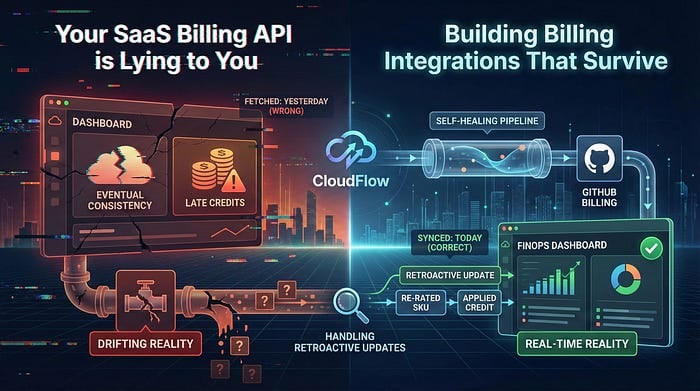
Si vous développez des intégrations de facturation pour le FinOps ou le CloudOps, j'ai une mauvaise nouvelle : les données que vous venez de récupérer via cette API SaaS sont probablement fausses.
Pas à cause d'un bug, mais à cause du fonctionnement même de la facturation cloud. Le metering de l'usage est souvent à cohérence à terme. Les crédits sont appliqués tardivement. Les SKU sont retarifés plusieurs jours après coup. Si votre intégration se déclenche une seule fois, récupère les données de la veille et passe à autre chose, votre dashboard FinOps s'éloigne un peu plus de la réalité chaque jour.
Dans cet article, je vais vous montrer comment construire une intégration de facturation qui tient vraiment la route en production.
Nous allons décortiquer un modèle d'intégration GitHub Billing conçu avec CloudFlow, un moteur d'orchestration de données low-code. Au programme, le problème le plus épineux de l'ingestion de facturation : gérer les mises à jour rétroactives sans transformer votre base en cauchemar de doublons.
La stack en bref
Avant de plonger dans le code, voici le contexte des outils utilisés. Vous ne connaissez peut-être pas ces composants, mais les schémas d'architecture s'appliquent à n'importe quel pipeline de données robuste.
- CloudFlow : le moteur qui exécute notre logique. Une plateforme low-code conçue pour bâtir des workflows de facturation et opérationnels sophistiqués sans avoir à gérer d'infrastructure.
- DataHub : notre destination. Le référentiel de données unifié au sein de DoiT Cloud Intelligence™, où cohabitent les données de facturation normalisées d'AWS, Azure, GCP et de sources personnalisées (Databricks, Snowflake, DataDog, etc.) pour permettre l'analyse.
Notre objectif est simple : faire arriver les données de facturation GitHub dans un DataHub FinOps pour les analyser aux côtés de nos autres dépenses cloud et SaaS.
**La vectorisation implicite de CloudFlow**
CloudFlow gère l'itération différemment des orchestrateurs DAG classiques. Il s'appuie sur la vectorisation implicite : si une étape produit un tableau (par exemple une liste de dates), le moteur déploie automatiquement les nœuds suivants en parallèle, sans nécessiter de structures de contrôle for-each ou map explicites.
Le pipeline peut ainsi adapter dynamiquement la concurrence à la taille du payload, en traitant les entrées T[] comme des threads d'exécution parallèles, tout en conservant un graphe visuel linéaire et lisible.
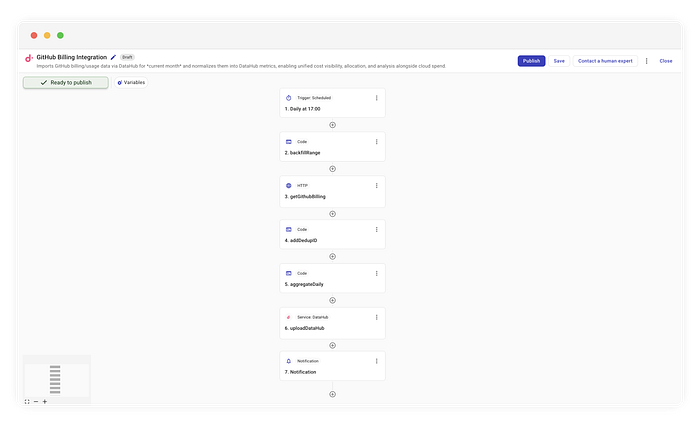
C'est tout ce dont vous avez besoin pour intégrer GitHub à votre stack FinOps.
Le moteur prend par ailleurs en charge la suspension avec état à des fins de gouvernance. Cette intégration de facturation tourne sans surveillance, mais les opérations à effets de bord (comme la suppression de ressources) requièrent souvent une validation Human-in-the-Loop (HITL).
CloudFlow peut suspendre le contexte d'exécution à des nœuds Approval spécifiques, en persistant l'état jusqu'à ce qu'un signal asynchrone — un webhook depuis Slack ou un clic dans un email, par exemple — relance le pipeline.
Le problème : le mythe de l'<em>immuable</em>
La plupart des développeurs construisent leurs pipelines de facturation comme suit :
- Réveil à 01h00 UTC.
- Requête vers l'API pour
date = hier. - Sauvegarde du résultat dans le data warehouse.
Ce schéma part du principe que les données de facturation sont immuables une fois écrites. Ce n'est pas le cas.
Les fournisseurs SaaS mettent fréquemment à jour les enregistrements de facturation du mois en cours. Un pic d'usage du 12 peut ne pas être totalement réconcilié avant le 15. Si vous n'avez récupéré les données du 12 que le 13, la mise à jour vous échappe.
Pour corriger cela, il faut une stratégie de fenêtre de re-polling. Au lieu de récupérer la veille, on récupère le Month-to-Date (MTD) chaque jour.
L'architecture
Nous allons construire un flux qui s'exécute quotidiennement mais retraite l'intégralité du mois en cours à chaque passage. Si GitHub a mis à jour le coût du 1er du mois le 20, on le récupère.
Flux complet implémentant l'intégration de la facturation GitHub
Voici la logique générale que nous allons implémenter dans CloudFlow :
- Planification : exécution quotidienne à 10h ET.
- Calcul de la fenêtre : détermination de la plage (du jour 1 au jour courant).
- Récupération (fan-out) : requête à l'API pour chaque jour de la fenêtre.
- Déduplication (cruciale) : génération d'identifiants déterministes pour éviter les doublons.
- Ingestion : upsert des données détaillées dans DataHub.
- Notification : agrégation séparée des totaux pour produire un résumé lisible par un humain.
Construisons cela étape par étape.
Étape 1 : la fenêtre glissante (le <em>backfill</em>)
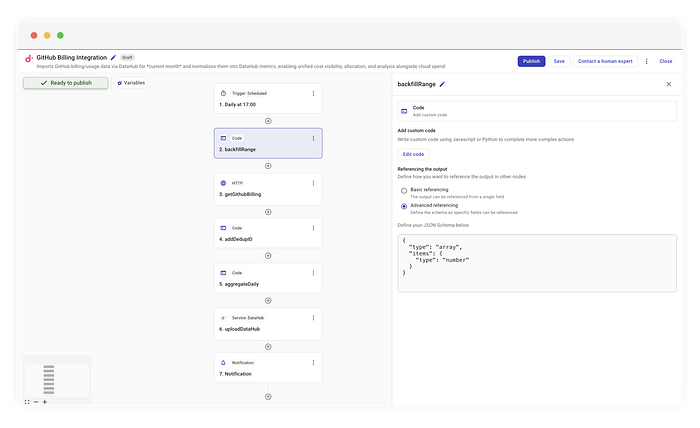
Nous partons d'un trigger cron classique qui s'exécute quotidiennement à 17h04. Mais plutôt que de transmettre hier à notre étape API, nous utilisons une étape de code personnalisée appelée backfillRange.
Cette étape génère un tableau des jours représentant l'ensemble du mois écoulé jusqu'à présent.
Extraction du nombre de jours à traiter
// Logique simplifiée de l'étape 'backfillRange'
const now = new Date();
const startDay = 1;
const endDay = now.getUTCDate();
// Génère un tableau [1, 2, ..., endDay]
const days = Array.from({ length: endDay }, (_, i) => startDay + i);
return days;
Pourquoi c'est important : en retournant un tableau, CloudFlow déclenche automatiquement un fan-out. Les étapes suivantes s'exécutent une fois par jour du tableau. Le 30 du mois, ce flux tourne 30 fois et rafraîchit l'intégralité de l'historique de facturation pour la période.
Le schéma de sortie Pour permettre aux nœuds en aval de valider et d'autocompléter vos données, vous définissez un schéma de sortie. Ce schéma modélise strictement la valeur JSON renvoyée par votre nœud (par exemple un tableau de chaînes ou un objet précis), en ignorant volontairement les wrappers d'exécution internes ou les métadonnées de CloudFlow. En définissant la forme de manière récursive, en correspondance exacte avec votre objet ou tableau de plus haut niveau, vous créez un contrat type-safe qui garantit que le reste du pipeline reçoit exactement ce qu'il attend.
Étape 2 : appels d'API paramétrés
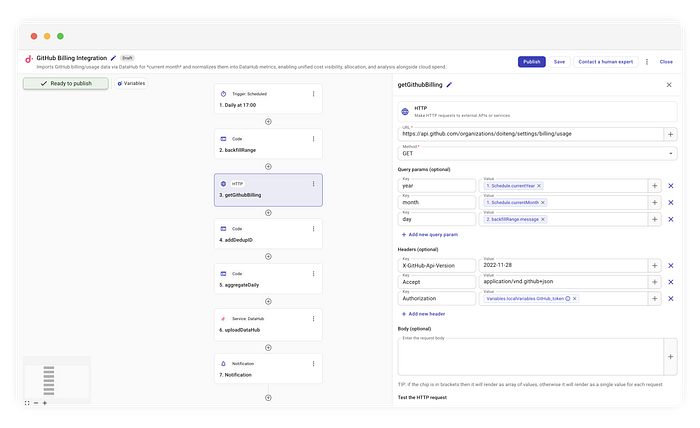
Nous utilisons ensuite un connecteur HTTP standard pour interroger le endpoint GitHub :
GET https://api.github.com/organizations/{org}/settings/billing/usage
Appel de l'API GitHub Billing
Nous injectons dynamiquement le day issu de l'étape précédente dans les paramètres de la requête :
year:{CurrentYear}month:{CurrentMonth}day:{backfillRange.message}(l'élément courant de notre boucle)
Nous respectons ainsi la structure de l'API GitHub tout en conservant la flexibilité de notre fenêtre glissante.
Étape 3 : la clé d'idempotence (la <em>recette secrète</em>)
C'est là que la plupart des intégrations échouent.
Si vous récupérez les données du 1er janvier trente fois au cours du mois, pas question de les ajouter telles quelles à votre base de données. Vous vous retrouveriez avec un coût multiplié par 30. Il vous faut une stratégie d'upsert (mise à jour si l'enregistrement existe, insertion sinon).
Pour le faire de façon fiable, il vous faut un identifiant déterministe — une empreinte pour chaque ligne de facturation. Nous ajoutons une étape de code appelée addDedupID.
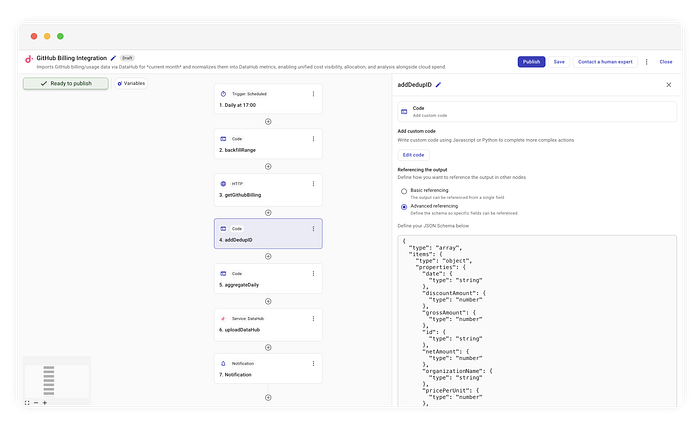
Création de hashes pour la déduplication
Nous examinons les données brutes et hachons les champs immuables pour produire cet identifiant.
// Logique interne d''addDedupID'
const { createHash } = require("crypto");
function computeUsageItemId(usageItem) {
// N'extraire que les champs string qui définissent la ressource (produit, SKU, type d'unité, etc.)
const stringFields = extractStringFields(usageItem);
// Création d'un hash SHA256
return createHash("sha256")
.update(canonicalStringify(stringFields))
.digest("hex"); // [cite: 144, 145]
}
En calculant un hash basé sur les attributs de la ressource (par exemple sku, product, unitType), nous garantissons que même si nous récupérons le même enregistrement 100 fois, l'identifiant reste strictement identique. DataHub utilise cet ID pour écraser l'entrée précédente, ce qui permet de capturer les mises à jour sans dupliquer la ligne.
Étape 4 : ingestion ou notification
C'est ici que toute la puissance de CloudFlow se révèle : une logique de branchement adaptée à différents publics.
Pour la machine (DataHub) :
Nous envoyons les données granulaires à la ligne (avec nos identifiants générés) directement à l'étape uploadDataHub. Notre plateforme analytique dispose ainsi des données les plus fidèles possibles pour explorer les coûts par dépôt ou par SKU.
Pour l'humain (notifications) :
Hors de question d'inonder nos canaux Ops avec des milliers de lignes JSON. En parallèle de l'upload, nous exécutons un aggregateDaily. Ce code parcourt les éléments et somme le netAmount pour produire un résumé propre.
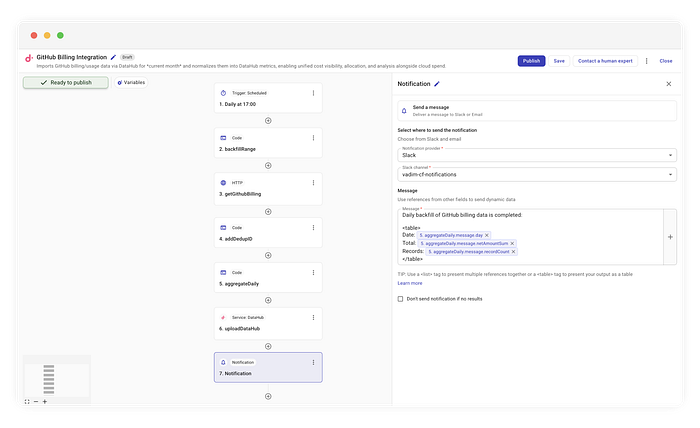
Exemple de notification Slack
Notre exemple utilise Slack, mais l'avantage de ce flux, c'est que la destination de la notification est totalement agnostique. Vous pouvez router ce résumé vers l'outil utilisé par votre équipe :
- Email : pour un journal d'audit quotidien formel.
- Amazon SNS : pour déclencher des fonctions Lambda en aval.
- Microsoft Teams : via un connecteur webhook.
- HTTP générique : pour POSTer le résumé vers n'importe quel dashboard interne.
Dans notre cas, nous formatons simplement les données agrégées dans un tableau lisible, et nous l'envoyons.
Backfill quotidien des données de facturation GitHub terminé :
| Date | Total | Enregistrements |
|------------|---------|-----------------|
| 2023-10-01 | 45,20 $ | 120 |
| 2023-10-02 | 48,10 $ | 135 |
Cette séparation des responsabilités — données granulaires pour le warehouse, données agrégées pour les humains — satisfait à la fois vos équipes FinOps et DevOps.
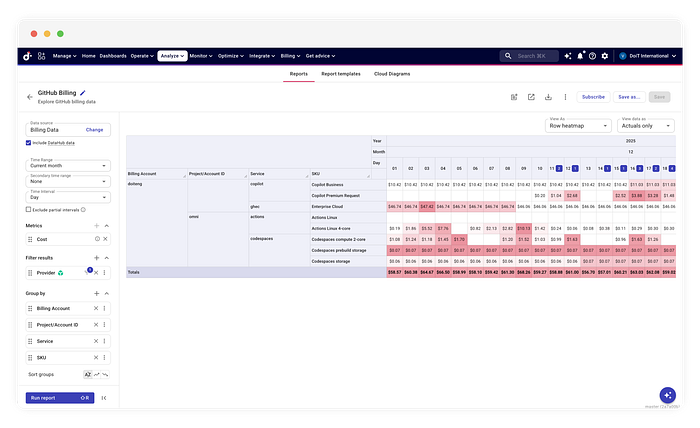
Le résultat — **_Gouvernance automatisée et chargeback._**
L'ingestion de ces données dans DataHub permet d'activer des workflows FinOps en aval que les API brutes ne peuvent pas prendre en charge. D'abord, le jeu de données est automatiquement surveillé par les algorithmes d'Anomaly Detection. Si une mauvaise configuration de pipeline CI/CD provoque un pic de calcul, le système identifie l'écart par rapport à la baseline historique et génère une alerte. Ensuite, les données deviennent disponibles pour la Cost Allocation.
Construire des intégrations de facturation, c'est moins une affaire de connexion à une API qu'une question de cycle de vie de la donnée. Des outils comme CloudFlow permettent de modéliser ce cycle de vie visuellement, et de résoudre des problèmes complexes comme les mises à jour rétroactives sans avoir à écrire un moteur ETL sur mesure depuis zéro.
En adoptant l'approche Backfill by Default, vous arrêtez de vous battre avec votre équipe finance pour expliquer pourquoi les chiffres ne tombent pas juste, et vous recommencez à faire confiance à vos données.
Ce workflow a été construit avec CloudFlow, qui fait partie du portefeuille DoiT Cloud Intelligence ™.