
I workloads effimeri dedicati all'elaborazione dati e all'AI/ML hanno conquistato sempre più spazio, complice la rapida diffusione di applicazioni dinamiche basate su workflow in cui i processi di breve durata sono protagonisti. Si tratta di attività che richiedono risorse di calcolo molto scalabili e flessibili, capaci di gestire task temporanei ma spesso intensivi. I pod Kubernetes sono effimeri e immutabili per design, quindi si prestano bene a questo tipo di applicazioni. Quando però ci si spinge oltre i workloads Kubernetes standard come Deployments o Daemonsets, emergono nuove sfide e i modelli e le strategie tradizionali di Kubernetes rischiano di non bastare.
Se è arrivato fin qui, probabilmente sa già cosa significa gestire ambienti K8s dinamici e si è posto domande come queste:
- Sto gestendo i workloads effimeri in modo efficiente, senza sovradimensionare le risorse o rischiare di rimanere a corto?
- Il monitoraggio è configurato a dovere per tenere sotto controllo performance e consumo di risorse?
- Se la risposta ai punti 1 e 2 è sì, come posso confermarlo con dati affidabili?
Entriamo nel merito dei workloads effimeri, vediamo le sfide più frequenti e individuiamo strategie concrete per affrontarle.
Cosa intendiamo per "workloads effimeri"?
Come accennato, tutti i pod Kubernetes sono effimeri per natura (a meno che non facciano parte di uno StatefulSet). Quando però parliamo di workloads effimeri ci riferiamo a task (relativamente) di breve durata, stateless, che usano risorse in modo dinamico e non dipendono da una risorsa API standard come Job o CronJob. In pratica si tratta di pod standalone creati da controller personalizzati come Knative, Airflow Kubernetes Executor e Spark Operator. Oppure dei pod di esecuzione CI/CD avviati da Gitlab o Jenkins. Questi pod entrano in azione solo quando servono e si arrestano automaticamente al termine del lavoro: una soluzione perfetta per gli ambienti dinamici.
Orchestrare questo tipo di workload è fondamentale per gestire processi dinamici e di breve durata nelle pipeline di dati e AI. Sono utili nell'elaborazione di big data e nei task di machine learning, come il training dei modelli. La conclusione è chiara: questi workloads offrono la flessibilità e la scalabilità necessarie per gestire in modo più efficiente operazioni complesse, temporanee e ad alta intensità di risorse.
Ma i suoi workloads dinamici sono davvero efficienti?
Perché i workloads effimeri fanno lievitare i costi?
Quando si fanno girare applicazioni AI/ML, capita di ritrovarsi con picchi di costo inattesi. È un'eventualità tutt'altro che rara, soprattutto con workloads effimeri (di breve durata) che scalano di continuo per stare al passo con la domanda. Che l'app scali troppo in fretta o troppo lentamente, sfruttare bene le risorse può diventare un grattacapo. Capire perché i workloads effimeri fanno aumentare i costi è il primo passo per tenere sotto controllo la spesa cloud e, in ultima analisi, per guadagnare in efficienza.
Abbiamo analizzato da vicino questi casi e individuato diversi motivi per cui una soluzione che a prima vista sembra efficiente può rivelarsi un grande generatore di sprechi nel cloud.
Abbiamo notato che molti clienti faticano a monitorare l'uso delle risorse in tempo reale, proprio per la natura dinamica dei workloads effimeri: è imprevedibile sia quando entreranno in esecuzione, sia quante risorse consumeranno. Questa scarsa visibilità porta spesso all'over-provisioning nei picchi di domanda e al sotto-utilizzo nei momenti più tranquilli, con costi sprecati. Visto che questi workloads sono molto frammentati e si attivano on-demand, le strategie di monitoraggio tradizionali non funzionano più e, in molti casi, i team finiscono per vedere solo la punta dell'iceberg.
Il nostro team ha individuato anche una sorta di "piacere colpevole" che nasce dalla scarsa comprensione dei workloads dinamici e della domanda nei momenti di picco, da cui derivano spesso inefficienze. L'esempio classico è il sovradimensionamento delle risorse per garantire performance nei periodi più intensi, anche quando il workload non sfrutta appieno ciò che ha a disposizione.
Infine, c'è il caso in cui i workloads effimeri portano a termine i task ma continuano a occupare risorse come memoria o CPU senza utilizzarle davvero, generando spese inutili. Senza un'automazione capace di ridimensionare rapidamente le risorse non utilizzate, i costi crescono senza portare alcun valore.
Aumenti l'efficienza, non i costi di K8s!
Mettere a fuoco il problema aiuta a concentrarsi sulla soluzione e a riconoscere la necessità dello strumento giusto, capace di coprire tutti gli aspetti citati. Da queste sfide è nato un approccio inedito al right-sizing autonomo dei workloads effimeri, firmato PerfectScale by DoiT, che siamo entusiasti di presentarle.
L'automazione di PerfectScale rende immediata l'ottimizzazione dei workloads K8s, anche negli ambienti più dinamici e complessi. Elimina la capacità inutilizzata, riduce in modo significativo i costi cloud e garantisce performance al top, senza latenze né colli di bottiglia.
Bastano due semplici passaggi per iniziare a ottimizzare workloads effimeri come SparkJobs, Airflow, Temporal e altri.
Step 1: raggruppare i workloads effimeri
PerfectScale mette a disposizione un'intelligenza avanzata per raggruppare i workloads dinamici, semplificando l'aggregazione dei dati delle entità transitorie. Il risultato: maggiore visibilità e analisi più puntuali, focus su ciò che conta grazie a dati concreti e azionabili e, in ultima analisi, una riduzione della spesa cloud. Le basta aggiungere le label necessarie ai suoi workloads. Da quel momento in poi, ci pensa PerfectScale.
Labels:app: spark-job-over-hriautomation.perfectscale.io/generatedFrom: 53836ca7perfectscale.io/workload-grouping-honor-image: "true"perfectscale.io/workload-grouping-honor-spec: "true"perfectscale.io/workload-grouping-workload-name: spark-job-over-hriperfectscale.io/workload-grouping-workload-type: CustomSparkJobUna volta raggruppati i suoi workloads, ad esempio sotto il tipo Custom_SparkJob, può facilmente fare ordine nel rumore dei dati caotici, smorzarne l'imprevedibilità e gestire i workloads effimeri in modo molto più efficace, oppure passare allo step successivo per automatizzare tutto e ottenere risultati immediati.
Step 2: configurare un'automazione flessibile
È a un passo dall'automatizzare per intero il suo flusso di ottimizzazione. Manca solo la configurazione dell'automazione per il workload Custom_SparkJob. In questa fase PerfectScale mette a disposizione una serie di opzioni di configurazione altamente personalizzabili, applicabili tramite una Custom Resource (CR).
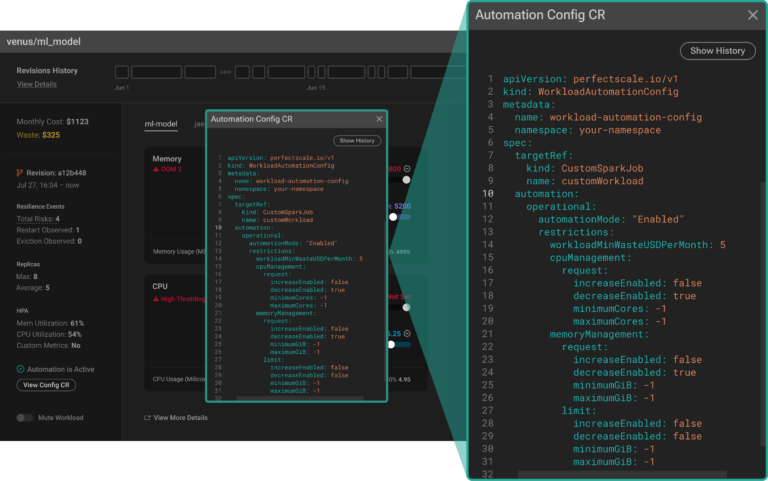
Un approccio flessibile, che le permette di configurare l'automazione con precisione e di adattarla facilmente ai suoi casi d'uso e alle esigenze operative dell'applicazione.
A questo punto, il nostro algoritmo basato su AI e le nostre analisi avanzate affinano la previsione dei pattern dei workloads e regolano l'allocazione delle risorse sulla base dei dati storici.
Come può funzionare per me questa funzionalità?
Caso d'uso 1: Airflow Kubernetes Executor
Apache Airflow® è la principale piattaforma open-source per orchestrare pipeline di dati e workflow di ML. Airflow gestisce i workflow come grafi aciclici diretti (DAG) composti da task discreti. L'executor Kubernetes per Airflow consente a ogni istanza di task di girare in un proprio pod su un cluster Kubernetes.
Quando un DAG sottomette un task, l'executor Kubernetes richiede un worker pod all'API di Kubernetes. Il worker pod esegue il task, riporta il risultato e termina.
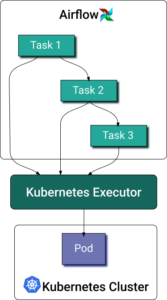
Come per qualsiasi altro pod, l'allocazione delle risorse per i task Airflow basati su Python non è banale. Alcuni richiedono più memoria per caricare grandi volumi di dati, altri sono più CPU-intensive per via di calcoli complessi. Definire in anticipo richieste e limiti delle risorse del container è difficile, vista la natura dinamica dei task di elaborazione dati. In effetti, la maggior parte dei data engineer preferisce non definirli affatto. Se osserva gli esempi ufficiali nella documentazione di Airflow Kubernetes Executor, nessuno include specifiche di risorse. D'altra parte, anche misurarle è arduo, sempre per la natura effimera dei worker pod di Airflow.
L'unico modo per gestire l'allocazione delle risorse per i worker di Airflow è raggrupparli in base a una proprietà comune (ad esempio, una label del pod) e impostarne automaticamente richieste e limiti al momento della creazione nel cluster.
In questo modo si ottengono raccomandazioni basate sulle metriche dei pod precedenti, da applicare ai nuovi pod creati da Airflow. Per fortuna è esattamente ciò che la nuova funzionalità di automazione dei workloads raggruppati di PerfectScale le permette di fare senza sforzo.
Caso d'uso 2: pod Driver ed Executor di Spark con Spark Operator
Il Kubernetes Operator per Apache Spark punta a rendere la definizione e l'esecuzione delle applicazioni Spark semplici e idiomatiche come quella di qualsiasi altro workload su Kubernetes. Sfrutta le custom resources Kubernetes per specificare, eseguire e mostrare lo stato delle applicazioni Spark.
Ogni volta che una custom resource SparkApplication viene creata o aggiornata, il controller Spark reagisce agli eventi di watch, dando vita ai pod driver ed executor di Spark.
Diamo un'occhiata al diagramma seguente, che mostra come i diversi componenti interagiscono e lavorano insieme.
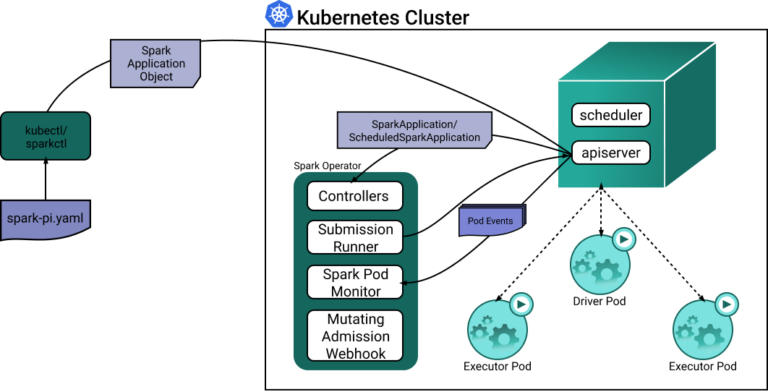
Mentre i pod driver di Spark hanno un consumo di risorse piuttosto uniforme, i pod executor processano payload dinamici e rischiano di essere molto inefficienti se eseguiti con una configurazione statica. Ecco un esempio di come lo Spark operator configura l'allocazione delle risorse dei pod executor:
```spec:
executor:
cores: 1
instances: 3
memory: 512m
labels:
version: 3.1.1
serviceAccount: sparkCome si nota, è possibile impostare solo le richieste e non i limiti, e le definizioni sono statiche. Per allocare la giusta quantità di risorse ai workloads Spark effimeri possiamo, in un primo momento, saltare l'allocazione delle risorse per i pod executor e raggrupparli in PerfectScale tramite label come queste:perfectscale.io/workload-grouping-workload-name=SparkJobName perfectscale.io/workload-grouping-workload-type=SparkJob perfectscale.io/workload-grouping-honor-image=true perfectscale.io/workload-grouping-honor-spec=true
A quel punto possiamo abilitare con disinvoltura l'automazione, in modo da impostare le risorse degli executor ogni volta che vengono creati dall'operator.
### Caso d'uso 3: Jenkins Jobs
Il [plugin Jenkins Kubernetes](https://plugins.jenkins.io/kubernetes/) permette di scalare gli agent di Jenkins in esecuzione su Kubernetes. Il plugin crea un Pod Kubernetes per ogni agent avviato e lo arresta a fine build.
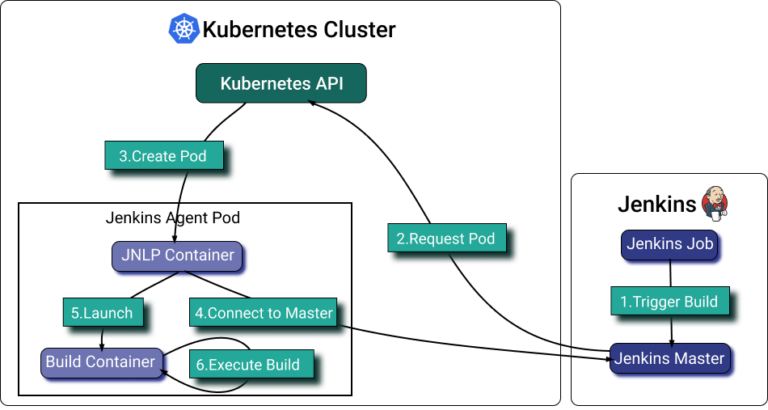
I pod template di Jenkins consentono di impostare le allocazioni di risorse per container, ma calibrarle correttamente è tutt'altro che semplice. La soluzione: impostare le label sui pod, raggruppare in PerfectScale tutti gli agent pod di Jenkins rilevanti e automatizzare l'allocazione delle risorse in base all'utilizzo reale.
In conclusione, gestire, scalare e ottimizzare applicazioni AI/ML dinamiche non è un'impresa banale. Può mettere alla prova i team e non sempre porta ai risultati sperati. Siamo convinti che gli strumenti e le strategie giuste possano portare questi processi a un livello superiore e raggiungere gli obiettivi in modo efficace.
Scopra di più nella nostra [documentazione](https://docs.perfectscale.io/enable-automation/including-a-cluster-namespace-or-workload-to-the-automation/configuring-automation-for-a-workload#automating-ephemeral-workloads), oppure prenoti una [sessione tecnica](https://www.google.com/url?q=https://scheduler.zoom.us/sales-team-waw79l/perfectscale-demo?utm_source%3Ddoit%26utm_medium%3Dreferral%26utm_campaign%3Dephemeral-workloads&sa=D&source=docs&ust=1739899468357789&usg=AOvVaw3gNIv-ajT49B_9OHclBxUs) con il nostro team per vedere come questa funzionalità può fare la differenza per lei.
Non usa ancora PerfectScale by DoiT? [Inizi oggi: è gratis](https://www.perfectscale.io/?utm_source=doit&utm_medium=referral&utm_campaign=ephemeral-workloads)!