はじめに:インテリジェントデータの新時代
データを取り巻く環境は、いま大きな転換期にあります。これまで数十年にわたり、データベースはデータを効率的に保存・整理・取得する仕組みとして設計され、トランザクションや分析を裏側で支えてきました。
しかし人工知能(AI)と機械学習(ML)が当たり前になった今、その役割だけでは足りません。現代のアプリケーションには、文脈を理解し、推論し、リアルタイムに応答する力が求められます。こうしたニーズに応えるべく、データベースは受け身のデータ保管庫から脱却し、データのある場所でインサイト・予測・レコメンデーションを生み出す能動的なインテリジェンス層へと進化しつつあります。
AWSもこのビジョンに向けて着実に歩を進めてきました。Aurora ML、Amazon AuroraおよびRDSにおけるpgvector、Amazon Redshift ML、OpenSearchのベクトル検索、Neptune MLといった革新を通じて、AWSのデータベースは名実ともにAI対応へと近づいています。
AI対応データベースの条件とは
AI対応データベースは、単なるデータの保管場所ではありません。データをAIで使える形にすることを目的に設計されています。データベースエンジンが本来扱うデータ型に加え、セマンティック検索や検索拡張生成(RAG)で利用されるベクトル埋め込みなど、AIネイティブなデータも扱います。MLモデルとシームレスに連携し、学習・デプロイ・リアルタイム推論を実現することで、従来型のデータベースをAIワークフローの中核へと変え、学習や予測をデータのすぐそばで実行できるようにします。
主な特徴は次のとおりです。
- ネイティブなML統合:SQLクエリから直接MLモデルを呼び出し、データ移動とレイテンシを抑えます。
- ベクトル埋め込み対応:意味を表す埋め込みを保存・クエリし、類似度や文脈を踏まえた検索を実現します。
- ストリーミング・リアルタイム対応:Amazon KinesisやManaged Streaming for Apache Kafka(MSK)と連携し、発生したイベントをその場で処理します。
- 柔軟なコンピュートとストレージ:データ量の増加に応じて、学習・推論・ベクトルworkloadsを自動でスケールします。
- 堅牢なガバナンスとセキュリティ:IAMロール、暗号化、データリネージのトラッキングにより、コンプライアンスと信頼性を担保します。
AWSデータベースが備えるAI/ML機能
AIと機械学習の活用が広がるなか、AWSのデータベースはインテリジェンスをデータ基盤の標準機能として組み込む方向に進化しています。リアルタイム推論からセマンティック検索、検索拡張生成(RAG)まで、もはや従来のストレージやクエリの域には収まりません。
ここからは、AuroraからS3まで、AWSのデータベースがどのようにAI対応へと進化し、文脈を理解し、データに対して推論を行い、情報のある場所でインサイトを届けるアプリケーションをどう支えているのかを見ていきましょう。
Amazon Aurora ML(Bedrock、SageMaker、Comprehendとの連携)
Amazon Aurora MLは、Amazon Bedrock、SageMaker、Comprehendと直接連携し、SQL文の中でML推論を実行できます。
たとえば次のSQLクエリは、データベース内で直接モデル推論を行います。
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
Aurora MLをBedrock、SageMaker、ComprehendといったAWSのAIサービスと組み合わせれば、機械学習をトランザクションworkloadsに直接組み込み、データを外部に出すことなくリアルタイム予測、異常検知、インテリジェントな自動化を実現できます。
Amazon AuroraとAmazon RDS for PostgreSQLにおけるpgvector
AWSは現在、Aurora PostgreSQLとRDS for PostgreSQLの両方でpgvectorをサポートしています。これにより、高次元の埋め込みをデータベース内で直接保存・インデックス化・クエリでき、外部のベクトルストアに頼らずにセマンティック検索や類似検索をネイティブに実行できます。pgvectorを使えば、Amazon BedrockやSageMakerなどのMLモデルで生成した埋め込みを保存し、<->のような演算子でベクトル間の類似度を算出できます。
たとえば次のクエリは、ベクトル類似度に基づいて最も類似する5件のドキュメントを取得します。
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
pgvectorをAWSのAIサービスと組み合わせれば、従来のSQLクエリとセマンティック検索を融合させたアプリケーションを構築できます。検索拡張生成(RAG)、インテリジェント検索、パーソナライズドレコメンデーションといったユースケースを、AuroraやRDS for PostgreSQLの環境内で完結できるのが強みです。
Amazon Redshift MLとBedrock連携
Amazon RedshiftはRedshift MLによって分析の幅をさらに広げ、データのエクスポートや別建てのMLインフラ管理を行わずに、SQLから直接機械学習モデルを構築・実行できます。Amazon SageMaker Autopilotと連携してモデル学習を自動化するほか、Amazon Bedrockもサポートし、テキスト要約、分類、対話型インサイトといった生成AI(GenAI)機能を利用できます。
Redshift MLは、ウェアハウスにすでに格納されているデータを使ってSageMaker上で予測モデルを学習・ホストし、ワークフロー全体を使い慣れたSQL構文で扱えるようにします。データ移動が不要になり、構成も簡素になり、予測インテリジェンスを分析レイヤーのすぐそばに置けるのが利点です。
たとえば次のコマンドは、Redshift内で顧客のチャーン予測モデルを直接学習させます。
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
デプロイ後は、他のSQL関数と同じ感覚で任意のクエリから呼び出し、リアルタイムに予測を実行できます。
Amazon OpenSearch Service & Serverless(ベクトル検索)
Amazon OpenSearch ServiceとOpenSearch Serverlessは、ネイティブのベクトル検索機能を備えています。意味的な理解と従来のキーワード検索を組み合わせ、両者の関連度を融合したハイブリッド検索や、ベクトル検索が生成AIモデルに文脈データを供給する検索拡張生成(RAG)といったユースケースを実現します。
OpenSearchのベクトル検索コレクションには、Amazon BedrockやSageMakerなどのMLモデルが生成したデータのベクトル表現、つまり埋め込みを保存します。これにより、完全一致のキーワード検索を超えた、意味や類似度に基づくクエリが可能になります。近似最近傍(ANN)検索を使えば、文字列の一致ではなく意味の上で最も関連性の高いドキュメント、商品、会話などを見つけ出せます。
たとえば次のクエリは、ベクトル類似度に基づいて最も類似する5件のドキュメントを取得します。
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearchはハイブリッドクエリにも対応し、キーワードとベクトルの関連度を組み合わせて、より文脈に沿った結果を返せます。Serverlessモードはクラスタ管理なしでベクトルworkloadsを自動的にスケールするため、変動の激しいAIアプリケーションや高トラフィックなシナリオに最適です。Amazon BedrockやSageMakerと組み合わせれば、埋め込み生成からインデックス作成までを自動化し、AWS内でセマンティック検索、RAG、パーソナライズドコンテンツ取得を完結できるフルマネージドなパイプラインを構築できます。
Amazon Neptune MLとNeptune Analytics
Amazon Neptune MLは、Deep Graph Library(DGL)とAmazon SageMakerを活用してグラフニューラルネットワーク(GNN)を学習・デプロイし、複雑なパイプラインを組まずにグラフデータベースへ機械学習を持ち込みます。属性そのものではなく、データ間のつながりから学習することで、関係性の予測、異常検知、的確なレコメンデーション生成を行います。
Neptune Analyticsはこの機能をさらに広げ、HNSWインデックスを用いたベクトル検索により、グラフ埋め込みに対するセマンティック類似度クエリを可能にします。関連エンティティの探索が容易になり、グラフを意識した文脈で検索拡張生成(RAG)パイプラインを強化できます。
Neptune MLとNeptune Analyticsを組み合わせれば、従来のグラフクエリは、不正検知、レコメンデーションシステム、ナレッジグラフといったアプリケーションを支える、文脈を踏まえた知的な推論へと進化します。
Amazon DocumentDB(MongoDB互換):ベクトル検索
Amazon DocumentDBはネイティブのベクトル検索に対応し、JSONドキュメント内にベクトル埋め込みを保存・クエリできるようになりました。これにより、構造化データと非構造化データを組み合わせ、セマンティック検索、検索拡張生成(RAG)、AIチャットボットを、別のベクトルデータベースへデータを移すことなく実現できます。
DocumentDBはAmazon BedrockやSageMakerとシームレスに連携し、埋め込みを生成できます。生成した埋め込みはコレクションに直接保存し、ベクトル類似度演算子を使って文脈に合ったドキュメントや応答を取得できます。
ドキュメント保存とセマンティック検索を一体化することで、DocumentDBは大規模環境でも軽快に動くナレッジ型アプリケーション、コンテンツ検索システム、インテリジェントアシスタントの構築をシンプルにします。
Amazon MemoryDB for Redis:インメモリベクトル検索
Amazon MemoryDB for Redisはインメモリベクトル検索に対応し、Redisのスピードに加えてAWSのスケーラビリティを兼ね備え、リアルタイムのセマンティック検索を可能にします。コサイン類似度、ユークリッド距離、内積を用いて埋め込みを保存・クエリでき、パーソナライゼーション、レコメンデーション、セマンティックキャッシュに最適です。
MemoryDBはすべてメモリ上で動作するため、ベクトル参照をマイクロ秒レベルのレイテンシで処理できます。標準のRedisクライアント経由でAmazon Bedrock、SageMaker、AWS Lambdaとシームレスに連携でき、大規模に埋め込みを生成・保存・取得できます。
こうした特性から、MemoryDBは低レイテンシのAI推論、セッションベースのパーソナライゼーション、瞬時のベクトル検索性能が求められる文脈対応のチャットアプリケーションにとって、有力な選択肢となります。
Amazon DynamoDB + OpenSearch:ベクトルのZero-ETL連携
Amazon DynamoDB自体はベクトルをネイティブに保存しませんが、Amazon OpenSearch ServiceとのZero-ETL統合により、構造化データを自動的にOpenSearchへ同期し、セマンティック検索やベクトル検索を実行できます。
この連携を使えば、Amazon BedrockやSageMakerで生成した埋め込みでDynamoDBのレコードを拡張し、ハイブリッド検索やベクトル類似検索でOpenSearchへ問い合わせられます。カスタムパイプラインの構築や手作業のデータ移動スクリプトは不要です。
DynamoDBのスケーラビリティと、OpenSearchのベクトル検索・分析機能を組み合わせれば、トランザクションデータと意味的データを統合した、リアルタイムなAIアプリケーションを構築できます。パーソナライゼーション、レコメンデーションエンジン、インテリジェント検索体験に特に効果を発揮します。
Amazon S3 Vectors(プレビュー)
Amazon S3 Vectorsは、Amazon S3上で埋め込みを直接保存・検索できる新たな仕組みで、オブジェクトストレージを大規模なベクトルデータレイクに変えます。現在はプレビュー提供で、別途ベクトルデータベースやインデックスサービスを立ち上げることなく、数十億規模の埋め込みを管理できます。
Amazon Bedrock、SageMaker、その他のMLモデルで埋め込みを生成し、ベクトルオブジェクトとしてS3に保存できます。これらのベクトルは類似性検索APIで問い合わせ可能で、バケットに格納したドキュメント、画像、その他の非構造化データに対してセマンティック検索を実行できます。
S3のスケーラビリティと耐久性をベクトル検索と組み合わせることで、Amazon S3 Vectorsは長期的な埋め込みストレージと、他のAWS AIサービスと滑らかにつながる大規模な検索拡張生成(RAG)パイプラインの土台となります。
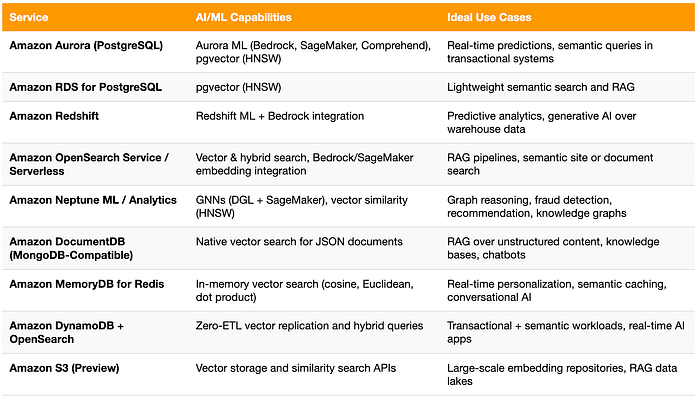
AWSデータベースのAI/ML機能比較
これだけ多くのAWSデータベースがAIやベクトル機能をサポートするようになると、それぞれの位置づけを整理しておくと役立ちます。下表は、Auroraのトランザクションインテリジェンスから、S3における大規模な埋め込みストレージまで、各サービスの主なAI/ML機能と適したユースケースをまとめたものです。
今後の展望:データとインテリジェンスの融合
AWSはデータベース、分析、AIの境界線をますます曖昧にしています。今後はAurora、Redshift、OpenSearchでのBedrock連携の深化、さらにDynamoDBやS3などへのネイティブなベクトル機能の拡大が見込まれます。
近い将来、AI対応データベースは情報を保存するだけでなく、そこから継続的に学習し、クエリを最適化し、トレンドを予測し、workloadsの傾向に自動で適応していくはずです。データとインテリジェンスが隣り合わせで存在する——この融合こそ、クラウドデータベース進化の次なるステージを示しています。
AI対応データベースはもはや構想ではなく、AWS上で現実のものとなっています。Aurora MLとpgvectorから、Redshift ML、OpenSearch、Neptune ML、DocumentDB、MemoryDBに至るまで、AWSはインテリジェントでデータドリブンなアプリケーションを構築するための統一基盤を提供しています。
これらの機能を取り入れれば、データスタックを真のインテリジェンスレイヤーへと変革し、データのある場所で予測的インサイト、セマンティック検索、リアルタイムの意思決定を支えられるようになります。
データベースアーキテクチャをAI対応にする方法を検討中の方や、AWS上でのPoCを計画中の方は、ぜひDoiTにご相談ください。100名を超えるシニアクラウドアーキテクトとデータスペシャリストで構成される当社のチームが、世界中の企業とともにインフラの刷新、パフォーマンス最適化、そしてクラウドネイティブなAIシステムの真価を引き出す支援を行っています。