Introduction : la nouvelle ère de la donnée intelligente
Le paysage de la donnée connaît une mutation profonde. Pendant des décennies, les bases de données ont été conçues pour stocker, organiser et restituer la donnée efficacement, alimentant en coulisses transactions et analyses.
Mais aujourd'hui, à l'ère de l'intelligence artificielle (IA) et du machine learning (ML), ce modèle ne suffit plus. Les applications modernes exigent des systèmes capables de comprendre, de raisonner et de réagir au contexte en temps réel. Pour répondre à cette exigence, les bases de données évoluent : de simples espaces de stockage passifs, elles deviennent de véritables couches d'intelligence actives, capables de générer insights, prédictions et recommandations directement là où la donnée réside.
AWS bâtit progressivement cette vision. À travers des innovations telles qu'Aurora ML, pgvector dans Amazon Aurora et RDS, Amazon Redshift ML, la recherche vectorielle d'OpenSearch ou encore Neptune ML, ses bases de données deviennent véritablement prêtes pour l'IA.
Ce qui définit une base de données prête pour l'IA
Une base de données prête pour l'IA ne se contente pas de stocker la donnée : elle est conçue pour la rendre exploitable par l'intelligence artificielle. Tout en continuant de prendre en charge les types de données natifs du moteur, elle gère également des données AI-natives comme les vector embeddings utilisés pour la recherche sémantique et la retrieval-augmented generation (RAG). Elle se connecte nativement à des modèles ML pour l'entraînement, le déploiement et l'inférence en temps réel, transformant une base traditionnelle en composant actif du workflow IA, où apprentissage et prédiction se déroulent au plus près de la donnée.
Caractéristiques clés :
- Intégration ML native : invoquez des modèles ML directement depuis vos requêtes SQL pour limiter les déplacements de données et la latence.
- Prise en charge des vector embeddings : stockez et interrogez des embeddings porteurs de sens sémantique, pour une recherche par similarité tenant compte du contexte.
- Streaming et temps réel : branchez-vous sur des services comme Amazon Kinesis ou Managed Streaming for Apache Kafka (MSK) pour traiter les événements à mesure qu'ils surviennent.
- Compute et stockage élastiques : mise à l'échelle automatique pour absorber les workloads d'entraînement, d'inférence ou vectoriels au fil de la croissance des données.
- Gouvernance et sécurité solides : rôles IAM, chiffrement et suivi du data lineage pour garantir conformité et confiance.
Les capacités IA et ML dans l'écosystème de bases de données AWS
À mesure que les organisations adoptent l'IA et le machine learning, les bases de données AWS évoluent pour faire de l'intelligence un composant natif de l'infrastructure de données. De l'inférence en temps réel à la recherche sémantique en passant par la retrieval-augmented generation (RAG), ces systèmes vont désormais bien au-delà du simple stockage et de l'interrogation classique.
Voyons comment les bases de données AWS, d'Aurora à S3, deviennent prêtes pour l'IA et permettent de bâtir des applications qui comprennent le contexte, raisonnent sur la donnée et délivrent des insights directement là où l'information réside.
Amazon Aurora ML (avec Bedrock, SageMaker et Comprehend)
Amazon Aurora ML s'intègre directement à Amazon Bedrock, SageMaker et Comprehend, autorisant l'inférence ML au sein même des instructions SQL.
À titre d'exemple, la requête SQL suivante exécute une inférence de modèle directement dans la base :
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
En reliant Aurora ML aux services IA d'AWS comme Bedrock, SageMaker et Comprehend, vous intégrez le machine learning au cœur de vos workloads transactionnels, pour des prédictions en temps réel, de la détection d'anomalies et de l'automatisation intelligente, sans jamais sortir la donnée de la base.
pgvector dans Amazon Aurora et Amazon RDS for PostgreSQL
Amazon prend désormais en charge pgvector dans Aurora PostgreSQL comme dans RDS for PostgreSQL, vous permettant de stocker, d'indexer et d'interroger des embeddings de haute dimension directement dans la base. Les développeurs peuvent ainsi exécuter nativement des recherches sémantiques et des requêtes par similarité, sans dépendre d'un magasin vectoriel externe. Avec pgvector, vous stockez les embeddings générés par Amazon Bedrock, SageMaker ou d'autres modèles ML, et utilisez des opérateurs comme <-> pour calculer la similarité entre vecteurs.
Par exemple, la requête suivante récupère les cinq documents les plus proches selon la similarité vectorielle :
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
En associant pgvector aux services IA d'AWS, vous bâtissez des applications qui combinent requêtes SQL classiques et recherche sémantique, pour des cas d'usage tels que la retrieval-augmented generation (RAG), la recherche intelligente ou les recommandations personnalisées, le tout dans votre environnement Aurora ou RDS PostgreSQL.
Amazon Redshift ML et l'intégration Bedrock
Amazon Redshift étend sa puissance analytique avec Redshift ML, qui vous permet de construire et d'exécuter des modèles de machine learning directement en SQL, sans exporter vos données ni gérer une infrastructure ML séparée. Le service s'intègre à Amazon SageMaker Autopilot pour l'entraînement automatisé des modèles et prend désormais en charge Amazon Bedrock pour activer des capacités d'IA générative (GenAI) comme le résumé de texte, la classification ou les insights conversationnels.
Redshift ML s'appuie sur les données déjà présentes dans votre entrepôt pour entraîner et héberger des modèles prédictifs dans SageMaker, tout en conservant l'intégralité du workflow accessible via la syntaxe SQL familière. Résultat : aucun déplacement de données, moins de complexité, et l'intelligence prédictive au plus près de votre couche analytique.
Par exemple, la commande suivante entraîne un modèle de prédiction du churn client directement dans Redshift :
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Une fois déployé, le modèle s'invoque dans n'importe quelle requête pour des prédictions en temps réel, exactement comme n'importe quelle autre fonction SQL.
Amazon OpenSearch Service et Serverless (recherche vectorielle)
Amazon OpenSearch Service et OpenSearch Serverless proposent des capacités natives de recherche vectorielle qui combinent compréhension sémantique et requêtes par mots-clés traditionnelles, ouvrant la voie à la recherche hybride (mêlant pertinence par mots-clés et par vecteurs) ainsi qu'aux cas d'usage de retrieval-augmented generation (RAG), où la recherche vectorielle apporte un contexte aux modèles d'IA générative.
Les collections de recherche vectorielle d'OpenSearch stockent les embeddings, c'est-à-dire les représentations vectorielles de données générées par Amazon Bedrock, SageMaker ou d'autres modèles ML. Ces embeddings rendent possibles des requêtes sémantiques et de similarité qui dépassent la simple correspondance exacte de mots-clés. Vous pouvez ainsi exécuter des recherches approximate nearest neighbor (ANN) pour identifier les documents, produits ou conversations les plus pertinents par leur sens, et non par leur texte.
Par exemple, la requête suivante récupère les cinq documents les plus proches selon la similarité vectorielle :
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearch prend également en charge les requêtes hybrides, mêlant pertinence par mots-clés et par vecteurs pour des résultats plus contextuels. Le mode Serverless met automatiquement à l'échelle les workloads vectoriels sans gestion de cluster, ce qui le rend idéal pour les applications IA dynamiques ou à fort trafic. En vous appuyant sur Amazon Bedrock ou SageMaker, vous automatisez la génération et l'indexation d'embeddings et créez des pipelines entièrement managés pour la recherche sémantique, la RAG et la récupération de contenu personnalisé au sein d'AWS.
Amazon Neptune ML et Neptune Analytics
Amazon Neptune ML apporte le machine learning aux bases de données graphes en s'appuyant sur la Deep Graph Library (DGL) et Amazon SageMaker pour entraîner et déployer des graph neural networks (GNN) sans pipelines complexes. Le service apprend des connexions entre les données, et pas seulement de leurs attributs, pour prédire des relations, détecter des anomalies et générer des recommandations intelligentes.
Neptune Analytics étend ces capacités avec une recherche vectorielle propulsée par l'indexation HNSW, autorisant des requêtes de similarité sémantique sur les embeddings de graphes. Il devient ainsi plus simple de retrouver des entités liées et d'enrichir les pipelines de retrieval-augmented generation (RAG) avec un contexte issu du graphe.
Ensemble, Neptune ML et Neptune Analytics transforment les requêtes de graphe traditionnelles en raisonnement intelligent et contextuel, qui alimente des applications telles que la détection de fraude, les systèmes de recommandation ou les knowledge graphs.
Amazon DocumentDB (compatible MongoDB) : recherche vectorielle
Amazon DocumentDB prend désormais en charge la recherche vectorielle native, ce qui vous permet de stocker et d'interroger des vector embeddings au sein même de documents JSON. Cette capacité rend possible la combinaison de données structurées et non structurées pour activer la recherche sémantique, la retrieval-augmented generation (RAG) et les chatbots propulsés par l'IA, sans jamais déplacer la donnée vers une base vectorielle distincte.
DocumentDB s'intègre nativement à Amazon Bedrock et SageMaker pour la génération d'embeddings. Vous pouvez stocker les embeddings directement dans vos collections et utiliser des opérateurs de similarité vectorielle pour récupérer documents ou réponses contextuellement pertinents.
En unifiant stockage documentaire et récupération sémantique, DocumentDB simplifie la création d'applications fondées sur la connaissance, de systèmes de recherche de contenu et d'assistants intelligents qui fonctionnent efficacement à grande échelle.
Amazon MemoryDB for Redis : recherche vectorielle en mémoire
Amazon MemoryDB for Redis prend désormais en charge la recherche vectorielle en mémoire, alliant la rapidité de Redis à la scalabilité d'AWS pour la récupération sémantique en temps réel. Vous pouvez stocker et interroger des embeddings selon une similarité cosinus, euclidienne ou par produit scalaire, ce qui en fait un choix idéal pour la personnalisation, les recommandations et la mise en cache sémantique.
Entièrement en mémoire, MemoryDB délivre une latence de l'ordre de la microseconde pour les recherches vectorielles. Le service s'intègre à Amazon Bedrock, SageMaker et AWS Lambda via les clients Redis standard, simplifiant la génération, le stockage et la récupération d'embeddings à grande échelle.
MemoryDB s'impose ainsi comme une option puissante pour l'inférence IA à faible latence, la personnalisation par session et les applications conversationnelles contextuelles qui exigent des performances de recherche vectorielle instantanées.
Amazon DynamoDB + OpenSearch : zero-ETL pour les vecteurs
Amazon DynamoDB ne stocke pas nativement les vecteurs, mais grâce à son intégration zero-ETL avec Amazon OpenSearch Service, vous synchronisez automatiquement les données structurées vers OpenSearch pour des requêtes sémantiques et vectorielles.
Cette intégration permet d'enrichir les enregistrements DynamoDB avec des embeddings générés par Amazon Bedrock ou SageMaker, puis de les interroger dans OpenSearch via une recherche hybride ou par similarité vectorielle, sans construire de pipelines sur mesure ni de scripts de déplacement de données.
En combinant la scalabilité de DynamoDB aux capacités de recherche vectorielle et d'analyse d'OpenSearch, vous bâtissez des applications temps réel propulsées par l'IA qui unifient données transactionnelles et sémantiques. Une combinaison idéale pour la personnalisation, les moteurs de recommandation et les expériences de recherche intelligente.
Amazon S3 Vectors (Preview)
Amazon S3 Vectors introduit une nouvelle façon de stocker et de rechercher des embeddings directement dans Amazon S3, transformant le stockage objet en un data lake vectoriel à grande échelle. Actuellement en preview, le service permet de gérer des milliards d'embeddings sans déployer de base ou d'index vectoriel distinct.
Vous pouvez utiliser Amazon Bedrock, SageMaker ou d'autres modèles ML pour générer des embeddings et les stocker comme objets vectoriels dans S3. Ces vecteurs s'interrogent ensuite via des API de recherche par similarité pour la récupération sémantique de documents, d'images ou d'autres données non structurées présentes dans vos buckets.
En combinant la scalabilité et la durabilité de S3 à la recherche vectorielle, Amazon S3 Vectors pose les fondations d'un stockage d'embeddings à long terme et de pipelines de retrieval-augmented generation (RAG) à grande échelle qui s'intègrent nativement aux autres services IA d'AWS.
Comparaison des capacités IA/ML dans les bases de données AWS
Avec autant de bases AWS prenant désormais en charge les capacités IA et vectorielles, il est utile de voir comment elles s'articulent. Le tableau ci-dessous résume les principales fonctionnalités IA/ML et les cas d'usage idéaux de chaque service, de l'intelligence transactionnelle dans Aurora au stockage d'embeddings à grande échelle dans S3.
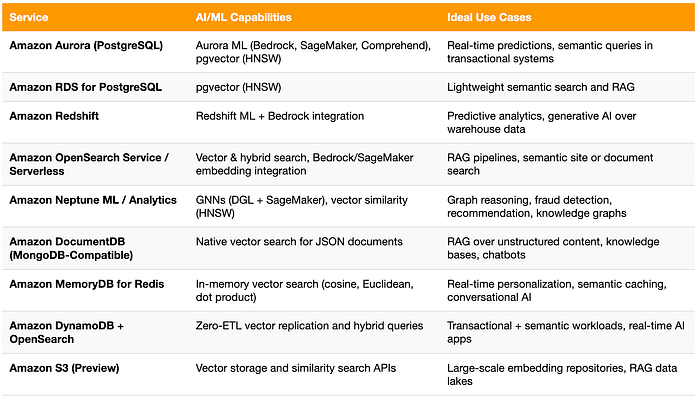
Perspectives : quand donnée et intelligence convergent
AWS continue d'estomper les frontières entre bases de données, analytique et IA. Attendez-vous à des intégrations Bedrock plus poussées dans Aurora, Redshift et OpenSearch, ainsi qu'à l'extension des capacités vectorielles natives à des services comme DynamoDB et S3.
À court terme, les bases de données prêtes pour l'IA ne se contenteront plus de stocker l'information : elles apprendront en continu, optimiseront les requêtes, anticiperont les tendances et s'adapteront automatiquement aux profils de workloads. Cette convergence marque la prochaine étape dans l'évolution des bases de données cloud, où donnée et intelligence cohabitent.
Les bases de données prêtes pour l'IA ne sont plus une vision : elles sont la nouvelle réalité sur AWS. D'Aurora ML et pgvector à Redshift ML, OpenSearch, Neptune ML, DocumentDB et MemoryDB, AWS offre désormais une fondation unifiée pour bâtir des applications intelligentes et data-driven.
Adopter ces capacités, c'est transformer votre stack de données en véritable couche d'intelligence, qui propulse insights prédictifs, recherche sémantique et prise de décision en temps réel directement là où réside votre donnée.
Si vous cherchez à rendre votre architecture de bases de données prête pour l'IA ou à lancer un proof of concept sur AWS, DoiT peut vous accompagner. Notre équipe de plus de 100 architectes cloud seniors et spécialistes de la donnée collabore avec des organisations du monde entier pour moderniser leur infrastructure, optimiser les performances et libérer tout le potentiel des systèmes IA cloud-native.