Introdução: a nova era dos dados inteligentes
O cenário de dados está passando por uma transformação profunda. Por décadas, os bancos de dados foram projetados para armazenar, organizar e recuperar informações com eficiência — sustentando transações e análises nos bastidores.
Mas hoje, na era da Inteligência Artificial (IA) e do Machine Learning (ML), esse modelo já não é suficiente. As aplicações modernas exigem sistemas que entendam, raciocinem e respondam ao contexto em tempo real. Para atender a essa demanda, os bancos de dados estão deixando de ser repositórios passivos e se tornando camadas ativas de inteligência, capazes de gerar insights, previsões e recomendações ali mesmo onde os dados estão.
A AWS vem construindo essa visão de forma consistente. Com inovações como Aurora ML, pgvector no Amazon Aurora e RDS, Amazon Redshift ML, busca vetorial no OpenSearch e Neptune ML, os bancos de dados da AWS estão se tornando, de fato, prontos para IA.
O que torna um banco de dados pronto para IA
Um banco de dados pronto para IA faz muito mais do que armazenar dados. Ele é projetado para tornar essas informações utilizáveis pela inteligência artificial. Continua dando suporte aos tipos de dados nativos do mecanismo, mas também lida com dados nativos de IA, como vector embeddings usados em busca semântica e retrieval-augmented generation (RAG). Ele se conecta de forma fluida a modelos de ML para treinamento, deploy e inferência em tempo real, transformando um banco tradicional em parte ativa do fluxo de IA, com aprendizado e predição acontecendo perto dos próprios dados.
Principais características:
- Integração nativa com ML: invoque modelos de ML diretamente em consultas SQL para reduzir movimentação de dados e latência.
- Suporte a vector embeddings: armazene e consulte embeddings que representam significado semântico, viabilizando buscas por similaridade e sensíveis ao contexto.
- Pronto para streaming e tempo real: integre com serviços como Amazon Kinesis ou Managed Streaming for Apache Kafka (MSK) para processar eventos no momento em que acontecem.
- Computação e armazenamento elásticos: escale automaticamente para atender workloads de treinamento, inferência ou vetoriais à medida que os dados crescem.
- Governança e segurança robustas: aplique perfis IAM, criptografia e rastreamento de linhagem de dados para manter a conformidade e a confiança.
Recursos de IA e ML nos bancos de dados da AWS
À medida que as empresas adotam IA e machine learning, os bancos de dados da AWS evoluem para tornar a inteligência uma parte nativa da infraestrutura de dados. Da inferência em tempo real à busca semântica e ao retrieval-augmented generation (RAG), esses sistemas vão muito além do armazenamento e das consultas tradicionais.
Vamos ver como os bancos da AWS, do Aurora ao S3, estão se tornando prontos para IA, viabilizando aplicações que entendem contexto, raciocinam sobre dados e entregam insights diretamente onde a informação está.
Amazon Aurora ML (com Bedrock, SageMaker e Comprehend)
O Amazon Aurora ML se integra diretamente ao Amazon Bedrock, ao SageMaker e ao Comprehend, permitindo executar inferência de ML dentro de instruções SQL.
Por exemplo, a consulta SQL a seguir executa a inferência do modelo direto no banco de dados:
SELECT customer_id,
ml_infer_sagemaker('loan-risk-model', income, debt, credit_score) AS risk_score
FROM loan_applications;
Ao integrar o Aurora ML aos serviços de IA da AWS — Bedrock, SageMaker e Comprehend —, você incorpora machine learning diretamente aos seus workloads transacionais, viabilizando previsões em tempo real, detecção de anomalias e automação inteligente sem precisar tirar os dados de dentro do banco.
pgvector no Amazon Aurora e Amazon RDS for PostgreSQL
A Amazon agora oferece suporte ao pgvector tanto no Aurora PostgreSQL quanto no RDS for PostgreSQL, o que permite armazenar, indexar e consultar embeddings de alta dimensão dentro do próprio banco. Com isso, os times de desenvolvimento conseguem fazer busca semântica e consultas por similaridade de forma nativa, sem depender de vector stores externos. Com o pgvector, você armazena embeddings gerados pelo Amazon Bedrock, pelo SageMaker ou por outros modelos de ML e usa operadores como <-> para calcular a similaridade entre vetores.
Por exemplo, a consulta abaixo retorna os cinco documentos mais semelhantes com base na similaridade vetorial:
SELECT id, content
FROM documents
ORDER BY embedding <-> '[0.13, 0.27, 0.42, ...]'::vector
LIMIT 5;
Ao combinar o pgvector com os serviços de IA da AWS, você cria aplicações que unem consultas SQL tradicionais e busca semântica, sustentando casos de uso como retrieval-augmented generation (RAG), busca inteligente e recomendações personalizadas — tudo dentro do seu ambiente Aurora ou RDS PostgreSQL.
Integração entre Amazon Redshift ML e Bedrock
O Amazon Redshift amplia seu poder analítico com o Redshift ML, que permite criar e executar modelos de machine learning direto em SQL, sem exportar dados nem gerenciar uma infraestrutura de ML separada. Ele se integra ao Amazon SageMaker Autopilot para o treinamento automatizado de modelos e agora também ao Amazon Bedrock, habilitando recursos de IA generativa (GenAI), como sumarização de texto, classificação e insights conversacionais.
O Redshift ML usa os dados que já estão no seu warehouse para treinar e hospedar modelos preditivos no SageMaker, mantendo todo o fluxo acessível pela sintaxe SQL de sempre. Isso elimina a movimentação de dados, reduz a complexidade e aproxima a inteligência preditiva da sua camada analítica.
Por exemplo, o comando a seguir treina um modelo de previsão de churn de clientes diretamente no Redshift:
CREATE MODEL churn_model
FROM (SELECT age, tenure, charges, churn FROM customers)
TARGET churn
FUNCTION predict_churn
IAM_ROLE 'arn:aws:iam::123456789012:role/RedshiftMLRole';
Depois do deploy, basta invocar o modelo em qualquer consulta para obter previsões em tempo real, como você faria com qualquer outra função SQL.
Amazon OpenSearch Service e Serverless (busca vetorial)
O Amazon OpenSearch Service e o OpenSearch Serverless oferecem recursos nativos de busca vetorial que combinam compreensão semântica com consultas tradicionais por palavra-chave, viabilizando casos de uso de busca híbrida (uma mistura de relevância por palavra-chave e vetorial) e de retrieval-augmented generation (RAG), em que a busca vetorial fornece dados contextuais aos modelos de IA generativa.
As coleções de busca vetorial no OpenSearch armazenam embeddings — representações vetoriais de dados geradas pelo Amazon Bedrock, pelo SageMaker ou por outros modelos de ML. Esses embeddings permitem rodar consultas semânticas e por similaridade, indo além da correspondência exata de palavras-chave. Você pode executar buscas por vizinhos mais próximos aproximados (ANN) para encontrar documentos, produtos ou conversas mais relevantes em significado, e não apenas em texto.
Por exemplo, a consulta abaixo retorna os cinco documentos mais semelhantes com base na similaridade vetorial:
POST /my-index/_search
{
"query": {
"knn": {
"embedding": {
"vector": [0.25, 0.11, 0.78, ...],
"k": 5
}
}
}
}
O OpenSearch também aceita consultas híbridas, combinando relevância por palavra-chave e vetorial para resultados mais contextuais. O modo Serverless escala automaticamente os workloads vetoriais sem que você precise gerenciar clusters, o que o torna ideal para aplicações de IA dinâmicas ou de alto tráfego. Integrando com o Amazon Bedrock ou o SageMaker, você automatiza a geração e a indexação de embeddings, criando pipelines totalmente gerenciados para busca semântica, RAG e recuperação de conteúdo personalizado dentro da AWS.
Amazon Neptune ML e Neptune Analytics
O Amazon Neptune ML leva machine learning aos bancos de dados em grafo usando a Deep Graph Library (DGL) e o Amazon SageMaker para treinar e implantar graph neural networks (GNNs) sem pipelines complexos. Ele aprende com as conexões entre os dados, e não só com seus atributos, para prever relacionamentos, detectar anomalias e gerar recomendações inteligentes.
O Neptune Analytics amplia essas capacidades com busca vetorial apoiada por indexação HNSW, possibilitando consultas de similaridade semântica entre embeddings de grafo. Isso facilita encontrar entidades relacionadas e enriquecer pipelines de retrieval-augmented generation (RAG) com contexto orientado a grafo.
Juntos, Neptune ML e Neptune Analytics transformam consultas tradicionais em grafo em raciocínio inteligente e contextual, sustentando aplicações como detecção de fraude, sistemas de recomendação e knowledge graphs.
Amazon DocumentDB (compatível com MongoDB): busca vetorial
O Amazon DocumentDB agora oferece suporte a busca vetorial nativa, permitindo armazenar e consultar vector embeddings dentro de documentos JSON. Com isso, dá para combinar dados estruturados e não estruturados para habilitar busca semântica, retrieval-augmented generation (RAG) e chatbots com IA — sem precisar mover dados para um banco vetorial à parte.
O DocumentDB se integra de forma fluida ao Amazon Bedrock e ao SageMaker para a geração de embeddings. Você pode armazenar os embeddings diretamente nas suas coleções e usar operadores de similaridade vetorial para recuperar documentos ou respostas contextualmente relevantes.
Ao unificar o armazenamento de documentos e a recuperação semântica, o DocumentDB simplifica a construção de aplicações baseadas em conhecimento, sistemas de busca de conteúdo e assistentes inteligentes que operam com eficiência em escala.
Amazon MemoryDB for Redis: busca vetorial em memória
O Amazon MemoryDB for Redis agora oferece suporte a busca vetorial em memória, combinando a velocidade do Redis com a escalabilidade da AWS para recuperação semântica em tempo real. Você pode armazenar e consultar embeddings usando similaridade por cosseno, euclidiana ou produto escalar, o que o torna ideal para personalização, recomendações e cache semântico.
Operando inteiramente em memória, o MemoryDB entrega latência em microssegundos para buscas vetoriais. A integração com o Amazon Bedrock, o SageMaker e o AWS Lambda acontece de forma fluida pelos clientes Redis padrão, facilitando gerar, armazenar e recuperar embeddings em escala.
Tudo isso torna o MemoryDB uma escolha poderosa para inferência de IA com baixa latência, personalização baseada em sessão e aplicações de chat com contexto que exigem desempenho instantâneo de busca vetorial.
Amazon DynamoDB + OpenSearch: zero-ETL para vetores
O Amazon DynamoDB não armazena vetores nativamente, mas, por meio da sua integração zero-ETL com o Amazon OpenSearch Service, você consegue sincronizar automaticamente dados estruturados com o OpenSearch para consultas semânticas e baseadas em vetores.
Essa integração permite enriquecer registros do DynamoDB com embeddings gerados pelo Amazon Bedrock ou pelo SageMaker e, na sequência, consultá-los no OpenSearch via busca híbrida ou por similaridade vetorial — tudo isso sem precisar criar pipelines personalizados ou scripts de movimentação de dados.
Combinando a escalabilidade do DynamoDB com os recursos de busca vetorial e analytics do OpenSearch, você cria aplicações em tempo real, com IA, que unificam dados transacionais e semânticos. É a combinação ideal para personalização, motores de recomendação e experiências de busca inteligente.
Amazon S3 Vectors (Preview)
O Amazon S3 Vectors traz uma nova forma de armazenar e pesquisar embeddings diretamente no Amazon S3, transformando o object storage em um data lake vetorial em larga escala. Atualmente em preview, ele permite gerenciar bilhões de embeddings sem precisar provisionar um banco de dados ou serviço de índice vetorial separado.
Você pode usar o Amazon Bedrock, o SageMaker ou outros modelos de ML para gerar embeddings e armazená-los como objetos vetoriais no S3. Esses vetores podem então ser consultados por APIs de busca por similaridade para recuperação semântica em documentos, imagens ou outros dados não estruturados nos seus buckets.
Ao combinar a escalabilidade e a durabilidade do S3 com a busca vetorial, o Amazon S3 Vectors estabelece a base para o armazenamento de embeddings de longo prazo e para pipelines de retrieval-augmented generation (RAG) em larga escala, com integração fluida a outros serviços de IA da AWS.
Comparativo de recursos de IA/ML nos bancos de dados da AWS
Com tantos bancos de dados da AWS oferecendo recursos de IA e vetoriais, vale a pena entender como eles se encaixam. A tabela abaixo resume os principais recursos de IA/ML e os casos de uso ideais de cada serviço, da inteligência transacional no Aurora ao armazenamento de embeddings em larga escala no S3.
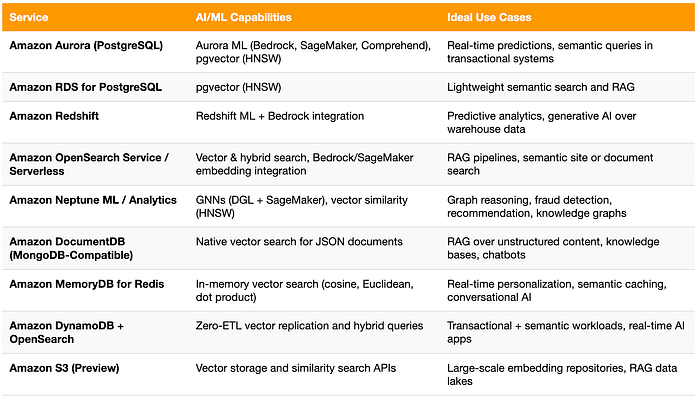
Perspectivas: a convergência entre dados e inteligência
A AWS segue dissolvendo as fronteiras entre bancos de dados, analytics e IA. Espere integrações mais profundas com o Bedrock no Aurora, no Redshift e no OpenSearch, além de recursos vetoriais nativos chegando a serviços como DynamoDB e S3.
Em um futuro próximo, os bancos de dados prontos para IA não vão apenas armazenar informação: vão aprender continuamente com ela, otimizando consultas, prevendo tendências e se adaptando aos padrões de workload de forma automática. Essa convergência marca o próximo passo na evolução dos bancos de dados em nuvem, em que dados e inteligência caminham lado a lado.
Bancos de dados prontos para IA deixaram de ser uma promessa. São a nova realidade na AWS. De Aurora ML e pgvector a Redshift ML, OpenSearch, Neptune ML, DocumentDB e MemoryDB, a AWS oferece hoje uma base unificada para construir aplicações inteligentes e orientadas a dados.
Adotar esses recursos pode transformar seu data stack em uma verdadeira camada de inteligência, sustentando insights preditivos, busca semântica e tomada de decisão em tempo real ali mesmo onde seus dados estão.
Se você está estudando como deixar sua arquitetura de banco de dados pronta para IA ou planejando uma prova de conceito na AWS, a DoiT pode ajudar. Nosso time de mais de 100 arquitetos de nuvem sêniores e especialistas em dados trabalha com empresas no mundo todo para modernizar a infraestrutura, otimizar a performance e liberar todo o potencial dos sistemas de IA nativos da nuvem.