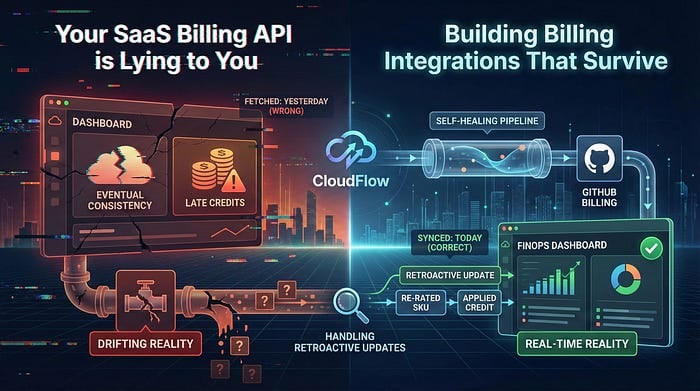
FinOpsやCloudOps向けの課金連携を構築している方に残念なお知らせです。SaaS APIから取得したばかりのそのデータ、たぶん間違っています。
バグのせいではなく、クラウド課金の仕組みそのものに原因があります。使用量の計測は結果整合であることが多く、クレジットの適用は遅れて反映され、SKUは数日後に再計算されます。連携処理が一度だけ走って昨日分のデータを取って終わり、という作りでは、FinOpsダッシュボードは日に日に現実から乖離していきます。
本記事では、実運用に耐える課金連携の作り方を解説します。
題材は、ローコードのデータオーケストレーションエンジンCloudFlowで構築したGitHub Billing連携のパターンです。課金データ取り込みで最も難しい「重複地獄を招かずに遡及的なデータ更新を扱う」という課題を解いていきます。
使用するスタックの簡単な紹介
コードに入る前に、本記事で使うツール群を簡単に押さえておきます。これらのコンポーネントになじみがなくても、アーキテクチャの考え方は堅牢なデータパイプライン全般に応用できます。
- CloudFlow: ロジックを動かすエンジンです。インフラ管理なしで高度な課金・運用ワークフローを構築できるローコードプラットフォームです。
- DataHub: データの送り先です。DoiT Cloud Intelligence™に組み込まれた統合データリポジトリで、AWS、Azure、GCP、さらにDatabricks、Snowflake、DataDogなどのカスタムソースから集めた正規化済み課金データを横並びで分析できます。
目的はシンプルです。GitHubの課金データをFinOps DataHubに取り込み、他のクラウドやSaaSの支出と並べて分析できるようにすることです。
**CloudFlowの暗黙的ベクトル化**
CloudFlowは、一般的なDAGオーケストレーターとは異なる方法で反復処理を扱います。採用しているのは暗黙的ベクトル化。あるステップが配列(たとえば日付のリスト)を出力すると、エンジンは「for-each」や「map」のような制御構造を明示しなくても、後続ノードへ自動的にファンアウトします。
これにより、パイプラインはペイロードのサイズに応じて並列度を動的にスケールし、T[]入力を並列実行スレッドとして処理します。それでいて、可視化されたグラフは線形のまま読みやすさを保てます。
GitHubをFinOpsスタックに統合するために必要なのは、これだけです。
さらにこのエンジンは、ガバナンス用途として状態を保持した一時停止もサポートします。本記事の課金連携は無人で動かしますが、副作用を伴う操作(リソースの停止など)ではHuman-in-the-Loop(HITL)による検証が求められる場面が少なくありません。
CloudFlowは特定の「承認」ノードで実行コンテキストを一時停止し、Slackからのwebhookやメールのクリックといった非同期シグナルが届くまで状態を保持。シグナルを受け取ったらパイプラインを再開できます。
問題:「不変」という嘘
多くの開発者は、課金パイプラインを次のように構築します。
- UTC 01:00に起動する。
date = yesterdayでAPIに問い合わせる。- 結果をデータウェアハウスに保存する。
これは「課金データは一度書き込まれたら不変である」という前提に立っています。しかし、現実は違います。
SaaSプロバイダーは当月の課金レコードを頻繁に更新します。12日に発生した使用量のスパイクが、15日になってようやく完全に反映されることもあります。13日に12日分のデータだけを取って終わりにしていたら、その後の更新は取りこぼしです。
これを解決するには、再ポーリングウィンドウ戦略が必要です。「昨日」を取得するのではなく、毎日「Month-to-Date(MTD、月初から当日まで)」を取り直すのです。
アーキテクチャ
毎日実行しつつ、毎回当月分すべてを再処理するフローを構築します。これにより、たとえば20日になってGitHubが月の1日分のコストを更新したとしても、確実にキャッチできます。
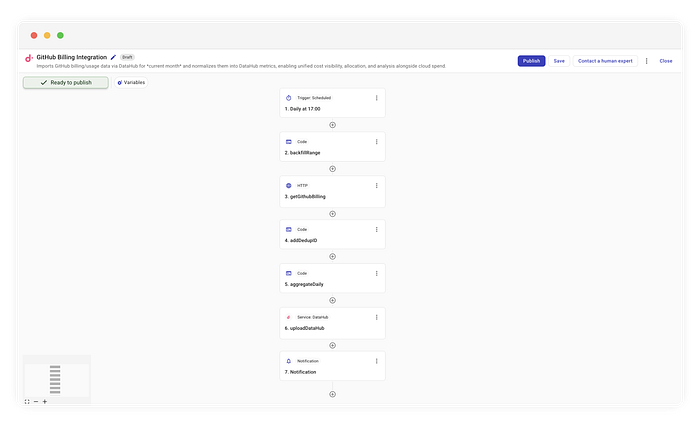
GitHub課金連携を実装した完全なフロー
CloudFlowで実装する全体ロジックは次のとおりです。
- スケジュール: 毎日午前10時(東部時間)に実行。
- ウィンドウ計算: 対象範囲を決定(1日から当日まで)。
- 取得(ファンアウト): 範囲内のすべての日についてAPIを呼び出す。
- 重複排除(ここが肝): 重複を防ぐため決定論的IDを生成。
- 取り込み: 詳細データをDataHubにUpsert。
- 通知: 別途集計し、人間が読める要約を生成。
では、ステップごとに作っていきましょう。
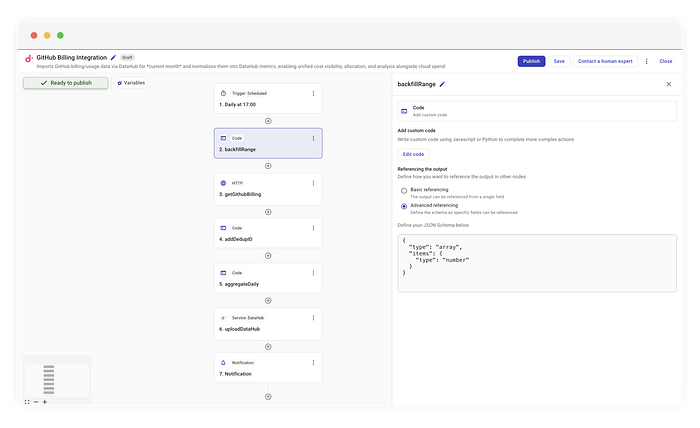
ステップ1:ローリングウィンドウ(「バックフィル」)
まずは標準的なcronトリガーで、毎日17:04に実行します。ただしAPIステップに渡すのはyesterdayではなく、backfillRangeというカスタムコードステップの結果です。
このステップは、当月のこれまでの全日付を表す配列を生成します。
処理対象の日数を抽出
// 'backfillRange'ステップの簡略化したロジック
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// 配列 [1, 2, ..., endDay] を生成
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
これが効く理由: 配列を返すことで、CloudFlowが自動的に「ファンアウト」してくれます。後続のステップは配列内の1日ごとに1回実行されます。月末30日には、このフローが30回走り、その期間の課金履歴がまるごとリフレッシュされるわけです。
出力スキーマ 後続ノードがデータを検証・自動補完できるよう、出力スキーマを定義します。このスキーマはノードが返すJSON値(たとえば文字列の配列や特定のオブジェクト)を厳密にモデル化し、CloudFlow内部の実行ラッパーやメタデータは意図的に対象外とします。トップレベルのオブジェクトや配列にぴったり一致する形で再帰的に形状を定義することで、パイプラインの後続部分が期待どおりの値を確実に受け取れる、型安全な「契約」が成立します。
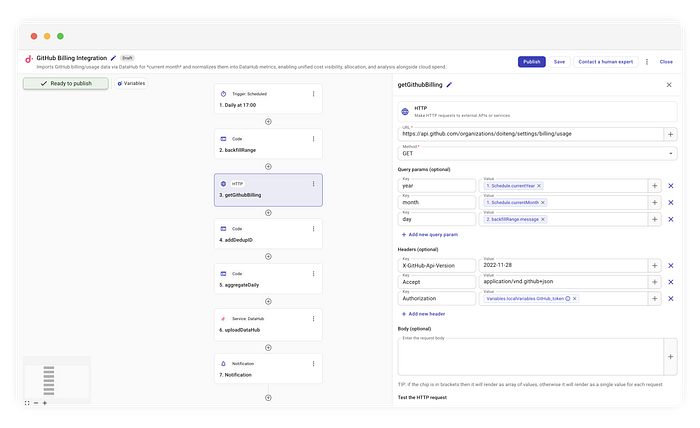
ステップ2:パラメータ化されたAPI呼び出し
次に、標準のHTTPコネクタでGitHubのエンドポイントを叩きます。
GET https://api.github.com/organizations/{org}/settings/billing/usage
GitHub Billing APIの呼び出し
前のステップで得たdayを、クエリパラメータに動的に差し込みます。
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(ループ内の現在の要素)
これでGitHubのAPI仕様に沿いつつ、ローリングウィンドウの柔軟性も両立できます。
ステップ3:冪等性キー(「秘伝のタレ」)
多くの連携が破綻するのは、まさにここです。
「1月1日」のデータを月の中で30回取得した場合、それをそのままデータベースに追記してはいけません。コストが30倍に膨れ上がってしまいます。必要なのはUpsert戦略(あれば更新、なければ挿入)です。
これを確実に行うには、決定論的なID、つまり課金明細ごとの「指紋」が欠かせません。そこでaddDedupIDというコードステップを追加します。
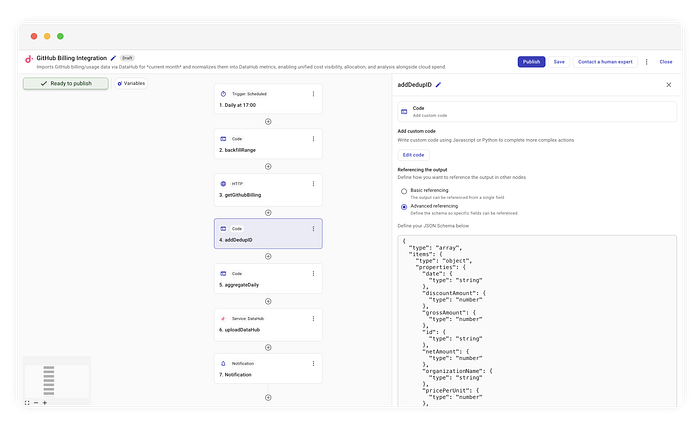
重複排除用ハッシュの生成
生データを見て、不変なフィールドをハッシュ化することでこのIDを作ります。
// 'addDedupID'内のロジック
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// リソースを定義する文字列フィールド(製品、SKU、単位種別など)のみを抽出
const stringFields = extractStringFields(usageItem);
// SHA256ハッシュを生成
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
リソース属性(sku、product、unitTypeなど)に基づいてハッシュを計算するため、同じレコードを100回取得してもIDは常に同一です。DataHubはこのIDを使って既存エントリを上書きするので、行を重複させずに更新内容だけを確実に取り込めます。
ステップ4:取り込みと通知
ここでCloudFlowの真価が発揮されます。受け手に応じてロジックを分岐できるのです。
マシン向け(DataHub):
粒度の細かい明細データ(生成したID付き)を、uploadDataHubステップに直接送ります。これにより、分析プラットフォーム側はリポジトリやSKU単位までドリルダウンできる、最も忠実度の高いデータを保持できます。
人間向け(通知):
運用チャンネルを何千行ものJSONで埋め尽くしたくはありません。アップロードと並行してaggregateDailyを実行します。このコードは項目を順に処理してnetAmountを合計し、すっきりした要約を作ります。
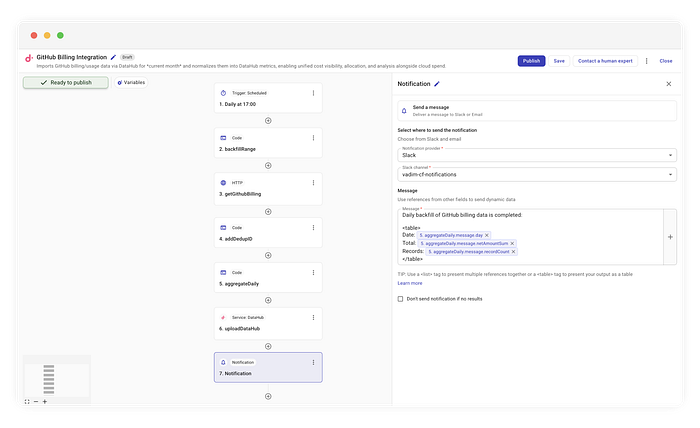
Slack通知の例
例ではSlackを使っていますが、このフローの嬉しいところは通知先をまったく選ばない点です。チームが使っているツールに自由にルーティングできます。
- メール: 公式な日次監査ログとして。
- Amazon SNS: 後続のLambda関数を起動するトリガーとして。
- Microsoft Teams: webhookコネクタ経由で。
- 汎用HTTP: 任意の社内ダッシュボードへ要約をPOST。
今回は、集計データを読みやすいテーブル形式に整えて送るだけです。
GitHub課金データの日次バックフィルが完了しました:
| 日付 | 合計 | 件数 |
|------------|---------|---------|
| 2023-10-01 | $45.20 | 120 |
| 2023-10-02 | $48.10 | 135 |
こうして関心を分離する(ウェアハウス向けには粒度の細かいデータ、人間向けには集計データ)ことで、FinOpsチームもDevOpsチームも、どちらも満足できる構成になります。
成果 — **_自動化されたガバナンスとチャージバック_**
このデータをDataHubに取り込むと、生のAPIだけでは実現できない後続のFinOpsワークフローが動かせるようになります。第一に、データセットは異常検知アルゴリズムによって自動的に監視されます。CI/CDパイプラインの設定ミスでコンピュート使用量が急増した場合、システムは過去のベースラインからの逸脱を検知し、アラートを発します。第二に、データはコスト配賦にも使えるようになります。
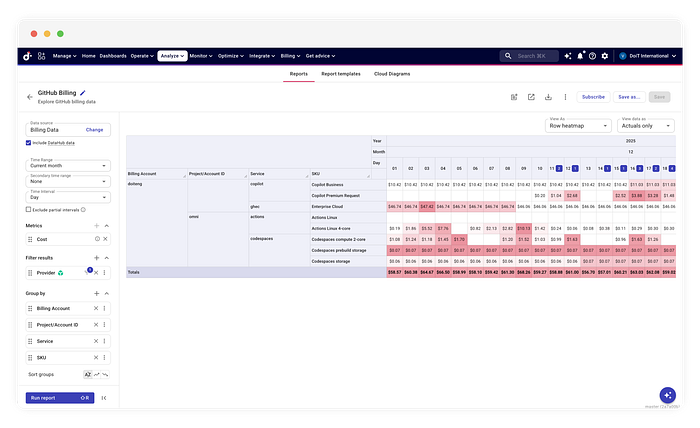
課金連携の構築で本質的に重要なのは、API接続そのものよりもデータのライフサイクルをどう扱うかです。CloudFlowのようなツールを使えば、このライフサイクルを視覚的にモデル化でき、専用のETLエンジンをゼロから作り込まずに、遡及更新のような厄介な問題を解決できます。
「デフォルトでバックフィルする」パターンを採用すれば、財務チームと数字の食い違いについて議論する日々から解放され、自社のデータを再び信頼できるようになります。
このワークフローはCloudFlowで構築されました。CloudFlowはDoiT Cloud Intelligence™ portfolioの一部です。