Introducción: la nueva era de los datos inteligentes
El panorama de los datos está atravesando un cambio profundo. Durante décadas, las bases de datos se diseñaron para almacenar, organizar y recuperar datos de forma eficiente, dando vida a transacciones y analítica tras bambalinas.
Pero hoy, en plena era de la Inteligencia Artificial (IA) y el Machine Learning (ML), ese modelo se queda corto. Las aplicaciones modernas exigen sistemas que entiendan, razonen y respondan al contexto en tiempo real. Para responder a esa demanda, las bases de datos están evolucionando: dejan de ser simples repositorios pasivos para convertirse en capas activas de inteligencia, capaces de producir insights, predicciones y recomendaciones justo donde residen los datos.
AWS ha venido construyendo esta visión de forma constante. Con innovaciones como Aurora ML, pgvector en Amazon Aurora y RDS, Amazon Redshift ML, la búsqueda vectorial de OpenSearch y Neptune ML, las bases de datos de AWS ya son verdaderamente AI-ready.
Qué hace que una base de datos esté lista para la IA
Una base de datos lista para la IA está pensada para mucho más que almacenar datos: está diseñada para que esos datos sean aprovechables por la inteligencia artificial. Aunque sigue soportando los tipos de datos nativos del motor, también gestiona datos AI-native como los vector embeddings que se usan en búsqueda semántica y retrieval-augmented generation (RAG). Se conecta sin fricciones con modelos de ML para entrenamiento, despliegue e inferencia en tiempo real, convirtiendo a la base de datos tradicional en una pieza activa del flujo de IA, donde el aprendizaje y la predicción ocurren junto a los propios datos.
Sus características clave incluyen:
- Integración nativa con ML: invocar modelos de ML directamente desde consultas SQL para reducir el movimiento de datos y la latencia.
- Soporte para vector embeddings: almacenar y consultar embeddings que representan significado semántico, habilitando búsquedas por similitud y sensibles al contexto.
- Capacidad de streaming y tiempo real: integración con servicios como Amazon Kinesis o Managed Streaming for Apache Kafka (MSK) para procesar eventos en el momento en que ocurren.
- Cómputo y almacenamiento elásticos: escalado automático para soportar workloads de entrenamiento, inferencia o vectores a medida que crecen los datos.
- Gobernanza y seguridad sólidas: aplicación de roles IAM, cifrado y trazabilidad del linaje de datos para mantener el cumplimiento y la confianza.
Capacidades de IA y ML en las bases de datos de AWS
A medida que las organizaciones adoptan la IA y el machine learning, las bases de datos de AWS evolucionan para que la inteligencia sea parte nativa de la infraestructura de datos. Desde la inferencia en tiempo real hasta la búsqueda semántica y la retrieval-augmented generation (RAG), estos sistemas van mucho más allá del almacenamiento y la consulta tradicionales.
Veamos cómo las bases de datos de AWS, desde Aurora hasta S3, se vuelven AI-ready y dan vida a aplicaciones que entienden el contexto, razonan sobre los datos y entregan insights directamente donde vive la información.
Amazon Aurora ML (con Bedrock, SageMaker y Comprehend)
Amazon Aurora ML se integra directamente con Amazon Bedrock, SageMaker y Comprehend, lo que permite ejecutar inferencia de ML desde sentencias SQL.
Por ejemplo, la siguiente consulta SQL ejecuta la inferencia del modelo directamente dentro de la base de datos:
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
Al integrar Aurora ML con servicios de IA de AWS como Bedrock, SageMaker y Comprehend, puedes incorporar machine learning directamente en tus workloads transaccionales, habilitando predicciones en tiempo real, detección de anomalías y automatización inteligente sin sacar los datos fuera de la base de datos.
pgvector en Amazon Aurora y Amazon RDS for PostgreSQL
Amazon ya soporta pgvector tanto en Aurora PostgreSQL como en RDS for PostgreSQL, lo que te permite almacenar, indexar y consultar embeddings de alta dimensionalidad directamente dentro de la base de datos. Así, los desarrolladores pueden ejecutar búsquedas semánticas y consultas por similitud de forma nativa, sin depender de almacenes de vectores externos. Con pgvector puedes guardar embeddings generados desde Amazon Bedrock, SageMaker u otros modelos de ML, y usar operadores como <-> para calcular la similitud entre vectores.
Por ejemplo, la siguiente consulta recupera los cinco documentos más similares según la similitud vectorial:
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
Al integrar pgvector con los servicios de IA de AWS puedes construir aplicaciones que combinan consultas SQL tradicionales con búsqueda semántica, dando vida a casos de uso como retrieval-augmented generation (RAG), búsqueda inteligente y recomendaciones personalizadas, todo dentro de tu entorno Aurora o RDS PostgreSQL.
Amazon Redshift ML e integración con Bedrock
Amazon Redshift amplía su capacidad analítica con Redshift ML, que permite construir y ejecutar modelos de machine learning directamente en SQL, sin exportar datos ni administrar infraestructura de ML por separado. Se integra con Amazon SageMaker Autopilot para el entrenamiento automatizado de modelos y ahora soporta Amazon Bedrock para sumar capacidades de IA generativa (GenAI) como resumen de texto, clasificación e insights conversacionales.
Redshift ML aprovecha los datos que ya tienes en tu warehouse para entrenar y hospedar modelos predictivos en SageMaker, manteniendo todo el flujo accesible mediante la sintaxis SQL de siempre. Así se elimina el movimiento de datos, se reduce la complejidad y la inteligencia predictiva queda más cerca de tu capa analítica.
Por ejemplo, el siguiente comando entrena un modelo de predicción de churn de clientes directamente en Redshift:
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Una vez desplegado, puedes invocar el modelo dentro de cualquier consulta para obtener predicciones en tiempo real, igual que con cualquier otra función SQL.
Amazon OpenSearch Service y Serverless (búsqueda vectorial)
Amazon OpenSearch Service y OpenSearch Serverless ofrecen capacidades nativas de búsqueda vectorial que combinan la comprensión semántica con las consultas tradicionales por palabras clave. Esto habilita casos de uso de búsqueda híbrida (una mezcla de relevancia por keywords y por vectores) y retrieval-augmented generation (RAG), donde la búsqueda vectorial aporta contexto a los modelos de IA generativa.
Las colecciones de búsqueda vectorial en OpenSearch almacenan embeddings, es decir, representaciones vectoriales de datos generadas por Amazon Bedrock, SageMaker u otros modelos de ML. Con esos embeddings se pueden ejecutar consultas semánticas y por similitud que van más allá de las coincidencias exactas de palabras clave. También puedes ejecutar búsquedas approximate nearest neighbor (ANN) para encontrar documentos, productos o conversaciones que sean más relevantes en significado, no solo en texto.
Por ejemplo, la siguiente consulta recupera los cinco documentos más similares según la similitud vectorial:
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
OpenSearch también admite consultas híbridas, mezclando relevancia por keywords y por vectores para obtener resultados más contextuales. El modo Serverless escala automáticamente los workloads vectoriales sin necesidad de administrar clústeres, lo que lo vuelve ideal para aplicaciones de IA dinámicas o con alto tráfico. Al integrarse con Amazon Bedrock o SageMaker, puedes automatizar la generación e indexación de embeddings y crear pipelines totalmente gestionados para búsqueda semántica, RAG y recuperación de contenido personalizado dentro de AWS.
Amazon Neptune ML y Neptune Analytics
Amazon Neptune ML lleva el machine learning a las bases de datos de grafos usando la Deep Graph Library (DGL) y Amazon SageMaker para entrenar y desplegar graph neural networks (GNNs) sin pipelines complejos. Aprende de las conexiones entre los datos, no solo de los atributos, para predecir relaciones, detectar anomalías y proponer recomendaciones inteligentes.
Neptune Analytics amplía estas capacidades con búsqueda vectorial impulsada por indexación HNSW, lo que habilita consultas de similitud semántica sobre embeddings de grafos. Esto facilita encontrar entidades relacionadas y enriquecer los pipelines de retrieval-augmented generation (RAG) con contexto basado en el grafo.
En conjunto, Neptune ML y Neptune Analytics transforman las consultas tradicionales de grafos en un razonamiento inteligente y sensible al contexto, que da vida a aplicaciones como detección de fraude, sistemas de recomendación y grafos de conocimiento.
Amazon DocumentDB (compatible con MongoDB): búsqueda vectorial
Amazon DocumentDB ya admite búsqueda vectorial nativa, lo que permite almacenar y consultar vector embeddings dentro de documentos JSON. Esta capacidad permite combinar datos estructurados y no estructurados para habilitar búsqueda semántica, retrieval-augmented generation (RAG) y chatbots impulsados por IA, todo sin mover los datos a una base de datos vectorial aparte.
DocumentDB se integra sin fricciones con Amazon Bedrock y SageMaker para la generación de embeddings. Puedes almacenar embeddings directamente en tus colecciones y usar operadores de similitud vectorial para recuperar documentos o respuestas contextualmente relevantes.
Al unificar el almacenamiento de documentos y la recuperación semántica, DocumentDB simplifica la creación de aplicaciones basadas en conocimiento, sistemas de búsqueda de contenido y asistentes inteligentes que operan con eficiencia a escala.
Amazon MemoryDB for Redis: búsqueda vectorial en memoria
Amazon MemoryDB for Redis ya soporta búsqueda vectorial en memoria, combinando la velocidad de Redis con la escalabilidad de AWS para una recuperación semántica en tiempo real. Puedes almacenar y consultar embeddings con similitud por coseno, euclídea o producto punto, lo que lo hace ideal para personalización, recomendaciones y caché semántica.
Al ejecutarse íntegramente en memoria, MemoryDB ofrece latencia de microsegundos para búsquedas vectoriales. Se integra sin fricciones con Amazon Bedrock, SageMaker y AWS Lambda a través de clientes Redis estándar, lo que facilita generar, almacenar y recuperar embeddings a escala.
Esto convierte a MemoryDB en una opción potente para inferencia de IA de baja latencia, personalización por sesión y aplicaciones de chat sensibles al contexto que exigen un rendimiento instantáneo en búsqueda vectorial.
Amazon DynamoDB + OpenSearch: zero-ETL para vectores
Amazon DynamoDB no almacena vectores de forma nativa, pero gracias a su integración zero-ETL con Amazon OpenSearch Service, puedes sincronizar automáticamente datos estructurados hacia OpenSearch para realizar consultas semánticas y vectoriales.
Esta integración te permite enriquecer los registros de DynamoDB con embeddings generados desde Amazon Bedrock o SageMaker, y luego consultarlos en OpenSearch mediante búsqueda híbrida o por similitud vectorial, todo sin construir pipelines personalizados ni scripts de movimiento de datos.
Al combinar la escalabilidad de DynamoDB con las capacidades de búsqueda vectorial y analítica de OpenSearch, puedes construir aplicaciones impulsadas por IA en tiempo real que unifican datos transaccionales y semánticos. Una opción ideal para personalización, motores de recomendación y experiencias de búsqueda inteligente.
Amazon S3 Vectors (Preview)
Amazon S3 Vectors estrena una nueva forma de almacenar y buscar embeddings directamente en Amazon S3, transformando el almacenamiento de objetos en un data lake vectorial a gran escala. Por ahora en preview, te permite gestionar miles de millones de embeddings sin levantar una base de datos o servicio de índice vectorial aparte.
Puedes usar Amazon Bedrock, SageMaker u otros modelos de ML para generar embeddings y almacenarlos como objetos vectoriales en S3. Esos vectores luego se pueden consultar mediante APIs de búsqueda por similitud para recuperación semántica entre documentos, imágenes u otros datos no estructurados que tengas en tus buckets.
Al combinar la escalabilidad y durabilidad de S3 con la búsqueda vectorial, Amazon S3 Vectors sienta las bases del almacenamiento de embeddings a largo plazo y de pipelines de retrieval-augmented generation (RAG) a gran escala que se integran sin fricciones con otros servicios de IA de AWS.
Comparación de capacidades de IA/ML en las bases de datos de AWS
Con tantas bases de datos de AWS soportando ya capacidades de IA y vectoriales, conviene ver cómo encajan entre sí. La siguiente tabla resume las principales funciones de IA/ML y los casos de uso ideales de cada servicio, desde la inteligencia transaccional en Aurora hasta el almacenamiento de embeddings a gran escala en S3.
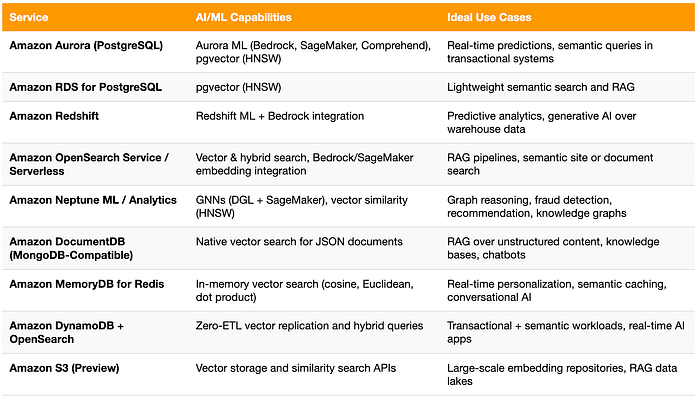
Mirada al futuro: la convergencia entre datos e inteligencia
AWS sigue difuminando las fronteras entre bases de datos, analítica e IA. Se vienen integraciones más profundas con Bedrock en Aurora, Redshift y OpenSearch, además de capacidades vectoriales nativas que se extenderán a servicios como DynamoDB y S3.
En un futuro cercano, las bases de datos AI-ready no solo guardarán información: aprenderán continuamente de ella, optimizando consultas, anticipando tendencias y adaptándose por sí solas a los patrones de los workloads. Esta convergencia marca el siguiente paso en la evolución de las bases de datos en la nube, donde los datos y la inteligencia conviven lado a lado.
Las bases de datos AI-ready ya no son una visión: son la nueva realidad en AWS. Desde Aurora ML y pgvector hasta Redshift ML, OpenSearch, Neptune ML, DocumentDB y MemoryDB, AWS ofrece hoy una base unificada para construir aplicaciones inteligentes y guiadas por datos.
Adoptar estas capacidades puede transformar tu stack de datos en una verdadera capa de inteligencia, que entrega insights predictivos, búsqueda semántica y toma de decisiones en tiempo real, justo donde residen tus datos.
Si estás explorando cómo preparar tu arquitectura de bases de datos para la IA o planeando una prueba de concepto en AWS, DoiT puede ayudarte. Nuestro equipo de más de 100 arquitectos sénior de nube y especialistas en datos trabaja codo a codo con organizaciones de todo el mundo para modernizar la infraestructura, optimizar el rendimiento y aprovechar todo el potencial de los sistemas de IA nativos de la nube.