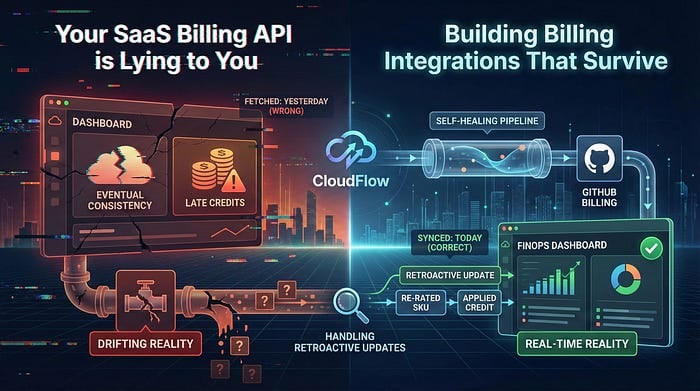
Se você desenvolve integrações de billing para FinOps ou CloudOps, tenho uma má notícia: os dados que você acabou de buscar naquela API de SaaS provavelmente estão errados.
O motivo não é um bug, e sim a forma como o billing em nuvem funciona. A medição de uso costuma ter consistência eventual. Créditos entram com atraso. SKUs são reprecificados dias depois. Se a sua integração roda uma vez, puxa os dados de ontem e segue em frente, seu dashboard de FinOps se afasta da realidade um pouco mais a cada dia.
Neste post, vou mostrar como construir uma integração de billing que realmente sobrevive no mundo real.
Vamos analisar um padrão de integração com o GitHub Billing que criamos usando o CloudFlow, um motor de orquestração de dados low-code. Vamos resolver o problema mais difícil da ingestão de billing: lidar com atualizações retroativas sem virar um pesadelo de duplicação.
A stack: uma rápida introdução
Antes de mergulhar no código, vale o contexto sobre as ferramentas que estamos usando. Talvez você não conheça esses componentes, mas os padrões de arquitetura valem para qualquer pipeline de dados robusto.
- CloudFlow : é o motor que executa a nossa lógica. Trata-se de uma plataforma low-code feita para criar workflows sofisticados de billing e operações sem precisar gerenciar infraestrutura.
- DataHub : é o nosso destino. É o repositório unificado de dados dentro do DoiT Cloud Intelligence™, onde dados de billing normalizados de AWS, Azure, GCP e fontes customizadas (como Databricks, Snowflake, DataDog etc.) ficam lado a lado para análise.
Nosso objetivo é simples: levar os dados de billing do GitHub para um DataHub de FinOps e analisá-los junto com os demais gastos de cloud e SaaS.
**Vetorização implícita do CloudFlow**
O CloudFlow trata a iteração de um jeito diferente dos orquestradores de DAG tradicionais. Ele usa vetorização implícita: se um step retorna um array (uma lista de datas, por exemplo), o motor automaticamente faz o fan-out dos nós seguintes, sem exigir estruturas de controle explícitas como "for-each" ou "map".
Isso permite que o pipeline escale a concorrência dinamicamente conforme o tamanho do payload, processando entradas T[] como threads de execução paralelas e mantendo um grafo visual linear e legível.
É só isso que você precisa para integrar o GitHub à sua stack de FinOps.
Além disso, o motor oferece suspensão com estado para fins de governança. Embora essa integração de billing rode sem supervisão, operações com efeitos colaterais (como encerrar recursos) frequentemente exigem validação Human-in-the-Loop (HITL).
O CloudFlow consegue pausar o contexto de execução em nós específicos de "Aprovação" e persistir o estado até que um sinal assíncrono — como um webhook do Slack ou um clique em e-mail — retome o pipeline.
O problema: a mentira do "imutável"
A maioria dos desenvolvedores constrói pipelines de billing assim:
- Acordar às 01:00 UTC.
- Consultar a API com
date = ontem. - Salvar o resultado no data warehouse.
A premissa é que os dados de billing são imutáveis depois de gravados. Não são.
Provedores de SaaS atualizam os registros de billing do mês corrente o tempo todo. Um pico de uso do dia 12 pode só ser totalmente reconciliado no dia 15. Se você só puxou os dados do dia 12 no dia 13, perdeu a atualização.
Para resolver isso, precisamos de uma estratégia de janela de re-polling. Em vez de buscar "ontem", buscamos "Month-to-Date" (MTD) todos os dias.
A arquitetura
Vamos construir um fluxo que roda diariamente, mas reprocessa o mês corrente inteiro a cada execução. Assim, se o GitHub atualizar o custo do dia 1º do mês no dia 20, a gente captura essa mudança.
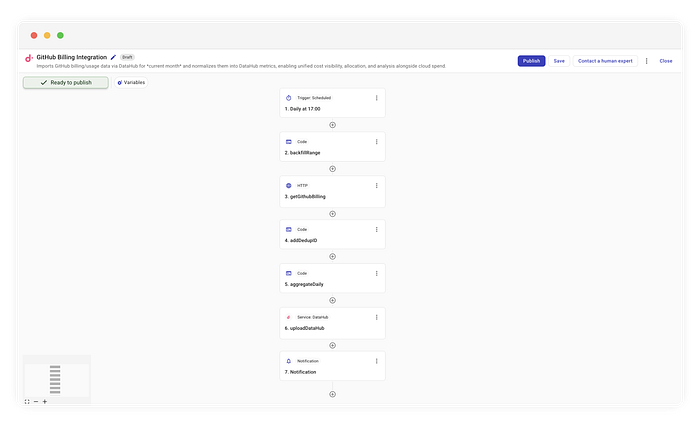
Fluxo completo da integração de billing do GitHub
Esta é a lógica de alto nível que vamos implementar no CloudFlow:
- Agendamento: rodar diariamente às 10h ET.
- Cálculo da janela: determinar o intervalo (do dia 1 até o dia atual).
- Fetch (fan-out): consultar a API para cada dia dessa janela.
- Deduplicação (crucial): gerar IDs determinísticos para evitar duplicatas.
- Ingestão: fazer upsert dos dados detalhados no DataHub.
- Notificação: agregar totais separadamente em um resumo legível por humanos.
Vamos construir isso passo a passo.
Passo 1: a janela móvel (o "backfill")
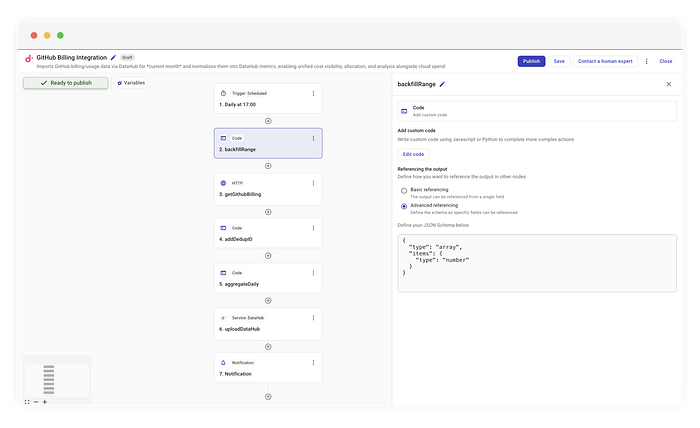
Começamos com um trigger cron padrão rodando diariamente às 17:04. Mas, em vez de passar ontem para o step da API, usamos um step de código customizado chamado backfillRange.
Esse step gera um array de dias representando todo o mês até o momento.
Extraindo o número de dias a processar
// Lógica simplificada do step 'backfillRange'
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// Gera um array [1, 2, ..., endDay]
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
Por que isso importa: ao retornar um array, o CloudFlow faz o fan-out automaticamente. Os steps seguintes rodam uma vez por dia desse array. No dia 30 do mês, esse fluxo roda 30 vezes, atualizando todo o histórico de billing daquele período.
O Output Schema Para que os nós seguintes consigam validar e autocompletar seus dados, você define um Output Schema. Esse schema modela rigorosamente o valor JSON que seu nó retorna (um array de strings ou um objeto específico, por exemplo) e ignora propositalmente os wrappers internos de execução e metadados do CloudFlow. Ao definir o formato de maneira recursiva, espelhando exatamente seu objeto ou array de nível superior, você cria um contrato com tipagem segura que garante que o resto do pipeline receba exatamente o que espera.
Passo 2: chamadas de API parametrizadas
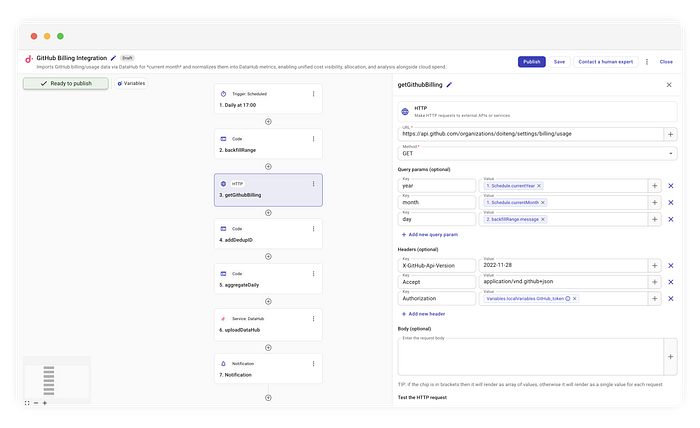
Em seguida, usamos um conector HTTP padrão para acessar o endpoint do GitHub:
GET https://api.github.com/organizations/{org}/settings/billing/usage
Chamando a API de Billing do GitHub
Injetamos dinamicamente o day do step anterior nos parâmetros de query:
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(o item atual do nosso loop)
Assim, respeitamos a estrutura da API do GitHub sem perder a flexibilidade da nossa janela móvel.
Passo 3: a chave de idempotência (o "pulo do gato")
É aqui que a maioria das integrações falha.
Se você buscar os dados do "1º de janeiro" trinta vezes ao longo do mês, não dá para simplesmente acrescentá-los ao banco. Você vai acabar com 30x o custo. Você precisa de uma estratégia de upsert (atualizar se existir, inserir se for novo).
Para fazer isso de forma confiável, é preciso um ID determinístico — uma "impressão digital" para cada item de billing. Adicionamos um step de código chamado addDedupID.
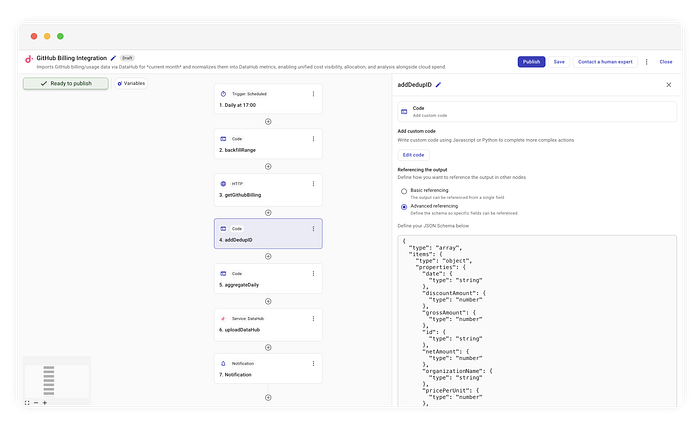
Criando hashes para deduplicação
Pegamos os dados brutos e geramos o hash dos campos imutáveis para criar esse ID.
// Lógica dentro de 'addDedupID'
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// Extrai apenas campos string que definem o recurso (produto, SKU, tipo de unidade etc.)
const stringFields = extractStringFields(usageItem);
// Cria um hash SHA256
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
Ao calcular um hash com base nos atributos do recurso (por exemplo, sku, product, unitType), garantimos que, mesmo buscando o mesmo registro 100 vezes, o ID será sempre idêntico. O DataHub usa esse ID para sobrescrever a entrada anterior, capturando qualquer atualização sem duplicar a linha10.
Passo 4: ingestão vs. notificação
É aqui que o poder do CloudFlow se destaca: lógica de ramificação para públicos diferentes.
Para a máquina (DataHub):
Enviamos os dados granulares, item por item (com os IDs gerados), direto para o step uploadDataHub. Assim, nossa plataforma de analytics tem dados com a maior fidelidade possível para detalhar custos por repositório ou SKU.
Para o humano (notificações):
Não queremos lotar os canais de Ops com milhares de linhas em JSON. Em paralelo ao upload, rodamos um aggregateDaily. Esse código itera pelos itens e soma o netAmount para gerar um resumo enxuto.
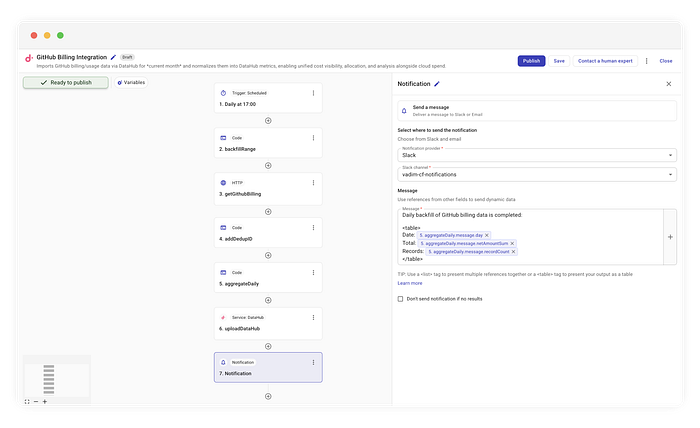
Exemplo de notificação no Slack
Embora o nosso exemplo use o Slack, o legal desse fluxo é que o destino da notificação é totalmente agnóstico. Você pode rotear esse resumo para a ferramenta que o seu time preferir:
- E-mail: para um log de auditoria diário formal.
- Amazon SNS: para acionar funções Lambda downstream.
- Microsoft Teams: usando um conector de webhook.
- HTTP genérico: para fazer POST do resumo em qualquer dashboard interno.
No nosso caso, simplesmente formatamos os dados agregados em uma tabela legível e disparamos.
Backfill diário dos dados de billing do GitHub concluído:
| Data | Total | Registros |
|------------|---------|-----------|
| 01/10/2023 | $45,20 | 120 |
| 02/10/2023 | $48,10 | 135 |
Essa separação de responsabilidades — dados granulares para o warehouse, dados agregados para os humanos — deixa tanto o time de FinOps quanto o de DevOps satisfeitos.
O resultado — **_governança e chargeback automatizados._**
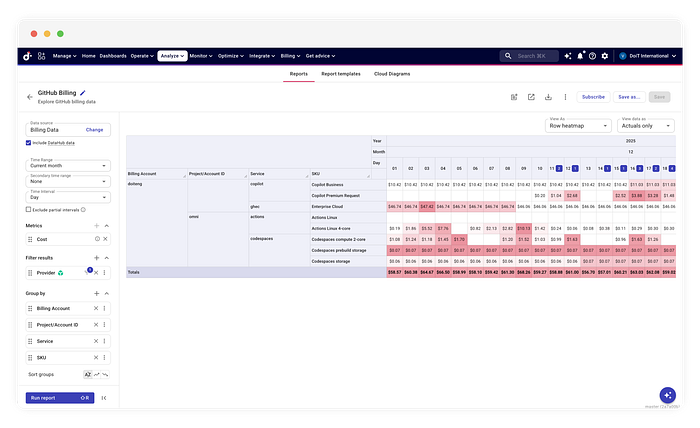
Levar esses dados para o DataHub habilita workflows de FinOps que APIs cruas simplesmente não suportam. Primeiro, o dataset passa a ser monitorado automaticamente por algoritmos de Detecção de Anomalias. Se uma má configuração em um pipeline de CI/CD provocar um pico de compute, o sistema identifica o desvio em relação ao baseline histórico e dispara um alerta. Segundo, os dados ficam disponíveis para Alocação de Custos.
Construir integrações de billing tem menos a ver com a conexão da API e muito mais com o ciclo de vida do dado. Ferramentas como o CloudFlow permitem modelar esse ciclo de vida visualmente, resolvendo problemas complexos como atualizações retroativas sem precisar escrever um motor de ETL sob medida do zero.
Ao adotar um padrão de "Backfill por Padrão", você para de brigar com o time financeiro sobre por que os números não batem e volta a confiar nos seus dados.
Este workflow foi construído com o CloudFlow, parte do portfólio DoiT Cloud Intelligence ™.