
Os workloads efêmeros voltados a processamento de dados e IA/ML ganharam protagonismo com o avanço acelerado das aplicações dinâmicas baseadas em fluxos de trabalho, em que tarefas de curta duração têm papel central. Esses processos exigem recursos computacionais altamente escaláveis e flexíveis para dar conta de tarefas temporárias e, muitas vezes, pesadas em consumo. Os pods do Kubernetes são, por design, efêmeros e imutáveis — o que os torna uma escolha natural para esse tipo de aplicação. Porém, ao sair dos workloads padrão do Kubernetes, como Deployments ou Daemonsets, novos desafios aparecem e, infelizmente, modelos e estratégias tradicionais do Kubernetes podem não dar conta do recado.
Se você chegou até aqui, é provável que já tenha enfrentado dificuldades para gerenciar ambientes K8s dinâmicos e talvez tenha se feito perguntas como:
- Estou gerenciando os workloads efêmeros de forma eficiente, sem superprovisionar nem correr risco de faltar recurso?
- Meu monitoramento está bem configurado para acompanhar performance e uso de recursos de verdade?
- Se a resposta para 1 e 2 for sim, dá para confirmar isso com dados confiáveis?
Vamos nos aprofundar nos workloads efêmeros, mapear os desafios mais comuns e apresentar estratégias práticas para resolvê-los.
O que chamamos de "workloads efêmeros"?
Como já dissemos, todos os pods do Kubernetes são efêmeros por natureza (a menos que façam parte de um StatefulSet). Mas, quando falamos em workloads efêmeros, estamos nos referindo a tarefas (relativamente) curtas, sem estado, que usam recursos de forma dinâmica e que não pertencem a um recurso de API padrão como Job ou CronJob. Em essência, são pods autônomos criados por controladores customizados como Knative, Airflow Kubernetes Executor e Spark Operator. Ou ainda pods de execução de CI/CD disparados pelo Gitlab ou Jenkins. Esses pods rodam só quando precisam e se encerram automaticamente ao terminar — algo que se encaixa perfeitamente em ambientes dinâmicos.
Orquestrar esse tipo de workload é fundamental para lidar com processos dinâmicos e de curta duração em pipelines de dados e IA. Eles ajudam no processamento de big data e na gestão de tarefas de machine learning, como o treinamento de modelos. Daí dá para concluir que esses workloads entregam a flexibilidade e a escalabilidade necessárias para executar operações complexas, temporárias e intensivas em recursos de forma mais eficiente.
Mas será que seus workloads dinâmicos são realmente eficientes?
Por que os workloads efêmeros disparam meus custos?
Picos inesperados de custo podem aparecer enquanto você roda suas aplicações de IA/ML. E costumam pegar todo mundo de surpresa, especialmente quando se usam workloads efêmeros (de curta duração) que escalam o tempo todo para acompanhar a demanda. Seja porque a aplicação escala rápido demais, seja porque escala de menos, usar os recursos com eficiência vira uma dor de cabeça. Entender por que os workloads efêmeros podem inflar a conta é o primeiro passo para controlar seus gastos com nuvem e, no fim, ganhar eficiência.
Olhamos esses casos de perto e descobrimos várias razões importantes pelas quais uma solução que parece eficiente à primeira vista pode rapidamente virar um grande gerador de desperdício na nuvem.
Notamos que muitos clientes têm dificuldade em acompanhar o uso de recursos em tempo real por causa da natureza dinâmica dos workloads efêmeros, que tendem a ser imprevisíveis em termos de quando vão rodar e de quanto vão consumir. Essa falta de visibilidade costuma levar a superprovisionamento nos picos e à subutilização nos vales, o que se traduz em desperdício de dinheiro. Como esses workloads podem ser bastante fragmentados e subir sob demanda, as estratégias tradicionais de monitoramento já não dão conta — e, infelizmente, na maior parte dos casos, os times só enxergam a ponta do iceberg.
Nosso time também identificou um certo "prazer culpado" causado pela falta de uma visão clara dos workloads dinâmicos e da demanda em horários de pico, o que costuma gerar ineficiências. Superprovisionar para garantir performance em momentos de alta — quando o workload pode nem chegar a usar tudo — é o exemplo clássico.
Por último, mas não menos importante, há a situação em que os workloads efêmeros já terminaram suas tarefas, mas continuam ocupando recursos como memória ou CPU que não estão sendo plenamente utilizados, gerando despesa à toa. Sem automação para reduzir rapidamente os recursos ociosos, os custos sobem sem entregar valor algum.
Mais eficiência, sem inflar os custos do K8s!
Esclarecer o problema ajuda a focar na solução e reforça a necessidade de uma ferramenta certa para cobrir todos os pontos citados. Inspirados por esses desafios, é com entusiasmo que apresentamos uma abordagem única para fazer right-sizing autônomo de workloads efêmeros: o PerfectScale by DoiT.
A automação do PerfectScale otimiza workloads K8s sem esforço, mesmo em ambientes dinâmicos e complexos. Ela elimina capacidade ociosa, reduz significativamente os custos de nuvem e garante performance máxima sem latência ou gargalos.
Bastam dois passos simples para começar a otimizar workloads efêmeros como SparkJobs, Airflow, Temporal e outros.
Passo 1: Agrupe os workloads efêmeros
O PerfectScale traz inteligência avançada para agrupar workloads dinâmicos, facilitando a agregação de dados de entidades transitórias. Com isso, você ganha mais visibilidade e capacidade de análise, foca no que importa com dados acionáveis e, no fim, reduz despesas com nuvem. Tudo o que você precisa fazer é adicionar as labels necessárias aos seus workloads. Feito isso, o PerfectScale cuida automaticamente do restante para você.
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobDepois que seus workloads estiverem agrupados em um workload do tipo, digamos, Custom_SparkJob, fica fácil cortar o ruído de dados caóticos, contornar a imprevisibilidade e gerenciar workloads efêmeros com muito mais eficácia — ou seguir para o próximo passo e automatizar o processo todo, com resultados imediatos.
Passo 2: Configure uma automação flexível
Agora você está a um passo de automatizar totalmente seu fluxo de otimização. Só falta configurar a automação para o seu workload Custom_SparkJob. Nessa etapa, o PerfectScale oferece várias opções altamente personalizáveis de configuração da automação, aplicáveis por meio de um Custom Resource (CR).
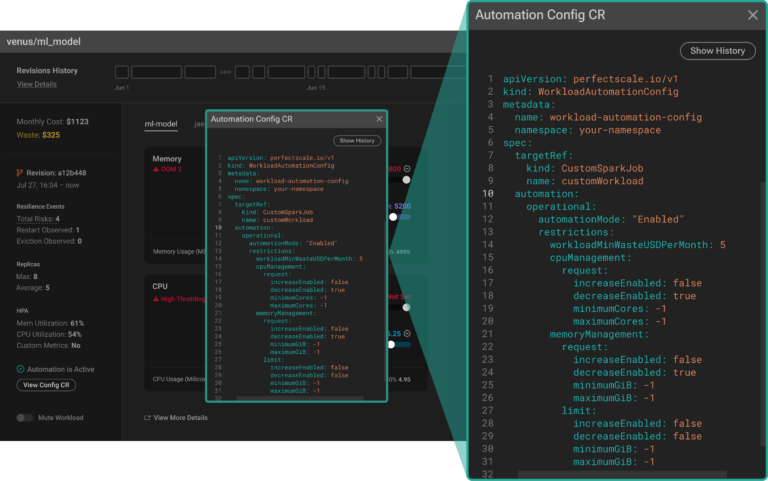
Essa abordagem traz flexibilidade e permite configurar a automação com precisão, facilitando o ajuste aos seus casos de uso e às necessidades operacionais da aplicação.
Na sequência, nosso algoritmo com IA e nossas análises sofisticadas aprimoram a previsão dos padrões dos workloads e ajustam a alocação de recursos com base em dados históricos.
Como esse recurso pode funcionar para mim?
Caso de uso 1: Airflow Kubernetes Executor
O Apache Airflow® é a principal plataforma open-source para orquestrar pipelines de dados e fluxos de ML. O Airflow gerencia os workflows como grafos acíclicos dirigidos (DAG), formados por tarefas discretas. O Kubernetes executor do Airflow permite que cada instância de tarefa rode no seu próprio pod, dentro de um cluster Kubernetes.
Quando uma DAG submete uma tarefa, o Kubernetes executor solicita um worker pod à API do Kubernetes. O worker pod então executa a tarefa, reporta o resultado e é encerrado.
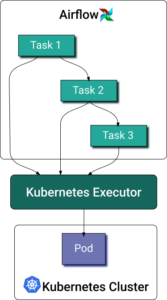
Como em qualquer outro pod, alocar recursos para tarefas do Airflow em Python não é trivial. Algumas podem precisar de mais memória para carregar grandes volumes de dados, enquanto outras são mais intensivas em CPU por causa de cálculos complexos. Definir os requests e limits do contêiner com antecedência é difícil pela própria natureza dinâmica das tarefas de processamento de dados. Na prática, a maioria dos engenheiros de dados acaba não definindo isso. Se você olhar os exemplos oficiais da documentação do Airflow Kubernetes Executor, vai notar que nenhum deles traz especificação de recursos. Por outro lado, medir esse consumo é difícil justamente pela natureza efêmera dos worker pods do Airflow.
A única maneira de gerenciar a alocação de recursos para os workers do Airflow é agrupá-los por alguma propriedade comum (uma label de pod, por exemplo) e definir automaticamente seus requests e limits no momento em que são criados no cluster.
Assim, conseguimos gerar recomendações com base nas métricas de pods anteriores e aplicá-las aos novos pods criados pelo Airflow. Felizmente, é exatamente isso que o novo recurso de automação para workloads agrupados do PerfectScale entrega, sem esforço.
Caso de uso 2: pods de Spark Driver e Executor para o Spark Operator
O Kubernetes Operator for Apache Spark busca tornar a especificação e a execução de aplicações Spark tão simples e naturais quanto rodar qualquer outro workload no Kubernetes. Ele usa custom resources do Kubernetes para especificar, executar e expor o status das aplicações Spark.
Sempre que um custom resource SparkApplication é criado ou atualizado, o controlador do Spark reage aos eventos de watch, o que provoca a criação dos pods de driver e executor do Spark.
Veja o diagrama a seguir, que mostra como os diferentes componentes interagem e funcionam em conjunto.
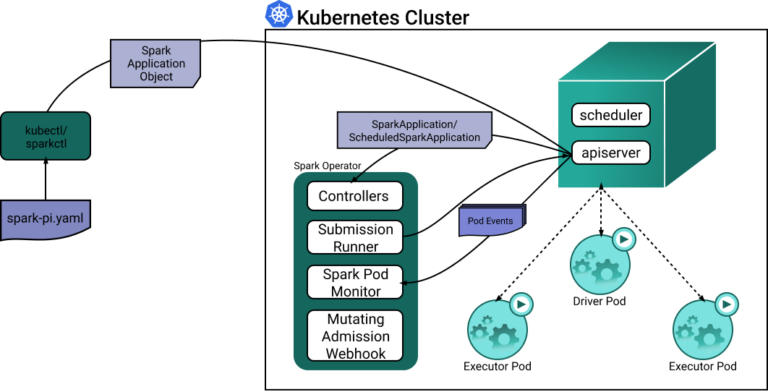
Enquanto os pods de driver do Spark costumam ter consumo de recursos bem uniforme, os pods executores processam cargas dinâmicas e podem ser bastante ineficientes se rodarem com configuração estática. Veja um exemplo de como o Spark operator configura a alocação de recursos dos pods executores:
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkDá para perceber que isso só permite definir requests, e não limits, e que as definições são estáticas. Para alocar a quantidade certa de recursos para os workloads efêmeros do Spark, podemos, num primeiro momento, pular a alocação para os pods executores e agrupá-los no PerfectScale com labels como, por exemplo:perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
Depois, basta habilitar a automação de forma transparente para definir os recursos dos executores sempre que forem criados pelo operator.
### Caso de uso 3: Jobs do Jenkins
O [plugin Jenkins Kubernetes](https://plugins.jenkins.io/kubernetes/) permite escalar agentes do Jenkins rodando no Kubernetes. O plugin cria um pod do Kubernetes para cada agente iniciado e o encerra ao final de cada build.
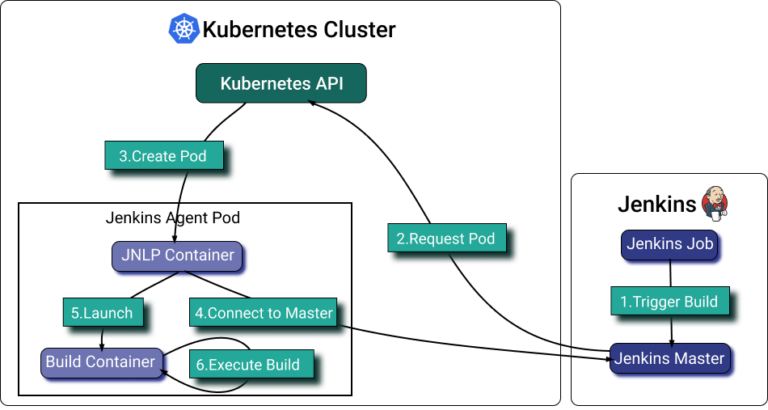
Embora os pod templates do Jenkins permitam definir alocação de recursos por contêiner, acertar esse ajuste é muito difícil. O que dá para fazer é definir labels nos pods, agrupar todos os pods de agentes Jenkins relevantes no PerfectScale e automatizar a alocação de recursos conforme a utilização real.
Em resumo, gerenciar, escalar e otimizar aplicações dinâmicas de IA/ML não é trivial. É um desafio para os times e nem sempre entrega os resultados esperados. Nosso time acredita que, com as ferramentas e estratégias certas, dá para levar esses processos a um novo patamar e atingir os objetivos com eficácia.
Saiba mais na nossa [documentação](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads) ou agende uma [sessão técnica](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs) com nosso time para ver como esse recurso pode ajudar você.
Ainda não usa o PerfectScale by DoiT? [Comece hoje — é grátis](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads)!