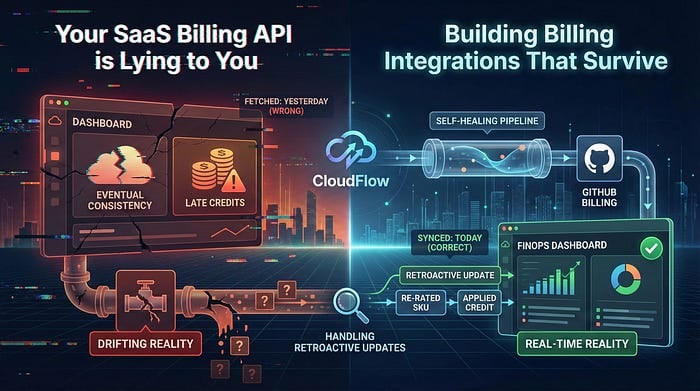
Si estás armando integraciones de facturación para FinOps o CloudOps, tengo malas noticias: los datos que acabas de traer de esa API SaaS seguramente están mal.
No por un bug, sino por cómo funciona la facturación en la nube. La medición del consumo suele ser eventualmente consistente. Los créditos se aplican tarde. Las SKU se recalculan días después. Si tu integración corre una sola vez, trae los datos de ayer y sigue de largo, tu dashboard de FinOps se aleja cada día más de la realidad.
En este post te voy a mostrar cómo armar una integración de facturación que de verdad sobreviva en el mundo real.
Vamos a ver un patrón de integración con GitHub Billing que armamos con CloudFlow, un motor de orquestación de datos low-code. Vamos a resolver el problema más difícil de la ingesta de facturación: gestionar las actualizaciones retroactivas sin que se te transformen en una pesadilla de duplicados.
El stack: una breve introducción
Antes de meternos en el código, este es el contexto del tooling que usamos. Quizás no conozcas estos componentes, pero los patrones de arquitectura aplican a cualquier pipeline de datos robusto.
- CloudFlow : el motor que ejecuta nuestra lógica. Es una plataforma low-code pensada para armar flujos sofisticados de facturación y operaciones sin tener que gestionar infraestructura.
- DataHub : nuestro destino. Es el repositorio unificado de datos dentro de DoiT Cloud Intelligence™, donde los datos de facturación normalizados de AWS, Azure, GCP y fuentes personalizadas (como Databricks, Snowflake, DataDog, etc.) conviven lado a lado para su análisis.
El objetivo es simple: llevar los datos de facturación de GitHub a un DataHub de FinOps para analizarlos junto con el resto del gasto en cloud y SaaS.
**Vectorización implícita en CloudFlow**
CloudFlow gestiona la iteración de forma distinta a los orquestadores de DAG estándar. Aplica vectorización implícita: si un paso devuelve un array (por ejemplo, una lista de fechas), el motor distribuye automáticamente los nodos siguientes sin necesidad de estructuras de control explícitas tipo "for-each" o "map".
Esto permite que el pipeline escale la concurrencia de forma dinámica según el tamaño del payload, procesando entradas T[] como hilos de ejecución paralela y manteniendo a la vez un grafo visual lineal y legible.
Con eso alcanza para integrar GitHub a tu stack de FinOps.
Además, el motor admite suspensión con estado para temas de gobernanza. Si bien esta integración de facturación corre sin supervisión, las operaciones con efectos colaterales (como la terminación de recursos) suelen requerir validación Human-in-the-Loop (HITL).
CloudFlow puede pausar el contexto de ejecución en nodos específicos de "Approval" y mantener el estado hasta que una señal asíncrona —un webhook desde Slack o un clic en un correo— reanude el pipeline.
El problema: la mentira de los datos "inmutables"
La mayoría de los desarrolladores arma sus pipelines de facturación así:
- Se ejecuta a las 01:00 UTC.
- Consulta la API con
date = ayer. - Guarda el resultado en el data warehouse.
Esto da por sentado que los datos de facturación son inmutables una vez escritos. No lo son.
Los proveedores SaaS actualizan con frecuencia los registros de facturación del mes en curso. Un pico de uso del día 12 puede no terminar de reconciliarse hasta el día 15. Si trajiste los datos del día 12 únicamente el día 13, te perdiste la actualización.
Para resolverlo, necesitamos una estrategia de ventana de re-consulta. En lugar de traer "el día de ayer", traemos el "Mes a la fecha" (MTD) todos los días.
La arquitectura
Vamos a armar un flujo que corre todos los días pero reprocesa el mes en curso completo en cada ejecución. Así, si GitHub actualizó el día 20 el costo del día 1 del mes, lo capturamos igual.
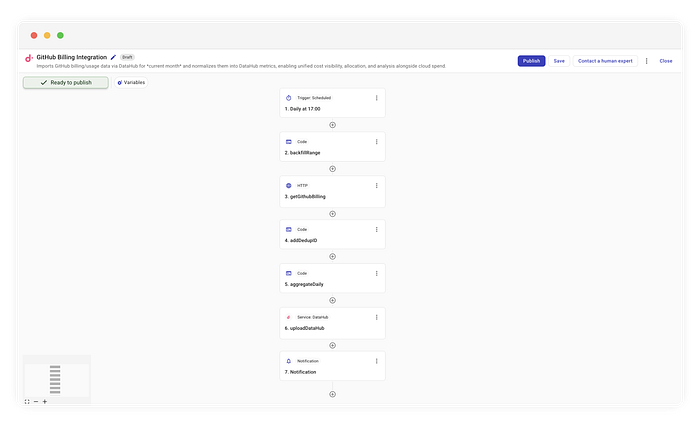
Flujo completo que implementa la integración de facturación de GitHub
Esta es la lógica de alto nivel que vamos a implementar en CloudFlow:
- Programación: ejecutar todos los días a las 10 a.m. ET.
- Cálculo de la ventana: determinar el rango (Día 1 al día actual).
- Fetch (Fan-out): consultar la API por cada día de esa ventana.
- Deduplicación (Crucial): generar IDs deterministas para evitar duplicados.
- Ingesta: hacer upsert de los datos detallados en DataHub.
- Notificación: agregar los totales por separado para tener un resumen legible para humanos.
Vamos a armarlo paso a paso.
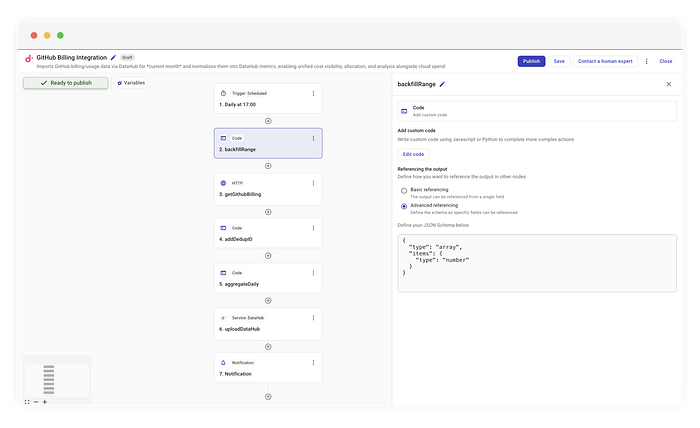
Paso 1: la ventana móvil (el "Backfill")
Empezamos con un trigger cron estándar que se ejecuta todos los días a las 17:04. Pero, en lugar de pasarle ayer al paso de la API, usamos un paso de código personalizado llamado backfillRange.
Este paso genera un array de días que representa todo el mes hasta la fecha.
Extraer la cantidad de días a procesar
// Lógica simplificada del paso 'backfillRange'
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// Genera un array [1, 2, ..., endDay]
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
Por qué importa: al devolver un array, CloudFlow hace "fan out" de forma automática. Los pasos siguientes se ejecutan una vez por cada día del array. El día 30 del mes, este flujo corre 30 veces y refresca todo el historial de facturación del período.
El esquema de salida Para que los nodos posteriores puedan validar y autocompletar tus datos, defines un Output Schema. Este esquema modela de forma estricta el valor JSON que devuelve tu nodo (por ejemplo, un array de strings o un objeto específico) e ignora a propósito los wrappers internos de ejecución y los metadatos de CloudFlow. Al definir la forma de manera recursiva, replicando exactamente tu objeto o array de nivel superior, creas un contrato seguro de tipos que garantiza que el resto del pipeline reciba justo lo que espera.
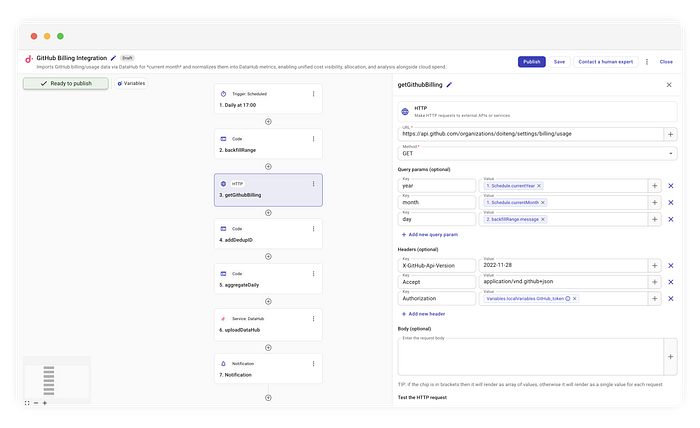
Paso 2: llamadas parametrizadas a la API
A continuación, usamos un conector HTTP estándar para llamar al endpoint de GitHub:
GET https://api.github.com/organizations/{org}/settings/billing/usage
Llamada a la API de facturación de GitHub
Inyectamos dinámicamente el day del paso anterior en los parámetros del query:
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(el ítem actual del loop)
De esta forma respetamos la estructura de la API de GitHub sin perder la flexibilidad de nuestra ventana móvil.
Paso 3: la clave de idempotencia (la "salsa secreta")
Acá es donde fallan la mayoría de las integraciones.
Si traes los datos del "1 de enero" treinta veces a lo largo del mes, no puedes simplemente añadirlos a tu base de datos: vas a terminar con 30 veces el costo. Necesitas una estrategia de Upsert (actualizar si existe, insertar si es nuevo).
Para hacerlo de forma confiable, necesitas un ID determinista —una "huella digital" para cada línea de facturación—. Agregamos un paso de código llamado addDedupID.
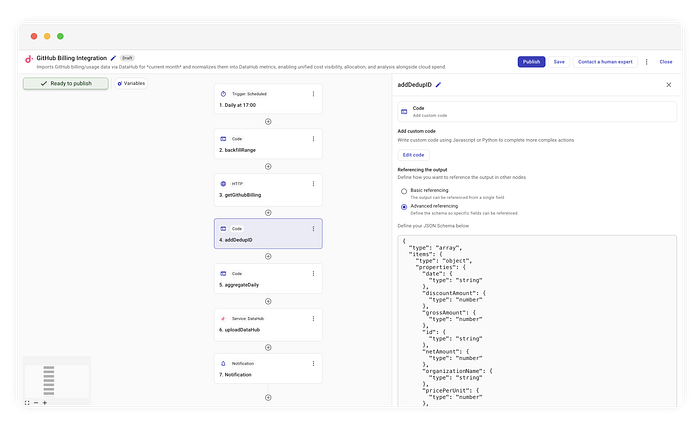
Creando hashes para deduplicación
Tomamos los datos crudos y hasheamos los campos inmutables para crear el ID.
// Lógica dentro de 'addDedupID'
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// Extrae solo los campos string que definen el recurso (producto, SKU, tipo de unidad, etc.)
const stringFields = extractStringFields(usageItem);
// Crea un hash SHA256
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
Al calcular un hash en base a los atributos del recurso (por ejemplo, sku, product, unitType), se garantiza que aunque traigamos el mismo registro 100 veces, el ID sea siempre idéntico. DataHub usa ese ID para sobrescribir la entrada anterior y así captura cualquier actualización sin duplicar la fila10.
Paso 4: ingesta vs. notificación
Acá es donde se luce CloudFlow: lógica de ramificación para distintas audiencias.
Para la máquina (DataHub):
Enviamos los datos granulares, a nivel de línea (con los IDs que generamos), directamente al paso uploadDataHub. Así nuestra plataforma de analítica cuenta con datos de la mayor fidelidad posible para profundizar en los costos por repositorio o SKU.
Para el humano (notificaciones):
No queremos saturar nuestros canales de Ops con miles de líneas de JSON. En paralelo a la subida, ejecutamos un aggregateDaily. Este código itera por los ítems y suma el netAmount para armar un resumen limpio.
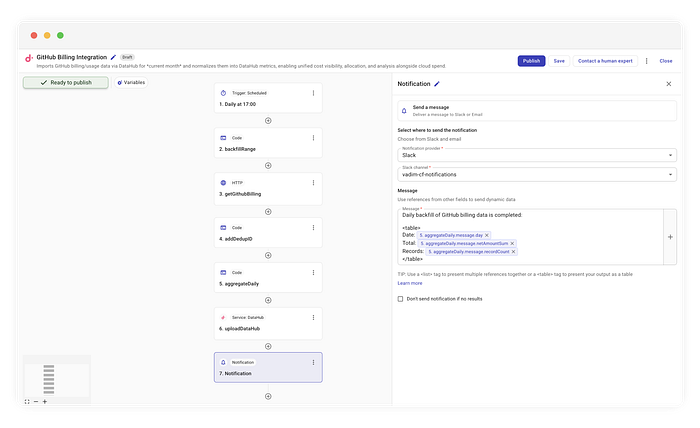
Ejemplo de notificación en Slack
Aunque en el ejemplo usamos Slack, lo bueno de este flujo es que el destino de la notificación es completamente agnóstico. Puedes enviar el resumen a la herramienta que use tu equipo:
- Email: para un log de auditoría diario formal.
- Amazon SNS: para disparar funciones Lambda posteriores.
- Microsoft Teams: usando un conector webhook.
- HTTP genérico: para hacer POST del resumen a cualquier dashboard interno.
En nuestro caso, simplemente formateamos los datos agregados en una tabla legible y la enviamos.
Backfill diario de datos de facturación de GitHub completado:
| Fecha | Total | Registros |
|------------|---------|-----------|
| 2023-10-01 | $45.20 | 120 |
| 2023-10-02 | $48.10 | 135 |
Esta separación de responsabilidades —datos granulares para el warehouse, datos agregados para los humanos— deja contentos tanto a tus equipos de FinOps como de DevOps.
El resultado — **_Gobernanza y chargeback automatizados._**
Ingestar estos datos en DataHub habilita flujos de FinOps que las APIs en crudo no pueden soportar. Primero, el dataset queda monitoreado de forma automática por algoritmos de Detección de Anomalías. Si una mala configuración en un pipeline de CI/CD provoca un pico de cómputo, el sistema identifica la desviación respecto al baseline histórico y genera una alerta. Segundo, los datos quedan disponibles para Asignación de Costos.
Armar integraciones de facturación tiene menos que ver con la conexión a la API y más con el ciclo de vida de los datos. Herramientas como CloudFlow nos permiten modelar ese ciclo de vida de forma visual y resolver problemas complejos como las actualizaciones retroactivas sin tener que escribir un motor ETL a medida desde cero.
Al implementar un patrón de "Backfill por defecto", dejas de pelearte con tu equipo de finanzas porque los números no cuadran y vuelves a confiar en tus datos.
Este flujo se construyó con CloudFlow, parte del portfolio de DoiT Cloud Intelligence ™.