Kubernetesを使えば、アプリケーションを動かすPodのオーケストレーションは簡単です。しかし、Podが動くクラスター自体はどうでしょうか。各クラウドで適切に構成するには手作業による調整が欠かせず、特にあるクラウドのクラスター構成を別のクラウドに複製しようとすると一気に難易度が上がります。
本記事では、Azure、Google、Amazonのクラスターモデルを比較し、同一クラウド内およびクラウド間でクラスターをクローンするためのツールをご紹介します。

世界初のクローン哺乳類、ドリー
Kubernetesを使えば、アプリケーションの管理は簡単です。Kubernetesコントローラーが、メモリ、ディスク、ロードバランサー、サーバーの冗長インスタンスなど、アプリケーションに必要なリソースを確保してくれます。すべてが標準化・自動化されているため、インフラプロバイダーの切り替えもほとんど変更を加えずに行えます。
Kubernetesの抽象化はインフラ層を意識せずに済むようにしてくれますが、インフラそのものはなくなりません。クラスターのノードは結局のところVMにすぎず、これらはクラウドプロバイダー間で標準化されていないのです。初めて触れる人にとっては悩ましいところでしょう。Kubernetesの他の部分はこれほど標準化・自動化されているのに、なぜ各クラウドで異なる形でモデル化されたリソースやAPIをいちいち把握しなければならないのか、と。
AWS Fargate、Google Cloud Run、Azure Container Instancesといったサーバーレスコンテナアーキテクチャは、(制御性と引き換えに)インフラの扱いを楽にしてくれますが、Kubernetesに期待するようなクラウド横断の標準化までは提供してくれません。標準のKubernetesクラスターを立ち上げるなら、標準化されていないクラスターインフラのモデルを理解しておく必要があります。
そこで登場するのがCluster Clonerです。クラウド間、または同一クラウド内でクラスターをコピーできるオープンソースツールで、本記事ではこれを使ってGoogle Kubernetes Engine、Azure Kubernetes Service、AWSのElastic Kubernetes Serviceにおけるクラスター実装を比較していきます。
Cluster Clonerとは
クラスターのKubernetes構成をクローンしたい場合は、Heptio Veleroが使えます。完全な構成はKubernetesのetcdに保存されているため、これは比較的容易に行えます。ただしその前に、クラスターの仮想マシンや、Kubernetesが動作する基盤となるリソースをコピーする必要があります。Cluster Clonerは私がGoで開発したコマンドラインツールで、Dockerイメージとスタンドアロンアプリケーションのいずれでも利用できます。
Terraformなどのinfrastructure-as-codeツールを使っていれば、クラスターのコピーで困ることはありません。同じコードを(必要に応じて調整しつつ)実行すればよいだけです。しかし、それ以外の方法で作られたクラスターの場合は、あるクラウドでモデル化されたクラスターを読み解き、別のクラウドのモデルへ変換できるツールが必要になります。
Cluster Clonerには2通りの使い方があります。クラスターを直接コピーする方法と、「ドライラン」として中間ステップを挟み、処理を細かく調整できる方法です。
オプション \#1: 直接クローン
クラスターをコピーするには、clusterclonerを実行し、入力クラウドと「スコープ」を指定します(スコープはGoogleプロジェクトまたはAzureリソースグループのことで、AWSでは不要です)。
入力ロケーションも指定します。AWSとAzureではリージョンを、Googleではゾーンクラスターの場合はゾーン名、マルチゾーンのリージョナルクラスターの場合はリージョン名を指定します。
同様に、出力クラウドと、AzureまたはGCPの場合は出力スコープも指定します。
各処理には数分かかることがあるため(詳細は後述)、デフォルトではドライラン動作になります。実際にクラスターを作成するには--nodryrunを指定してください。
Cluster Clonerは指定したロケーション内のすべてのクラスターをコピーしますが、--labelfilterでカンマ区切りのキーと値のペアを指定すれば、対象を絞り込めます。この場合、すべてのラベルが一致したクラスターだけがコピーされます。
コマンドラインの例:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
コマンドラインの詳細はclustercloner --helpで確認できます。開発方法、ユニットテストおよび統合テストの実行、バイナリやDockerイメージのビルド方法についてはREADMEファイルをご覧ください。
オプション \#2: クローン処理のカスタマイズ
クローン処理をカスタマイズすることもできます。Cluster Clonerは常にターゲットクラスターの定義をJSON形式で出力します。--nodryrunを省略してドライランを実行し、出力されたJSONを希望するクラスター仕様に合わせて編集してください。その後、編集したJSONファイル名を--inputfileオプションの引数として渡し、再度clusterclonerを実行すれば、ファイルに定義されたクラスターが作成されます。
EKS、AKS、GKE: 共通点と相違点
Cluster Clonerは、大きく異なる3つのクラスターインフラモデルの橋渡しを目的に作られています。続いて、Google、AWS、Azureでクラスターを構成する基本要素を比較してみましょう。
ただし、3つのクラウドプロバイダーは互いに追いつき追い越せの競争を繰り広げているため、本記事では高度な機能の比較は扱いません。また、本記事はCluster Clonerをベースとしており、コアモデルのうち互換性のある部分の変換に焦点を当てています。GKEのマスター承認済みネットワークやAlphaクラスターのように、特定のクラウドの設計に固有のモデル要素はコピー対象外です。
クラスターモデルの比較
用語
まずは用語から見ていきましょう。APIで表現されるクラスターモデルの比較のなかで、もっとも分かりやすい部分です。
3つのクラウドでは、以下のような用語が使われています。Cluster Cloner内部では、KubernetesプロジェクトがGoogle発祥であることを踏まえ、基本的にGKEの用語を使用しています。
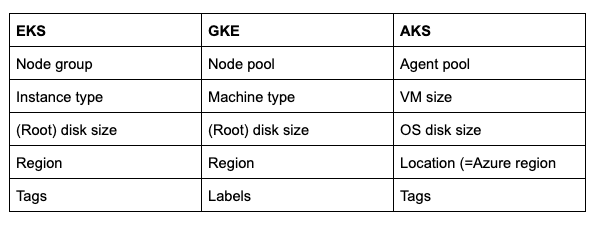
用語
クラスターとノードプールのモデル
Kubernetesのバージョン
- GKEとAKSは複数のパッチバージョンをサポートしており、Cluster ClonerはそのAPIを利用しています。
- Cluster Clonerはメジャーバージョンとマイナーバージョンを変更しません。AKSとGKEでパッチバージョンを選ぶ際には、ソースクラスターのバージョン以上で最も小さいパッチバージョンを選び、それが不可能な場合は最大のパッチバージョンを選択します。
- EKSはよりシンプルで、4つのマイナーバージョン(現在は1.12、1.13、1.14、1.15)をサポートしており、Cluster Clonerではこれらをハードコードしています。
リージョン
- GKEはすべてのGoogleリージョンでクラスターをサポートしています。
- EKSは一部を除くすべてのリージョンでクラスターをサポートしています。
- AKSはサポート対象が指定されたリージョンのリストに限られます。
- とはいえ、各クラウドとも世界各地でKubernetesをサポートしています。Cluster Clonerは変換テーブルに基づき、近隣のリージョンを自動的に選択します。
ゾーン
- EKSとAKSではクラスターはリージョン単位で定義されますが、各ノードグループのサブネットを選ぶことで可用性ゾーンに割り当てられます。
- GKEではゾーンクラスターまたはマルチゾーンのリージョナルクラスターを作成できます。
- Cluster Clonerはゾーン選択をGKEでのみサポートしています。
マシンタイプ
- Cluster Clonerでは変換にシンプルなアプローチを採用しています。ターゲットクラウドで「最小上界」となるマシン(インスタンス)タイプを探す方式です。つまり、CPUとRAMがいずれもソースマシンタイプを下回らない範囲で、可能な限り小さいCPUとRAMを持つマシンタイプを選びます(該当タイプは必ずしも一意に決まるとは限りません)。
- マシンタイプの変換は一筋縄ではいきません。CPUとRAM以外にも、CPUやGPUモデルの選択、IO性能、そして重要なポイントとしてメモリ最適化型・CPU最適化型といったトレードオフなど、さまざまな特性で違いがあるためです。これらの特性を考慮することは、Cluster Clonerの今後の課題となっています。
処理速度
Cluster Clonerでは各クラウドで同じ処理を行うため、処理速度を比較するのに格好の機会となります。下のチャートをご覧ください。
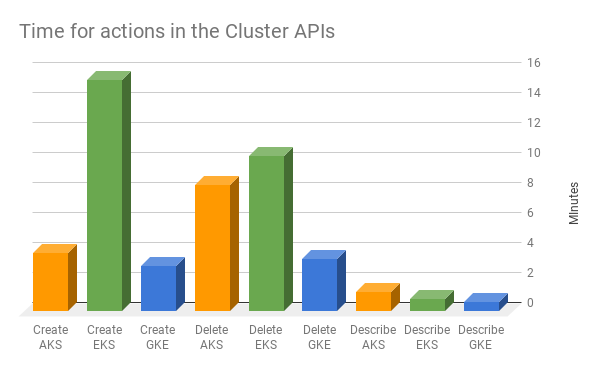
所要時間
数分余計に待つこと自体は致命的ではありませんが、Podのようにクラスターを扱う、つまり「ペットではなく家畜」として気軽に削除・再作成するという感覚には影響します。
EKS APIの内側
Cluster Clonerはクラスターとノードグループの作成・削除にeksctlを使っています。eksctlはAPI利用を前提に設計されたコマンドラインツールではないため、Cluster Clonerはコマンドラインのエントリーポイントでこれをラップしています。作成にeksctlを採用しているのは、クラスターに必要な基盤リソースをすべて生成してくれる賢さがあるからです。これにはVPC、可用性ゾーンをまたぐサブネット、セキュリティグループが含まれます。同じくらい重要なのが、eksctlがこれらのリソースを正しい順序(まずネットワークインターフェース、次にVPC、最後にEC2 VMインスタンス)で削除できる点です。
一方、クラスターの読み取りにはCluster Clonerはeksctlを使っていません。eksctlではクラスターとノードグループの詳細モデル全体を取得できないためです。eksctlが現在AWSの推奨するクラスター管理ツールであることを考えると、これは意外な点です。この制約は、EKSではEC2のインフラ層(インスタンス、サブネット、VPC)が他のクラウドよりも前面に出ており、ノードやノードグループといったKubernetes関連の抽象化に隠されていないことに起因します。それでも情報を取得する手段はあり、Cluster ClonerはAWS SDK for Goを使ってクラスターとノードグループを記述するのに必要なデータをすべて取得しています。
今後の展望
クラスターモデルは3つのプロバイダーいずれも機能が豊富で、Cluster Clonerがまだサポートしていない構成オプションも数多くあります。
機能リストには、Cluster Clonerでコピーできる項目と未実装の項目がまとめられています。例えば次のとおりです。
- Kubernetesのバージョンとタグは、クラスター単位だけでなくノードプール単位でもコピーできるようにすべきです。
- オートスケーリングの定義もコピー対象に含めるべきです。
- スポットインスタンスはGKEとAKSだけでなく、EKSでもサポートすべきです。
追加してほしい機能があれば、GitHubでプルリクエストを送るか、GitHub issueを立てて、ぜひプロジェクトにご協力ください。