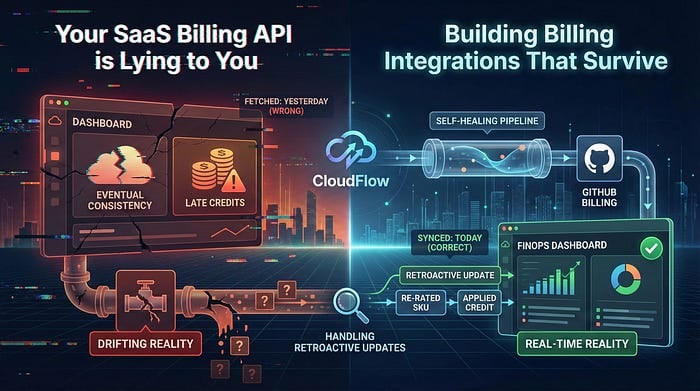
Wer Billing-Integrationen für FinOps oder CloudOps baut, muss das wissen: Die Daten, die Sie eben aus dieser SaaS-API gezogen haben, stimmen mit hoher Wahrscheinlichkeit nicht.
Nicht wegen eines Bugs, sondern weil Cloud-Billing nun einmal so funktioniert. Usage-Metering ist häufig nur eventually consistent. Credits werden verspätet verrechnet. SKUs werden Tage später neu bewertet. Wenn Ihre Integration einmal anläuft, die Daten von gestern abruft und sich dann schlafen legt, entfernt sich Ihr FinOps-Dashboard mit jedem Tag weiter von der Realität.
In diesem Beitrag zeige ich Ihnen, wie Sie eine Billing-Integration bauen, die im Praxisbetrieb tatsächlich besteht.
Wir sehen uns ein Integrationsmuster für GitHub Billing an, das wir mit CloudFlow umgesetzt haben – einer Low-Code-Engine zur Datenorchestrierung. Dabei lösen wir das härteste Problem beim Billing-Ingest: rückwirkende Datenaktualisierungen verarbeiten, ohne in einen Duplikat-Albtraum zu rutschen.
Der Stack: kurz eingeordnet
Bevor wir in den Code einsteigen, kurz zum Kontext der eingesetzten Tools. Sie kennen diese Komponenten vielleicht nicht, aber die Architekturmuster lassen sich auf jede robuste Datenpipeline übertragen.
- CloudFlow : Die Engine, in der unsere Logik läuft. Eine Low-Code-Plattform, mit der sich anspruchsvolle Billing- und Operations-Workflows umsetzen lassen, ohne eigene Infrastruktur zu betreiben.
- DataHub : Unser Ziel. Das vereinheitlichte Daten-Repository in DoiT Cloud Intelligence™, in dem normalisierte Billing-Daten aus AWS, Azure, GCP und eigenen Quellen (etwa Databricks, Snowflake, DataDog usw.) für die Analyse nebeneinander vorliegen.
Unser Ziel ist klar: GitHub-Billing-Daten in einen FinOps-DataHub bringen, um sie zusammen mit den übrigen Cloud- und SaaS-Ausgaben auswerten zu können.
**Implizite Vektorisierung in CloudFlow**
CloudFlow geht mit Iteration anders um als klassische DAG-Orchestratoren. Es setzt auf implizite Vektorisierung: Gibt ein Schritt ein Array aus (z. B. eine Liste von Datumswerten), fächert die Engine die nachfolgenden Nodes automatisch auf – ganz ohne explizite "for-each"- oder "map"-Konstrukte.
So passt die Pipeline ihre Parallelität dynamisch an die Größe des Payloads an und verarbeitet T[]-Inputs als parallele Ausführungs-Threads, während der visuelle Graph linear und gut lesbar bleibt.
Mehr braucht es nicht, um GitHub an Ihren FinOps-Stack anzubinden.
Zusätzlich unterstützt die Engine zustandsbehaftete Suspendierung für Governance-Zwecke. Diese Billing-Integration läuft unbeaufsichtigt, doch Operationen mit Seiteneffekten – etwa das Beenden von Ressourcen – brauchen oft eine Freigabe per Human-in-the-Loop (HITL).
CloudFlow kann den Ausführungskontext an festgelegten "Approval"-Nodes pausieren und den Zustand persistieren, bis ein asynchrones Signal – etwa ein Webhook aus Slack oder ein Klick in einer E-Mail – die Pipeline wieder anstößt.
Das Problem: der Mythos vom "unveränderlichen" Datensatz
Die meisten Entwickler bauen Billing-Pipelines so:
- Um 01:00 UTC starten.
- API für
date = gesternabfragen. - Ergebnis ins Data Warehouse schreiben.
Das setzt voraus, dass Billing-Daten nach dem Schreiben unveränderlich sind. Sind sie aber nicht.
SaaS-Anbieter aktualisieren Billing-Datensätze für den laufenden Monat regelmäßig. Eine Nutzungsspitze vom 12. ist möglicherweise erst am 15. vollständig abgerechnet. Wenn Sie die Daten des 12. nur am 13. abgerufen haben, geht Ihnen das Update durch die Lappen.
Die Lösung: eine Re-Polling-Window-Strategie. Statt "gestern" holen wir jeden Tag die Month-to-Date-Daten (MTD).
Die Architektur
Wir bauen einen Flow, der täglich läuft, dabei aber jedes Mal den gesamten laufenden Monat neu verarbeitet. So stellen wir sicher: Passt GitHub am 20. die Kosten für den 1. des Monats an, bekommen wir das mit.
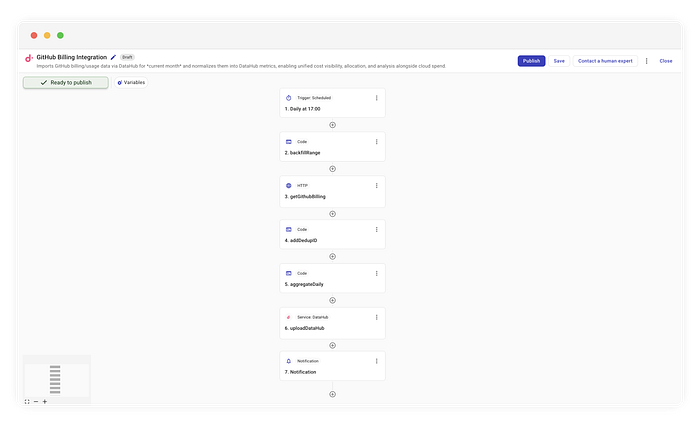
Vollständiger Flow für die GitHub-Billing-Integration
So sieht die Logik im Überblick aus, die wir in CloudFlow umsetzen:
- Scheduling: Täglich um 10 Uhr ET.
- Window-Berechnung: Zeitraum bestimmen (Tag 1 bis aktueller Tag).
- Fetch (Fan-out): API für jeden Tag in diesem Fenster abfragen.
- Deduplizierung (entscheidend): Deterministische IDs erzeugen, um Duplikate zu vermeiden.
- Ingest: Detaildaten per Upsert in DataHub schreiben.
- Notify: Summen separat aggregieren – für eine menschenlesbare Zusammenfassung.
Bauen wir das Schritt für Schritt auf.
Schritt 1: Das Rolling Window (das "Backfill")
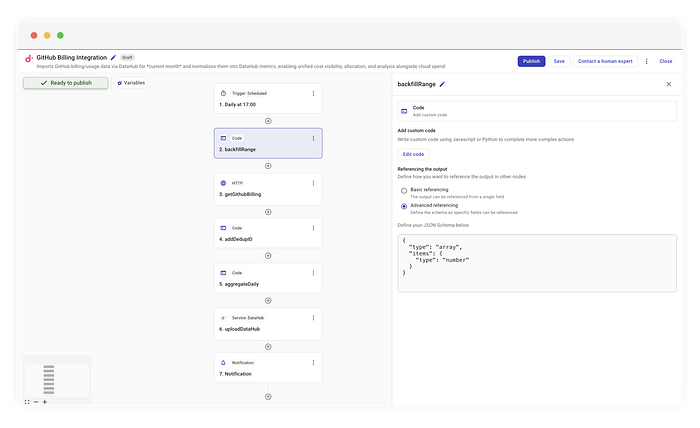
Wir starten mit einem klassischen Cron-Trigger, der täglich um 17:04 läuft. Anstatt aber gestern an unseren API-Schritt zu übergeben, nutzen wir einen Custom-Code-Schritt namens backfillRange.
Dieser Schritt erzeugt ein Array mit allen bisherigen Tagen des Monats.
Anzahl der zu verarbeitenden Tage ermitteln
// Vereinfachte Logik aus dem Schritt 'backfillRange'
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// Array [1, 2, ..., endDay] erzeugen
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
Warum das wichtig ist: Durch die Rückgabe eines Arrays fächert CloudFlow automatisch auf. Die folgenden Schritte laufen einmal pro Tag in diesem Array. Am 30. eines Monats läuft dieser Flow 30-mal und frischt die komplette Billing-Historie für diesen Zeitraum auf.
Das Output-Schema Damit nachgelagerte Nodes Ihre Daten validieren und automatisch vervollständigen können, definieren Sie ein Output-Schema. Es modelliert strikt den JSON-Wert, den Ihr Node zurückgibt (z. B. ein String-Array oder ein konkretes Objekt), und blendet die internen Ausführungs-Wrapper und Metadaten von CloudFlow bewusst aus. Indem Sie die Struktur rekursiv beschreiben und genau Ihrem Top-Level-Objekt oder -Array entsprechen lassen, schaffen Sie einen typsicheren Vertrag, der garantiert, dass die übrige Pipeline genau das bekommt, was sie erwartet.
Schritt 2: Parametrisierte API-Aufrufe
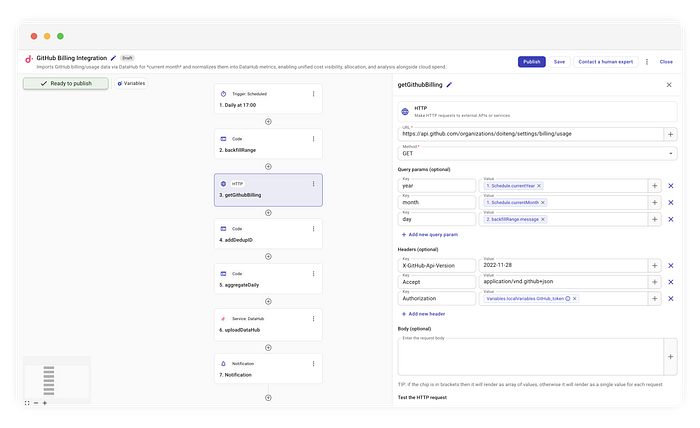
Anschließend rufen wir mit einem Standard-HTTP-Connector den GitHub-Endpoint auf:
GET https://api.github.com/organizations/{org}/settings/billing/usage
Aufruf der GitHub Billing API
Den day aus dem vorherigen Schritt schleusen wir dynamisch in die Query-Parameter:
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(das aktuelle Element aus unserer Schleife)
So bleiben wir konform mit der API-Struktur von GitHub und behalten zugleich die Flexibilität unseres Rolling Windows.
Schritt 3: Der Idempotenz-Schlüssel (die "Geheimzutat")
Genau hier scheitern die meisten Integrationen.
Wenn Sie die Daten für den 1. Januar im Laufe des Monats 30-mal abrufen, dürfen Sie sie nicht einfach an Ihre Datenbank anhängen. Sonst stehen die Kosten dort am Ende 30-fach. Sie brauchen eine Upsert-Strategie (aktualisieren, falls vorhanden; einfügen, falls neu).
Damit das zuverlässig funktioniert, benötigen Sie eine deterministische ID – einen "Fingerabdruck" für jede einzelne Billing-Position. Dafür ergänzen wir einen Code-Schritt namens addDedupID.
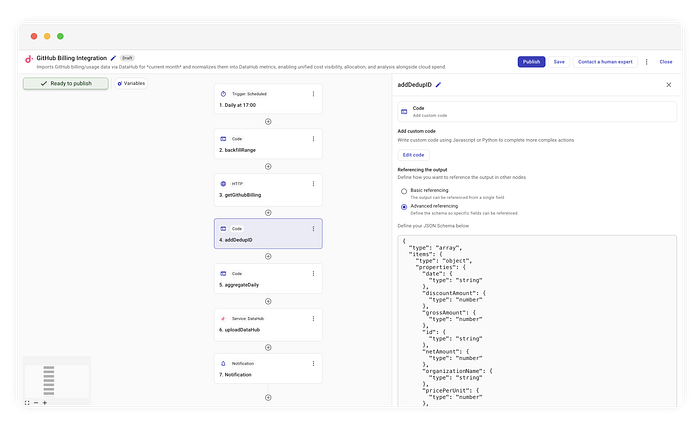
Hashes für die Deduplizierung erzeugen
Wir nehmen die Rohdaten und hashen die unveränderlichen Felder, um daraus die ID zu bilden.
// Logik in 'addDedupID'
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// Nur String-Felder extrahieren, die die Ressource definieren (Produkt, SKU, Unit-Type usw.)
const stringFields = extractStringFields(usageItem);
// SHA256-Hash erzeugen
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
Indem wir den Hash auf Basis der Ressourcenattribute (z. B. sku, product, unitType) berechnen, ist die ID auch dann immer identisch, wenn wir denselben Datensatz 100-mal abrufen. DataHub nutzt diese ID, um den vorhandenen Eintrag zu überschreiben – Aktualisierungen werden so erfasst, ohne dass Zeilen dupliziert werden.
Schritt 4: Ingest vs. Benachrichtigung
Hier zeigt sich die Stärke von CloudFlow: verzweigte Logik für unterschiedliche Zielgruppen.
Für die Maschine (DataHub):
Die granularen Detaildaten (samt unserer generierten IDs) gehen direkt an den Schritt uploadDataHub. So bekommt unsere Analyseplattform die maximale Datentiefe, um Kosten nach Repository oder SKU aufzuschlüsseln.
Für den Menschen (Benachrichtigungen):
Wir wollen unsere Ops-Channels nicht mit Tausenden JSON-Zeilen zumüllen. Parallel zum Upload läuft daher ein aggregateDaily. Dieser Code iteriert über die Items und summiert das netAmount zu einer sauberen Übersicht.
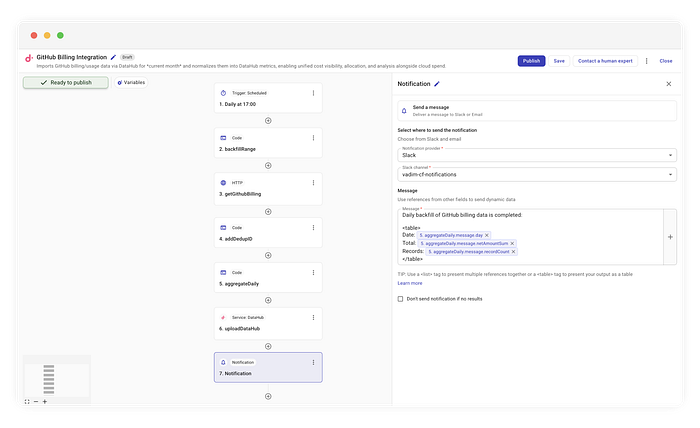
Beispiel für eine Slack-Benachrichtigung
In unserem Beispiel nutzen wir Slack, das Schöne an diesem Flow ist aber: Das Ziel der Benachrichtigung ist völlig austauschbar. Sie können die Zusammenfassung an jedes Tool routen, das Ihr Team einsetzt:
- E-Mail: Für ein formales tägliches Audit-Log.
- Amazon SNS: Um nachgelagerte Lambda-Funktionen anzustoßen.
- Microsoft Teams: Über einen Webhook-Connector.
- Generisches HTTP: Um die Zusammenfassung per POST an ein beliebiges internes Dashboard zu senden.
In unserem Fall formatieren wir die aggregierten Daten einfach in eine lesbare Tabelle und schicken sie raus.
Tägliches Backfill der GitHub-Billing-Daten abgeschlossen:
| Datum | Summe | Records |
|------------|---------|---------|
| 2023-10-01 | $45.20 | 120 |
| 2023-10-02 | $48.10 | 135 |
Diese Trennung – granulare Daten fürs Warehouse, aggregierte Daten für die Menschen – sorgt dafür, dass sowohl Ihr FinOps- als auch Ihr DevOps-Team zufrieden sind.
Der Mehrwert – **_automatisierte Governance & Chargeback._**
Sobald diese Daten in DataHub liegen, werden FinOps-Workflows möglich, die rohe APIs nicht abbilden können. Erstens überwachen Anomaly-Detection-Algorithmen den Datensatz automatisch. Verursacht eine Fehlkonfiguration in einer CI/CD-Pipeline einen Compute-Spike, erkennt das System die Abweichung von der historischen Baseline und löst einen Alert aus. Zweitens stehen die Daten für die Cost Allocation bereit.
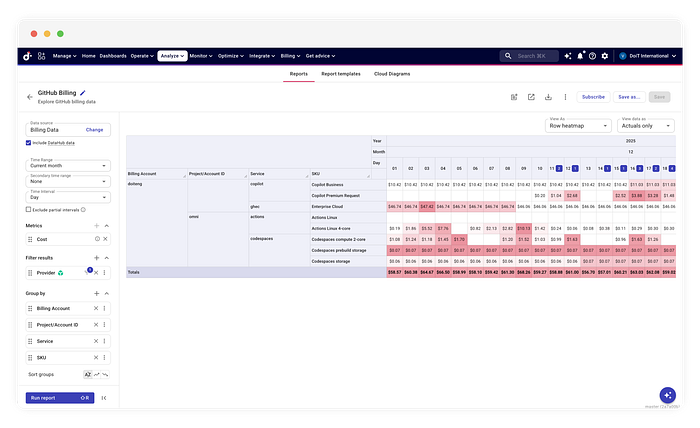
Beim Bau von Billing-Integrationen geht es weniger um die API-Anbindung als um den Lebenszyklus der Daten. Tools wie CloudFlow erlauben es uns, diesen Lebenszyklus visuell zu modellieren und komplexe Probleme wie rückwirkende Updates zu lösen, ohne eine eigene ETL-Engine von Grund auf zu schreiben.
Mit dem Muster "Backfill by Default" hören Sie auf, mit Ihrem Finance-Team über abweichende Zahlen zu diskutieren – und vertrauen Ihren Daten wieder.
Dieser Workflow wurde mit CloudFlow umgesetzt, Teil des DoiT Cloud Intelligence ™ Portfolios.