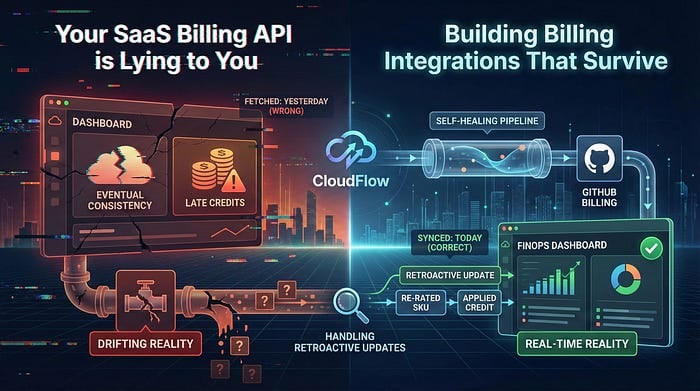
Se sta sviluppando integrazioni di billing per FinOps o CloudOps, ho una brutta notizia: i dati che ha appena estratto da quell'API SaaS sono quasi certamente sbagliati.
Non per un bug, ma per il modo in cui funziona il billing nel cloud. Il metering dell'utilizzo è quasi sempre eventually consistent. I crediti vengono applicati in ritardo. Le SKU vengono ricalcolate giorni dopo. Se la sua integrazione parte una sola volta, scarica i dati di ieri e tira dritto, il suo dashboard FinOps si allontana ogni giorno di più dalla realtà.
In questo articolo le mostrerò come costruire un'integrazione di billing capace di reggere davvero in produzione.
Vedremo un pattern di integrazione con GitHub Billing che abbiamo realizzato con CloudFlow, un motore di orchestrazione dati low-code. Affronteremo il problema più ostico nell'ingestione dei dati di billing: gestire gli aggiornamenti retroattivi senza trasformare il database in un incubo di duplicati.
Lo stack: una breve panoramica
Prima di tuffarci nel codice, ecco il contesto degli strumenti che useremo. Magari non li conosce nel dettaglio, ma i pattern architetturali valgono per qualsiasi pipeline dati robusta.
- CloudFlow : è il motore che esegue la nostra logica. Una piattaforma low-code pensata per costruire workflow di billing e operativi sofisticati senza dover gestire l'infrastruttura.
- DataHub : è la nostra destinazione. Il repository dati unificato all'interno di DoiT Cloud Intelligence™, dove i dati di billing normalizzati provenienti da AWS, Azure, GCP e fonti custom (come Databricks, Snowflake, DataDog, ecc.) convivono fianco a fianco e sono pronti per l'analisi.
L'obiettivo è semplice: portare i dati di billing di GitHub in un DataHub FinOps, per analizzarli insieme al resto della spesa cloud e SaaS.
**La vettorializzazione implicita di CloudFlow**
CloudFlow gestisce l'iterazione in modo diverso rispetto ai classici orchestratori basati su DAG. Sfrutta la vettorializzazione implicita: se uno step restituisce in output un array (per esempio un elenco di date), il motore distribuisce automaticamente l'esecuzione sui nodi successivi, senza bisogno di costrutti espliciti come "for-each" o "map".
In questo modo la pipeline scala dinamicamente la concorrenza in base alla dimensione del payload, elaborando gli input T[] come thread di esecuzione paralleli, pur mantenendo un grafo visivo lineare e leggibile.
Non serve altro per integrare GitHub nel suo stack FinOps.
Il motore supporta inoltre la sospensione stateful a fini di governance. Questa integrazione di billing gira in modo non presidiato, ma le operazioni con effetti collaterali (come la terminazione di risorse) richiedono spesso una validazione Human-in-the-Loop (HITL).
CloudFlow può mettere in pausa il contesto di esecuzione su nodi di "Approvazione" specifici, mantenendo lo stato finché un segnale asincrono — un webhook da Slack o il click su un'email — non riprende la pipeline.
Il problema: la falsa promessa dell'"immutabilità"
La maggior parte degli sviluppatori costruisce le pipeline di billing più o meno così:
- Sveglia all'01:00 UTC.
- Query all'API per
date = yesterday. - Salvataggio del risultato nel data warehouse.
Si dà per scontato che, una volta scritti, i dati di billing siano immutabili. Non lo sono.
I provider SaaS aggiornano spesso i record di billing del mese in corso. Un picco di utilizzo del 12 potrebbe non essere riconciliato del tutto fino al 15. Se ha estratto i dati del 12 solamente il 13, quell'aggiornamento le è sfuggito.
Per ovviare al problema serve una Re-polling Window Strategy. Invece di scaricare i dati di "ieri", scarichiamo ogni giorno l'intero "Month-to-Date" (MTD).
L'architettura
Costruiremo un flow che gira ogni giorno ma rielabora ogni volta tutto il mese in corso. Così, se il giorno 20 GitHub aggiorna il costo del 1° del mese, riusciamo comunque a intercettarlo.
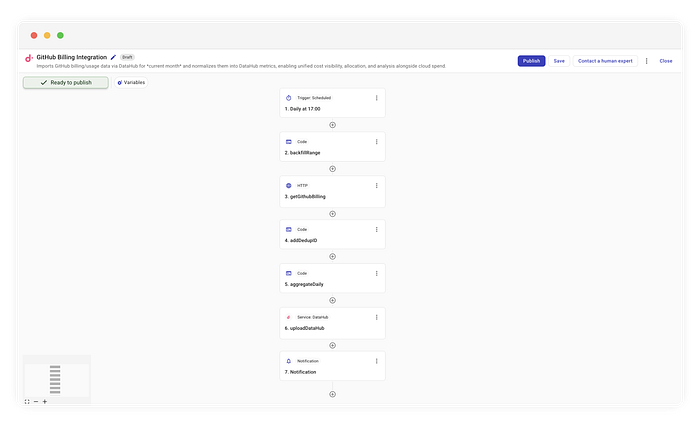
Flow completo che implementa l'integrazione con GitHub Billing
Ecco la logica ad alto livello che implementeremo in CloudFlow:
- Schedulazione: esecuzione giornaliera alle 10:00 ET.
- Calcolo della finestra: determinazione dell'intervallo (dal Giorno 1 al giorno corrente).
- Fetch (fan-out): query all'API per ogni giorno della finestra.
- Deduplicazione (cruciale): generazione di ID deterministici per evitare i duplicati.
- Ingestione: upsert dei dati di dettaglio in DataHub.
- Notifica: aggregazione separata dei totali per produrre un riepilogo leggibile.
Procediamo passo dopo passo.
Step 1: la finestra mobile (il "backfill")
Si parte da un classico trigger cron giornaliero, schedulato alle 17:04. Invece di passare yesterday allo step API, però, usiamo uno step di codice custom chiamato backfillRange.
Questo step genera un array di giorni che copre tutto il mese fino a oggi.
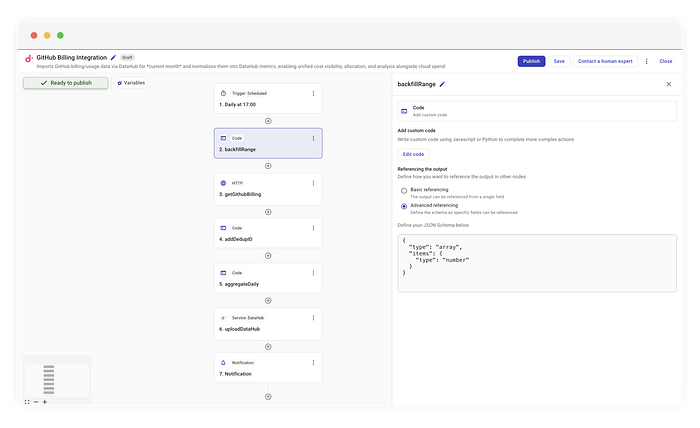
Estrazione del numero di giorni da elaborare
// Logica semplificata dello step 'backfillRange'
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// Genera un array [1, 2, ..., endDay]
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
Perché è importante: restituendo un array, CloudFlow esegue automaticamente il "fan-out". Gli step successivi vengono eseguiti una volta per ogni giorno dell'array. Il 30 del mese, questo flow gira 30 volte e aggiorna l'intero storico di billing del periodo.
Lo schema di output Per consentire ai nodi a valle di validare i dati e abilitare l'autocompletamento, si definisce uno schema di output. Questo schema modella in modo rigoroso il valore JSON restituito dal nodo (per esempio un array di stringhe o un oggetto specifico), ignorando volutamente i wrapper interni di esecuzione e i metadati di CloudFlow. Definendo la struttura in modo ricorsivo, in corrispondenza esatta con l'oggetto o l'array di livello superiore, si crea un contratto type-safe che garantisce al resto della pipeline esattamente ciò che si aspetta.
Step 2: chiamate API parametrizzate
Usiamo poi un connettore HTTP standard per chiamare l'endpoint di GitHub:
GET https://api.github.com/organizations/{org}/settings/billing/usage
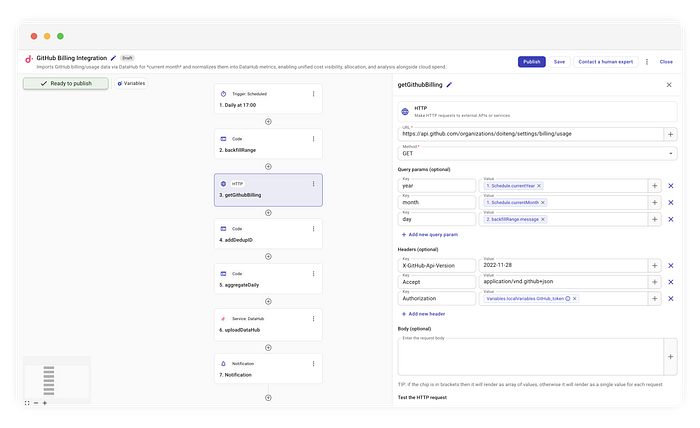
Chiamata all'API GitHub Billing
Iniettiamo dinamicamente il day generato dallo step precedente nei query parameter:
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(l'elemento corrente del nostro loop)
In questo modo rispettiamo la struttura dell'API di GitHub senza rinunciare alla flessibilità della finestra mobile.
Step 3: la chiave di idempotenza (il "segreto")
È qui che la maggior parte delle integrazioni si schianta.
Se nell'arco del mese estrae trenta volte i dati del "1° gennaio", non può limitarsi ad accodarli al database: si ritroverebbe con un costo trenta volte più alto. Le serve una strategia di upsert (aggiorna se esiste, inserisci se è nuovo).
Per farlo in modo affidabile servono ID deterministici — una sorta di "impronta digitale" per ogni voce di billing. Aggiungiamo quindi uno step di codice chiamato addDedupID.
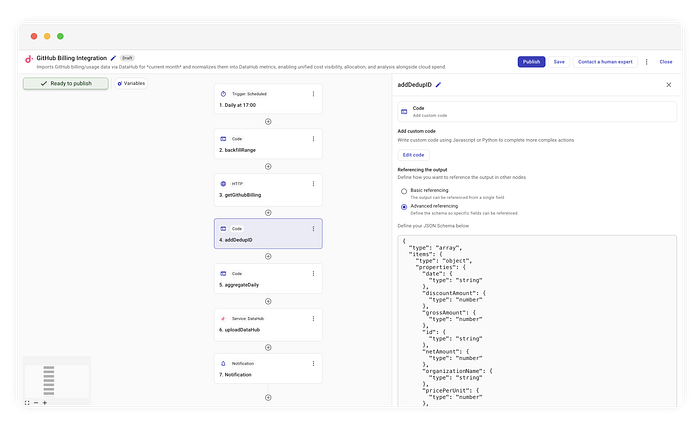
Generazione degli hash per la deduplicazione
Esaminiamo i dati grezzi e calcoliamo l'hash dei campi immutabili per costruire l'ID.
// Logica all'interno di 'addDedupID'
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// Estrae solo i campi stringa che definiscono la risorsa (prodotto, SKU, tipo di unità, ecc.)
const stringFields = extractStringFields(usageItem);
// Crea un hash SHA256
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
Calcolando un hash sugli attributi della risorsa (per esempio sku, product, unitType), garantiamo che, anche scaricando lo stesso record cento volte, l'ID sia sempre identico. DataHub usa questo ID per sovrascrivere la voce precedente, intercettando di fatto qualsiasi aggiornamento senza duplicare la riga.
Step 4: ingestione vs. notifica
È qui che CloudFlow dà il meglio di sé: logica di ramificazione per pubblici diversi.
Per la macchina (DataHub):
Inviamo i dati granulari, riga per riga (con gli ID che abbiamo generato), direttamente allo step uploadDataHub. Così la piattaforma di analytics dispone della massima fedeltà possibile per fare drill-down sui costi per repository o SKU.
Per le persone (notifiche):
Non vogliamo intasare i canali Ops con migliaia di righe JSON. In parallelo all'upload, eseguiamo quindi un aggregateDaily. Questo codice itera sugli elementi e somma il netAmount per produrre un riepilogo pulito.
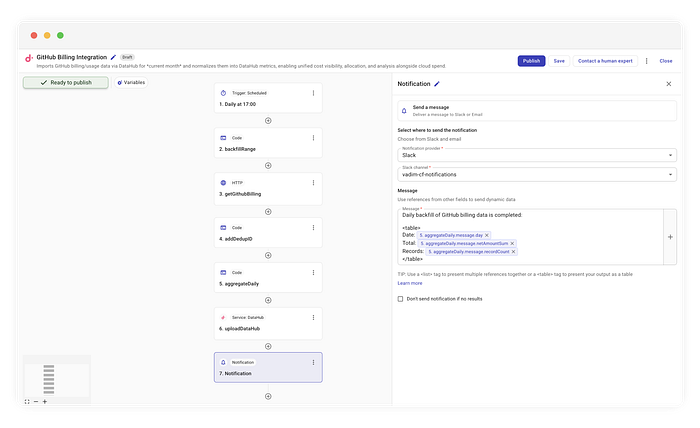
Esempio di notifica su Slack
Nel nostro esempio usiamo Slack, ma il bello di questo flow è che la destinazione della notifica è del tutto agnostica. Può instradare il riepilogo verso qualsiasi strumento utilizzato dal suo team:
- Email: per un log di audit giornaliero formale.
- Amazon SNS: per attivare funzioni Lambda a valle.
- Microsoft Teams: tramite un connettore webhook.
- HTTP generico: per inviare in POST il riepilogo a un qualsiasi dashboard interno.
Nel nostro caso, ci limitiamo a formattare i dati aggregati in una tabella leggibile e a inviarla.
Backfill giornaliero dei dati di billing GitHub completato:
| Data | Totale | Record |
|------------|---------|---------|
| 2023-10-01 | $45.20 | 120 |
| 2023-10-02 | $48.10 | 135 |
Questa separazione delle responsabilità — dati granulari per il warehouse, dati aggregati per le persone — fa contenti tanto i team FinOps quanto i team DevOps.
Il risultato — **_governance e chargeback automatizzati._**
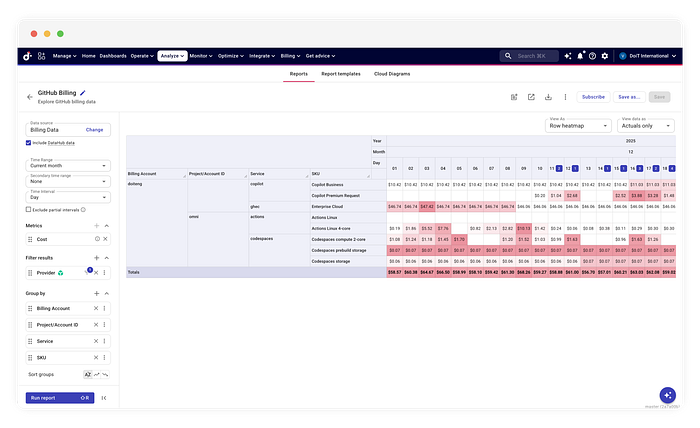
Portare questi dati in DataHub abilita workflow FinOps a valle che le API grezze non possono supportare. In primo luogo, il dataset viene monitorato in automatico dagli algoritmi di Anomaly Detection. Se una pipeline CI/CD mal configurata provoca un picco di compute, il sistema rileva la deviazione rispetto alla baseline storica e genera un alert. In secondo luogo, i dati diventano disponibili per la Cost Allocation.
Costruire integrazioni di billing significa preoccuparsi meno della connessione all'API e molto di più del ciclo di vita del dato. Strumenti come CloudFlow ci permettono di modellare visivamente questo ciclo di vita, risolvendo problemi complessi come gli aggiornamenti retroattivi senza dover scrivere da zero un motore ETL su misura.
Adottando un pattern "Backfill by Default", smetterà di discutere con il team finance sul perché i numeri non quadrano e tornerà a fidarsi davvero dei suoi dati.
Questo workflow è stato realizzato con CloudFlow, parte del portfolio DoiT Cloud Intelligence ™.