Einleitung: Die neue Ära intelligenter Daten
Die Datenlandschaft steht vor einem grundlegenden Wandel. Jahrzehntelang waren Datenbanken darauf ausgelegt, Daten effizient zu speichern, zu organisieren und abzurufen — und so im Hintergrund Transaktionen und Analysen zu ermöglichen.
Im Zeitalter von Artificial Intelligence (AI) und Machine Learning (ML) reicht dieses Modell jedoch nicht mehr aus. Moderne Anwendungen verlangen Systeme, die Kontext in Echtzeit verstehen, daraus schlussfolgern und entsprechend reagieren. Um diesem Anspruch gerecht zu werden, entwickeln sich Datenbanken von passiven Datenspeichern zu aktiven Intelligenz-Layern, die Erkenntnisse, Vorhersagen und Empfehlungen direkt dort liefern, wo die Daten liegen.
AWS arbeitet konsequent auf diese Vision hin. Mit Innovationen wie Aurora ML, pgvector in Amazon Aurora und RDS, Amazon Redshift ML, OpenSearch Vector Search und Neptune ML werden AWS-Datenbanken wirklich AI-ready.
Was eine Datenbank AI-ready macht
Eine AI-ready-Datenbank ist mehr als ein reiner Datenspeicher. Sie ist darauf ausgelegt, Daten für Künstliche Intelligenz nutzbar zu machen. Sie unterstützt weiterhin die nativen Datentypen der Datenbank-Engine, kann aber auch AI-native Daten wie Vector Embeddings verarbeiten, die für semantische Suche und Retrieval-Augmented Generation (RAG) zum Einsatz kommen. Sie bindet sich nahtlos an ML-Modelle für Training, Deployment und Echtzeit-Inferenz an und macht aus einer klassischen Datenbank einen aktiven Bestandteil des AI-Workflows — Lernen und Vorhersagen finden direkt am Ort der Daten statt.
Zentrale Merkmale:
- Native ML-Integration: ML-Modelle direkt aus SQL-Abfragen aufrufen, um Datenbewegungen und Latenz zu reduzieren.
- Unterstützung für Vector Embeddings: Embeddings speichern und abfragen, die semantische Bedeutung repräsentieren — für Ähnlichkeits- und kontextbezogene Suche.
- Streaming- und Echtzeitfähigkeit: Integration mit Diensten wie Amazon Kinesis oder Managed Streaming for Apache Kafka (MSK), um Events in dem Moment zu verarbeiten, in dem sie entstehen.
- Elastische Compute- und Storage-Ressourcen: Automatische Skalierung für Training, Inferenz oder Vector-Workloads, wenn die Datenmengen wachsen.
- Robuste Governance und Sicherheit: IAM-Rollen, Verschlüsselung und Data-Lineage-Tracking sorgen für Compliance und Vertrauen.
AI- und ML-Funktionen in AWS-Datenbanken
Während Unternehmen AI und Machine Learning in den Mittelpunkt rücken, entwickeln sich AWS-Datenbanken weiter und machen Intelligenz zum nativen Bestandteil der Dateninfrastruktur. Von Echtzeit-Inferenz über semantische Suche bis hin zu Retrieval-Augmented Generation (RAG) — diese Systeme gehen längst über klassisches Speichern und Abfragen hinaus.
Sehen wir uns an, wie AWS-Datenbanken — von Aurora bis S3 — AI-ready werden und Anwendungen ermöglichen, die Kontext verstehen, über Daten schlussfolgern und Insights direkt dort liefern, wo die Informationen liegen.
Amazon Aurora ML (mit Bedrock, SageMaker und Comprehend)
Amazon Aurora ML lässt sich direkt mit Amazon Bedrock, SageMaker und Comprehend verbinden und ermöglicht ML-Inferenz innerhalb von SQL-Statements.
Die folgende SQL-Abfrage führt beispielsweise eine Modell-Inferenz direkt in der Datenbank aus:
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
Durch die Integration von Aurora ML mit AWS-AI-Services wie Bedrock, SageMaker und Comprehend betten Sie Machine Learning direkt in Ihre transaktionalen Workloads ein — und realisieren Echtzeit-Vorhersagen, Anomalieerkennung und intelligente Automatisierung, ohne Daten aus der Datenbank verschieben zu müssen.
pgvector in Amazon Aurora & Amazon RDS for PostgreSQL
Amazon unterstützt pgvector jetzt sowohl in Aurora PostgreSQL als auch in RDS for PostgreSQL. So lassen sich hochdimensionale Embeddings direkt in der Datenbank speichern, indizieren und abfragen. Engineers können semantische Suche und Ähnlichkeitsabfragen nativ ausführen, ohne auf externe Vector Stores angewiesen zu sein. Mit pgvector speichern Sie Embeddings aus Amazon Bedrock, SageMaker oder anderen ML-Modellen und prüfen sie mit Operatoren wie <-> auf Ähnlichkeit.
Die folgende Abfrage liefert beispielsweise die fünf ähnlichsten Dokumente auf Basis der Vector-Ähnlichkeit:
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
Über die Integration von pgvector mit AWS-AI-Services bauen Sie Anwendungen, die klassische SQL-Abfragen mit semantischer Suche kombinieren — und damit Use Cases wie Retrieval-Augmented Generation (RAG), intelligente Suche und personalisierte Empfehlungen direkt in Ihrer Aurora- oder RDS-PostgreSQL-Umgebung umsetzen.
Amazon Redshift ML und Bedrock-Integration
Amazon Redshift erweitert seine analytische Stärke mit Redshift ML und ermöglicht es, Machine-Learning-Modelle direkt in SQL zu erstellen und auszuführen — ganz ohne Datenexport oder separate ML-Infrastruktur. Redshift ML lässt sich mit Amazon SageMaker Autopilot für automatisiertes Modelltraining verbinden und unterstützt nun auch Amazon Bedrock, um Generative-AI-(GenAI)-Funktionen wie Textzusammenfassung, Klassifikation und Conversational Insights bereitzustellen.
Redshift ML nutzt Daten, die bereits in Ihrem Warehouse liegen, um prädiktive Modelle in SageMaker zu trainieren und zu hosten — und das alles über vertraute SQL-Syntax. Das vermeidet Datenbewegungen, reduziert Komplexität und bringt prädiktive Intelligenz näher an Ihren Analyse-Layer.
Der folgende Befehl trainiert beispielsweise ein Modell zur Vorhersage der Kundenabwanderung direkt in Redshift:
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Nach dem Deployment rufen Sie das Modell in jeder Abfrage für Echtzeit-Vorhersagen auf — wie jede andere SQL-Funktion.
Amazon OpenSearch Service & Serverless (Vector Search)
Amazon OpenSearch Service und OpenSearch Serverless bieten native Vector-Search-Funktionen, die semantisches Verständnis mit klassischen Keyword-Abfragen verbinden. Damit lassen sich Hybrid Search (eine Mischung aus Keyword- und vektorbasierter Relevanz) und Retrieval-Augmented-Generation-(RAG)-Use-Cases umsetzen, bei denen Vector Search kontextuelle Daten an generative AI-Modelle liefert.
Vector-Search-Collections in OpenSearch speichern Embeddings — also Vektorrepräsentationen von Daten, die mit Amazon Bedrock, SageMaker oder anderen ML-Modellen erzeugt wurden. Diese Embeddings ermöglichen semantische und ähnlichkeitsbasierte Abfragen, die weit über exakte Keyword-Treffer hinausgehen. Mit Approximate-Nearest-Neighbor-(ANN)-Suchen finden Sie Dokumente, Produkte oder Konversationen, die inhaltlich am relevantesten sind — und nicht nur sprachlich passen.
Die folgende Abfrage liefert beispielsweise die fünf ähnlichsten Dokumente auf Basis der Vector-Ähnlichkeit:
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearch unterstützt zudem Hybrid-Abfragen, die Keyword- und vektorbasierte Relevanz für kontextreichere Ergebnisse kombinieren. Der Serverless-Modus skaliert Vector-Workloads automatisch, ganz ohne Cluster-Management — ideal für dynamische oder traffic-intensive AI-Anwendungen. Über die Integration mit Amazon Bedrock oder SageMaker automatisieren Sie Embedding-Generierung und Indexierung und bauen vollständig verwaltete Pipelines für semantische Suche, RAG und personalisierte Inhaltsabfragen innerhalb von AWS auf.
Amazon Neptune ML und Neptune Analytics
Amazon Neptune ML bringt Machine Learning in Graph-Datenbanken: Mit der Deep Graph Library (DGL) und Amazon SageMaker lassen sich Graph Neural Networks (GNNs) ohne komplexe Pipelines trainieren und bereitstellen. Neptune ML lernt aus den Verbindungen zwischen Daten — nicht nur aus deren Attributen — und kann so Beziehungen vorhersagen, Anomalien erkennen und intelligente Empfehlungen generieren.
Neptune Analytics erweitert diese Fähigkeiten um Vector Search auf Basis von HNSW-Indexierung und ermöglicht semantische Ähnlichkeitsabfragen über Graph-Embeddings. So finden Sie verwandte Entitäten leichter und reichern Retrieval-Augmented-Generation-(RAG)-Pipelines mit graphbezogenem Kontext an.
Zusammen verwandeln Neptune ML und Neptune Analytics klassische Graph-Abfragen in intelligentes, kontextbewusstes Reasoning — die Grundlage für Anwendungen wie Betrugserkennung, Empfehlungssysteme und Knowledge Graphs.
Amazon DocumentDB (MongoDB-kompatibel): Vector Search
Amazon DocumentDB unterstützt jetzt native Vector Search und ermöglicht das Speichern und Abfragen von Vector Embeddings innerhalb von JSON-Dokumenten. Damit lassen sich strukturierte und unstrukturierte Daten kombinieren, um semantische Suche, Retrieval-Augmented Generation (RAG) und AI-gestützte Chatbots umzusetzen — ohne Daten in eine separate Vector-Datenbank zu verschieben.
DocumentDB lässt sich nahtlos mit Amazon Bedrock und SageMaker für die Embedding-Generierung verbinden. Sie speichern Embeddings direkt in Ihren Collections und rufen mit Vector-Ähnlichkeitsoperatoren kontextuell relevante Dokumente oder Antworten ab.
Indem DocumentDB Dokumentenspeicherung und semantische Abfrage zusammenführt, vereinfacht es den Aufbau von Knowledge-basierten Anwendungen, Content-Search-Systemen und intelligenten Assistenten, die effizient skalieren.
Amazon MemoryDB for Redis: In-Memory Vector Search
Amazon MemoryDB for Redis unterstützt jetzt In-Memory Vector Search und kombiniert die Geschwindigkeit von Redis mit der Skalierbarkeit von AWS für semantische Abfragen in Echtzeit. Embeddings lassen sich mit Cosine-, Euclidean- oder Dot-Product-Ähnlichkeit speichern und abfragen — ideal für Personalisierung, Empfehlungen und semantisches Caching.
Da MemoryDB vollständig im Arbeitsspeicher läuft, liefert es Vector-Lookups mit Mikrosekunden-Latenz. Über Standard-Redis-Clients verbindet es sich nahtlos mit Amazon Bedrock, SageMaker und AWS Lambda — Embeddings lassen sich so im großen Maßstab generieren, speichern und abrufen.
Damit ist MemoryDB eine starke Wahl für AI-Inferenz mit niedriger Latenz, sitzungsbasierte Personalisierung und kontextbewusste Chat-Anwendungen, die sofortige Vector-Search-Performance verlangen.
Amazon DynamoDB + OpenSearch: Zero-ETL für Vektoren
Amazon DynamoDB speichert Vektoren nicht nativ — über die Zero-ETL-Integration mit Amazon OpenSearch Service synchronisieren Sie strukturierte Daten jedoch automatisch nach OpenSearch und führen dort semantische sowie vektorbasierte Abfragen aus.
Mit dieser Integration reichern Sie DynamoDB-Datensätze um Embeddings aus Amazon Bedrock oder SageMaker an und fragen sie anschließend in OpenSearch über Hybrid- oder Vector-Ähnlichkeitssuche ab — ganz ohne eigene Pipelines oder Skripte zur Datenverschiebung.
Durch die Kombination der Skalierbarkeit von DynamoDB mit den Vector-Search- und Analyse-Funktionen von OpenSearch bauen Sie AI-gestützte Echtzeitanwendungen auf, die transaktionale und semantische Daten zusammenführen. Ideal für Personalisierung, Recommendation Engines und intelligente Sucherlebnisse.
Amazon S3 Vectors (Preview)
Amazon S3 Vectors bietet einen neuen Weg, Embeddings direkt in Amazon S3 zu speichern und zu durchsuchen — und macht aus Object Storage einen Vector-Data-Lake im großen Maßstab. Aktuell als Preview verfügbar, ermöglicht der Service die Verwaltung von Milliarden Embeddings, ohne dass eine separate Vector-Datenbank oder ein Index-Service nötig wäre.
Mit Amazon Bedrock, SageMaker oder anderen ML-Modellen erzeugen Sie Embeddings und legen sie als Vektorobjekte in S3 ab. Diese Vektoren lassen sich anschließend über Similarity-Search-APIs abfragen — für semantische Abrufe über Dokumente, Bilder oder andere unstrukturierte Daten in Ihren Buckets.
Indem die Skalierbarkeit und Beständigkeit von S3 mit Vector Search kombiniert werden, legt Amazon S3 Vectors das Fundament für langfristige Embedding-Speicherung und großskalige Retrieval-Augmented-Generation-(RAG)-Pipelines, die sich nahtlos in andere AWS-AI-Services einfügen.
Vergleich der AI-/ML-Funktionen in AWS-Datenbanken
Da inzwischen so viele AWS-Datenbanken AI- und Vector-Funktionen unterstützen, lohnt ein Überblick. Die folgende Tabelle fasst die wichtigsten AI-/ML-Features und typischen Use Cases der einzelnen Services zusammen — von transaktionaler Intelligenz in Aurora bis zur großskaligen Embedding-Speicherung in S3.
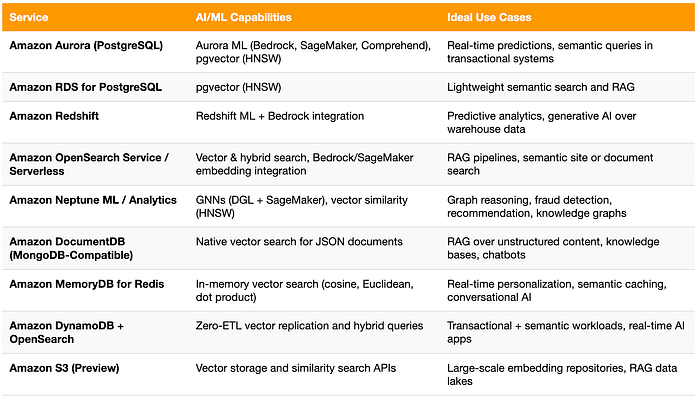
Ausblick: Wenn Daten und Intelligenz zusammenwachsen
AWS lässt die Grenzen zwischen Datenbanken, Analytics und AI weiter verschwimmen. Rechnen Sie mit tieferen Bedrock-Integrationen in Aurora, Redshift und OpenSearch sowie mit nativen Vector-Funktionen, die sich auf Services wie DynamoDB und S3 ausweiten.
In naher Zukunft werden AI-ready-Datenbanken Informationen nicht nur speichern, sondern kontinuierlich daraus lernen — Abfragen optimieren, Trends vorhersagen und sich automatisch an Workload-Muster anpassen. Diese Konvergenz markiert den nächsten Schritt in der Evolution von Cloud-Datenbanken: Daten und Intelligenz Seite an Seite.
AI-ready-Datenbanken sind keine Vision mehr — sie sind die neue Realität auf AWS. Von Aurora ML und pgvector über Redshift ML, OpenSearch, Neptune ML bis hin zu DocumentDB und MemoryDB bietet AWS heute eine einheitliche Grundlage, um intelligente, datengetriebene Anwendungen zu bauen.
Wer diese Funktionen nutzt, verwandelt seinen Data Stack in einen echten Intelligenz-Layer — mit prädiktiven Insights, semantischer Suche und Echtzeit-Entscheidungen direkt dort, wo die Daten liegen.
Wenn Sie ausloten möchten, wie Sie Ihre Datenbankarchitektur AI-ready machen, oder einen Proof of Concept auf AWS planen, unterstützt Sie DoiT. Unser Team aus über 100 Senior Cloud Architects und Data Specialists arbeitet weltweit mit Unternehmen daran, Infrastruktur zu modernisieren, Performance zu optimieren und das volle Potenzial cloud-native AI-Systeme zu erschließen.