Introduzione: la nuova era dei dati intelligenti
Il panorama dei dati sta vivendo una trasformazione radicale. Per decenni i database sono stati progettati per archiviare, organizzare e recuperare informazioni in modo efficiente, alimentando dietro le quinte transazioni e analytics.
Oggi, però, nell'era dell'Intelligenza Artificiale (AI) e del Machine Learning (ML), quel modello non è più sufficiente. Le applicazioni moderne richiedono sistemi capaci di comprendere, ragionare e rispondere al contesto in tempo reale. Per soddisfare questa esigenza, i database stanno evolvendo da semplici archivi passivi a veri e propri livelli di intelligenza attiva, in grado di generare insight, previsioni e raccomandazioni direttamente dove risiedono i dati.
AWS sta costruendo questa visione passo dopo passo. Grazie a innovazioni come Aurora ML, pgvector in Amazon Aurora e RDS, Amazon Redshift ML, la vector search di OpenSearch e Neptune ML, i database AWS stanno diventando davvero AI-ready.
Cosa rende un database AI-ready
Un database AI-ready è progettato per fare molto di più che archiviare dati: serve a renderli realmente utilizzabili dall'intelligenza artificiale. Pur continuando a supportare i tipi di dati nativi del motore, gestisce anche dati AI-native come i vector embedding utilizzati per la semantic search e la retrieval-augmented generation (RAG). Si collega in modo trasparente ai modelli ML per training, deployment e inferenza in tempo reale, trasformando un database tradizionale in una parte attiva del workflow AI, in cui apprendimento e previsione avvengono accanto ai dati stessi.
Le caratteristiche principali sono:
- Integrazione ML nativa: richiama i modelli ML direttamente dalle query SQL, riducendo lo spostamento dei dati e la latenza.
- Supporto ai vector embedding: archivia e interroga embedding che rappresentano il significato semantico, abilitando ricerche di similarità e sensibili al contesto.
- Streaming e real-time: si integra con servizi come Amazon Kinesis o Managed Streaming for Apache Kafka (MSK) per elaborare gli eventi nel momento in cui si verificano.
- Compute e storage elastici: scalano automaticamente per gestire training, inferenza o vector workloads man mano che i dati crescono.
- Governance e sicurezza solide: ruoli IAM, crittografia e tracciamento del data lineage garantiscono conformità e affidabilità.
Funzionalità AI e ML nei database AWS
Mentre le organizzazioni adottano AI e machine learning, i database AWS evolvono per rendere l'intelligenza una componente nativa dell'infrastruttura dati. Dall'inferenza in tempo reale alla semantic search, fino alla retrieval-augmented generation (RAG), questi sistemi vanno ormai ben oltre la tradizionale archiviazione e interrogazione.
Vediamo come i database AWS, da Aurora a S3, stiano diventando AI-ready, abilitando applicazioni che comprendono il contesto, ragionano sui dati e forniscono insight direttamente dove risiedono le informazioni.
Amazon Aurora ML (con Bedrock, SageMaker e Comprehend)
Amazon Aurora ML si integra direttamente con Amazon Bedrock, SageMaker e Comprehend, consentendo di eseguire l'inferenza ML all'interno delle istruzioni SQL.
Ad esempio, la query SQL seguente esegue l'inferenza del modello direttamente nel database:
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
Integrando Aurora ML con i servizi AI di AWS come Bedrock, SageMaker e Comprehend, può incorporare il machine learning direttamente nei propri workloads transazionali e ottenere previsioni in tempo reale, rilevamento delle anomalie e automazione intelligente, senza spostare i dati al di fuori del database.
pgvector in Amazon Aurora e Amazon RDS for PostgreSQL
Amazon supporta ora pgvector sia in Aurora PostgreSQL sia in RDS for PostgreSQL, permettendo di archiviare, indicizzare e interrogare embedding ad alta dimensionalità direttamente nel database. Gli sviluppatori possono così eseguire semantic search e query di similarità in modo nativo, senza ricorrere a vector store esterni. Con pgvector può archiviare embedding generati da Amazon Bedrock, SageMaker o altri modelli ML e utilizzare operatori come <-> per calcolare la similarità tra vettori.
Ad esempio, la query seguente recupera i cinque documenti più simili in base alla similarità vettoriale:
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
Integrando pgvector con i servizi AI di AWS, può creare applicazioni che combinano query SQL tradizionali e semantic search, abilitando casi d'uso come retrieval-augmented generation (RAG), ricerca intelligente e raccomandazioni personalizzate, il tutto all'interno del proprio ambiente Aurora o RDS PostgreSQL.
Amazon Redshift ML e integrazione con Bedrock
Amazon Redshift estende la propria potenza analitica con Redshift ML, che le permette di costruire ed eseguire modelli di machine learning direttamente in SQL, senza esportare dati né gestire un'infrastruttura ML separata. Si integra con Amazon SageMaker Autopilot per il training automatico dei modelli e ora supporta Amazon Bedrock per abilitare funzionalità di AI generativa (GenAI) come sintesi del testo, classificazione e analisi conversazionale.
Redshift ML utilizza i dati già presenti nel suo data warehouse per addestrare e ospitare modelli predittivi in SageMaker, mantenendo l'intero workflow accessibile tramite la familiare sintassi SQL. In questo modo si elimina lo spostamento dei dati, si riduce la complessità e si avvicina l'intelligenza predittiva al livello analitico.
Ad esempio, il comando seguente addestra un modello di previsione del churn dei clienti direttamente in Redshift:
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Una volta distribuito, il modello può essere richiamato all'interno di qualsiasi query per ottenere previsioni in tempo reale, esattamente come una qualsiasi altra funzione SQL.
Amazon OpenSearch Service e Serverless (Vector Search)
Amazon OpenSearch Service e OpenSearch Serverless offrono funzionalità native di vector search che uniscono comprensione semantica e ricerche per parole chiave tradizionali, abilitando casi d'uso di hybrid search (un mix di rilevanza keyword-based e vector-based) e di retrieval-augmented generation (RAG), in cui la vector search fornisce dati contestuali ai modelli di AI generativa.
Le collezioni di vector search in OpenSearch archiviano embedding, ovvero rappresentazioni vettoriali dei dati generate da Amazon Bedrock, SageMaker o altri modelli ML. Questi embedding consentono di eseguire query semantiche e basate sulla similarità che vanno oltre la corrispondenza esatta delle parole chiave. È possibile eseguire ricerche approximate nearest neighbor (ANN) per individuare documenti, prodotti o conversazioni più rilevanti per significato, e non solo per testo.
Ad esempio, la query seguente recupera i cinque documenti più simili in base alla similarità vettoriale:
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearch supporta anche query ibride, combinando rilevanza keyword-based e vector-based per risultati più contestuali. La modalità Serverless scala automaticamente i vector workloads senza richiedere la gestione del cluster, risultando ideale per applicazioni AI dinamiche o ad alto traffico. Grazie all'integrazione con Amazon Bedrock o SageMaker, può automatizzare la generazione e l'indicizzazione degli embedding, creando pipeline completamente gestite per semantic search, RAG e retrieval di contenuti personalizzati all'interno di AWS.
Amazon Neptune ML e Neptune Analytics
Amazon Neptune ML porta il machine learning nei database a grafo utilizzando la Deep Graph Library (DGL) e Amazon SageMaker per addestrare e distribuire graph neural networks (GNN) senza pipeline complesse. Apprende dalle connessioni tra i dati, e non solo dagli attributi, per prevedere relazioni, rilevare anomalie e generare raccomandazioni intelligenti.
Neptune Analytics estende queste capacità con la vector search basata sull'indicizzazione HNSW, abilitando query di similarità semantica sugli embedding del grafo. Diventa così più semplice individuare entità correlate e arricchire le pipeline di retrieval-augmented generation (RAG) con contesto graph-aware.
Insieme, Neptune ML e Neptune Analytics trasformano le tradizionali query a grafo in un ragionamento intelligente e contestuale, alimentando applicazioni come rilevamento delle frodi, sistemi di raccomandazione e knowledge graph.
Amazon DocumentDB (compatibile con MongoDB): Vector Search
Amazon DocumentDB supporta ora la vector search nativa e consente di archiviare e interrogare vector embedding direttamente all'interno dei documenti JSON. Questa funzionalità permette di combinare dati strutturati e non strutturati per abilitare semantic search, retrieval-augmented generation (RAG) e chatbot basati su AI, il tutto senza spostare i dati su un database vettoriale separato.
DocumentDB si integra in modo trasparente con Amazon Bedrock e SageMaker per la generazione degli embedding. Può archiviarli direttamente nelle proprie collezioni e utilizzare operatori di similarità vettoriale per recuperare documenti o risposte contestualmente rilevanti.
Unificando archiviazione documentale e retrieval semantico, DocumentDB semplifica la creazione di applicazioni knowledge-based, sistemi di ricerca contenuti e assistenti intelligenti in grado di operare in modo efficiente su larga scala.
Amazon MemoryDB for Redis: vector search in-memory
Amazon MemoryDB for Redis supporta ora la vector search in-memory, unendo la velocità di Redis alla scalabilità di AWS per il retrieval semantico in tempo reale. Può archiviare e interrogare embedding utilizzando metriche di similarità coseno, euclidea o dot product, una combinazione ideale per personalizzazione, raccomandazioni e semantic caching.
Funzionando interamente in memoria, MemoryDB offre latenze nell'ordine dei microsecondi nelle ricerche vettoriali. Si integra in modo trasparente con Amazon Bedrock, SageMaker e AWS Lambda tramite client Redis standard, semplificando la generazione, l'archiviazione e il recupero degli embedding su larga scala.
Tutto questo rende MemoryDB una scelta efficace per inferenza AI a bassa latenza, personalizzazione basata sulla sessione e applicazioni di chat context-aware che richiedono prestazioni di vector search istantanee.
Amazon DynamoDB + OpenSearch: Zero-ETL per i vettori
Amazon DynamoDB non archivia vettori in modo nativo, ma grazie alla sua integrazione zero-ETL con Amazon OpenSearch Service, è possibile sincronizzare automaticamente i dati strutturati con OpenSearch per eseguire query semantiche e vector-based.
Questa integrazione le consente di arricchire i record DynamoDB con embedding generati da Amazon Bedrock o SageMaker e di interrogarli in OpenSearch tramite ricerca ibrida o di similarità vettoriale, senza dover costruire pipeline personalizzate o script per lo spostamento dei dati.
Combinando la scalabilità di DynamoDB con le capacità di vector search e analytics di OpenSearch, può creare applicazioni AI in tempo reale che unificano dati transazionali e semantici. Una soluzione ideale per personalizzazione, motori di raccomandazione ed esperienze di ricerca intelligente.
Amazon S3 Vectors (Preview)
Amazon S3 Vectors introduce un nuovo modo per archiviare e cercare embedding direttamente in Amazon S3, trasformando l'object storage in un data lake vettoriale su larga scala. Attualmente in preview, consente di gestire miliardi di embedding senza dover configurare un database o un servizio di indicizzazione vettoriale separato.
Può utilizzare Amazon Bedrock, SageMaker o altri modelli ML per generare embedding e archiviarli come oggetti vettoriali in S3. Questi vettori possono poi essere interrogati tramite API di similarity search per il retrieval semantico tra documenti, immagini o altri dati non strutturati presenti nei propri bucket.
Combinando la scalabilità e la durabilità di S3 con la vector search, Amazon S3 Vectors getta le basi per l'archiviazione a lungo termine degli embedding e per pipeline di retrieval-augmented generation (RAG) su larga scala, perfettamente integrate con gli altri servizi AI di AWS.
Confronto delle capacità AI/ML nei database AWS
Con così tanti database AWS che oggi supportano funzionalità AI e vettoriali, è utile capire come si combinano tra loro. La tabella seguente riassume le principali caratteristiche AI/ML e i casi d'uso ideali di ciascun servizio, dall'intelligenza transazionale di Aurora all'archiviazione di embedding su larga scala in S3.
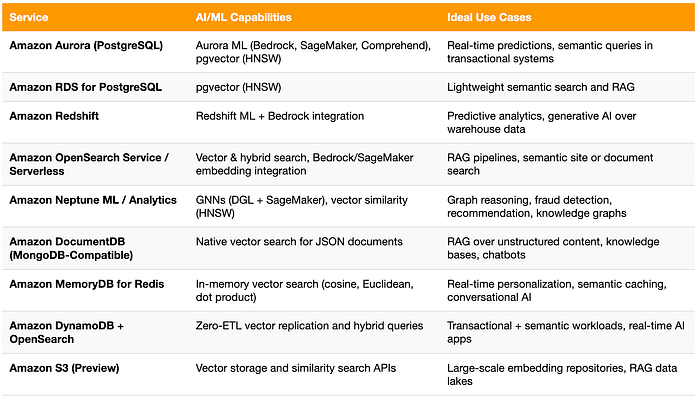
Prospettive future: la convergenza tra dati e intelligenza
AWS continua a sfumare i confini tra database, analytics e AI. Sono attese integrazioni più profonde con Bedrock in Aurora, Redshift e OpenSearch, oltre all'estensione delle capacità vettoriali native a servizi come DynamoDB e S3.
Nel prossimo futuro, i database AI-ready non si limiteranno ad archiviare informazioni: continueranno ad apprendere da esse, ottimizzando le query, anticipando i trend e adattandosi automaticamente ai pattern dei workloads. Una convergenza che segna il prossimo passo nell'evoluzione dei database cloud, dove dati e intelligenza convivono fianco a fianco.
I database AI-ready non sono più una visione, ma la nuova realtà su AWS. Da Aurora ML e pgvector a Redshift ML, OpenSearch, Neptune ML, DocumentDB e MemoryDB, AWS offre oggi una base unificata per costruire applicazioni intelligenti e data-driven.
Adottare queste capacità significa trasformare il proprio data stack in un autentico livello di intelligenza, capace di alimentare insight predittivi, semantic search e decisioni in tempo reale direttamente dove risiedono i dati.
Se sta valutando come rendere AI-ready la propria architettura database o sta pianificando un proof of concept su AWS, DoiT può aiutarla. Il nostro team di oltre 100 senior cloud architect e specialisti dei dati collabora con organizzazioni in tutto il mondo per modernizzare l'infrastruttura, ottimizzare le prestazioni e liberare il pieno potenziale dei sistemi AI cloud-native.