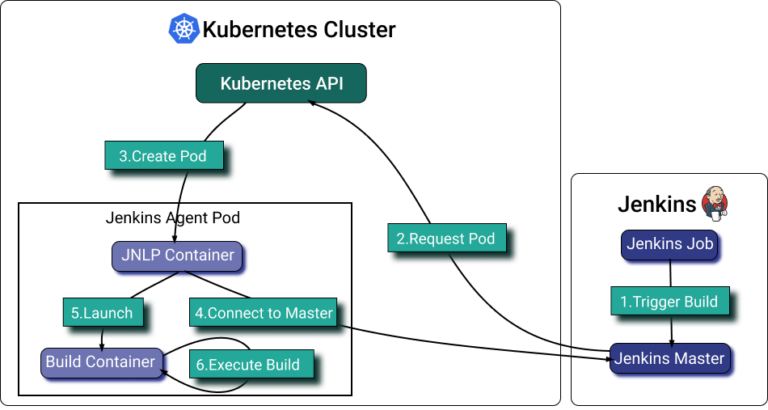
Si les pod templates Jenkins permettent de définir l'allocation de ressources par conteneur, le bon calibrage reste très difficile à obtenir. Une bonne approche consiste à appliquer des labels aux pods, à regrouper l'ensemble des pods d'agents Jenkins concernés dans PerfectScale, puis à automatiser leur allocation de ressources en fonction de leur utilisation réelle.
En conclusion, gérer, faire évoluer et optimiser des applications IA/ML dynamiques n'a rien d'évident. Cela peut représenter un véritable défi pour les équipes et ne pas produire les résultats escomptés. Notre équipe est convaincue que les bons outils et les bonnes stratégies peuvent porter ces processus à un niveau supérieur et permettre d'atteindre vos objectifs efficacement.
Pour en savoir plus, consultez notre [documentation](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads), ou planifiez une [session technique](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs) avec notre équipe pour découvrir comment cette fonctionnalité peut vous aider.
Vous n'utilisez pas encore PerfectScale by DoiT ? [Lancez-vous dès aujourd'hui — c'est gratuit](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads) !