Kubernetes rende semplice orchestrare i pod su cui girano le applicazioni. Ma i cluster su cui girano i pod? Quelli richiedono ben più attenzione manuale per essere configurati correttamente sui diversi cloud, soprattutto quando si tratta di clonare la configurazione di un cluster da un cloud all'altro.
In questo articolo metto a confronto i modelli di cluster di Azure, Google e Amazon e presento uno strumento per clonare i cluster all'interno di un singolo cloud o tra cloud diversi.

Dolly, il primo mammifero clonato
Con Kubernetes gestire un'applicazione è semplice: il controller Kubernetes garantisce che l'applicazione abbia tutte le risorse necessarie, dalla memoria al disco, fino ai load balancer e alle istanze ridondanti dei server. È tutto standardizzato e automatizzato, e cambiare provider di infrastruttura richiede modifiche minime.
L'astrazione di Kubernetes isola dal livello infrastrutturale, ma l'infrastruttura resta lì. I nodi di un cluster sono semplici VM, che non sono standardizzate tra i vari cloud provider. Per chi è alle prime armi è frustrante: perché bisogna scoprire risorse e API necessarie, modellate in modo diverso sui vari cloud, quando tutto il resto in Kubernetes è così standard e automatizzato?
Le architetture serverless per container come AWS Fargate, Google Cloud Run e Azure Container Instances semplificano la gestione dell'infrastruttura (al prezzo di un controllo minore), ma non offrono la standardizzazione cross-cloud che ci si aspetta da Kubernetes. Se si avviano cluster Kubernetes standard, bisogna comprendere i modelli infrastrutturali non standard dei cluster.
Da qui nasce Cluster Cloner, uno strumento open-source capace di copiare i cluster da un cloud all'altro o all'interno di un singolo cloud. Lo userò per confrontare le implementazioni dei cluster in Google Kubernetes Engine, Azure Kubernetes Service ed Elastic Kubernetes Service di AWS.
Cluster Cloner in breve
Per clonare la configurazione Kubernetes di un cluster si può usare Heptio Velero. L'etcd di Kubernetes rende l'operazione lineare, perché è lì che è memorizzata l'intera configurazione. Prima però bisogna copiare le macchine virtuali del cluster e le altre risorse su cui Kubernetes gira. Cluster Cloner è uno strumento da riga di comando che ho sviluppato in Go, disponibile sia come immagine Docker sia come applicazione standalone.
Chi usa Terraform o altri strumenti di infrastructure-as-code non avrà problemi a copiare i cluster: basta eseguire lo stesso codice (con i dovuti aggiustamenti). Ma se un cluster è stato creato in altro modo, serve uno strumento in grado di interpretare il cluster come modellato in un cloud e tradurlo nel modello di un altro.
Cluster Cloner si può usare in due modi: copiando direttamente un cluster, oppure in modalità "dry run", con un passaggio intermedio che permette di mettere a punto il processo.
Opzione \#1: clonazione diretta
Per copiare i cluster, eseguire clustercloner specificando il cloud di input e lo "scope". (Lo scope è il progetto Google o il Resource Group di Azure; in AWS non serve.)
Va indicata anche la location di input. In AWS e Azure si tratta della region. In Google, indicare il nome della zona per i cluster zonali e il nome della region per i cluster regionali multizona.
Allo stesso modo, specificare il cloud di output e, per Azure o GCP, lo scope di output.
Poiché ogni operazione può richiedere diversi minuti (dettagli più avanti), per default la creazione è un dry run. Specificare --nodryrun per creare effettivamente i cluster.
Cluster Cloner copia tutti i cluster nella location indicata, ma è possibile restringere la copia con --labelfilter, passando un elenco di coppie chiave-valore separate da virgola. In questo caso un cluster viene copiato solo se tutte le label corrispondono.
Un esempio di riga di comando:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
La documentazione sulla riga di comando è disponibile con clustercloner --help. La documentazione su sviluppo, esecuzione dei test unitari e di integrazione e build del binario e dell'immagine Docker si trova nel file README.
Opzione \#2: personalizzare la clonazione
Il processo si può anche personalizzare. Cluster Cloner produce sempre in output una descrizione del cluster di destinazione in formato JSON. È quindi sufficiente eseguire un dry run omettendo --nodryrun e modificare il JSON di output come specifica del cluster desiderato. Poi rieseguire clustercloner, indicando il nome del file JSON come argomento dell'opzione --inputfile. I cluster definiti nel file verranno così creati.
EKS, AKS e GKE: somiglianze e differenze
Cluster Cloner è progettato per fare da ponte tra i tre modelli, molto diversi tra loro, di infrastruttura per i cluster. Confrontiamo ora gli elementi di base che compongono un cluster in Google, AWS e Azure.
Non confronteremo invece le funzionalità avanzate, dato che i tre cloud provider si rincorrono di continuo per restare al passo l'uno con l'altro. Inoltre, questo articolo si basa su Cluster Cloner, che si concentra sulla trasformazione delle parti compatibili dei modelli di base. Alcuni aspetti dei modelli non vengono copiati perché specifici della progettazione di un determinato cloud, come le master authorized networks e gli Alpha cluster di GKE.
I modelli di cluster a confronto
Terminologia
Partiamo dalla terminologia, la parte più semplice del confronto tra i modelli di cluster, così come emergono dalle API.
Nei tre cloud troviamo i termini seguenti. All'interno di Cluster Cloner si usa generalmente la terminologia di GKE, in riconoscimento dell'origine del progetto Kubernetes in Google.
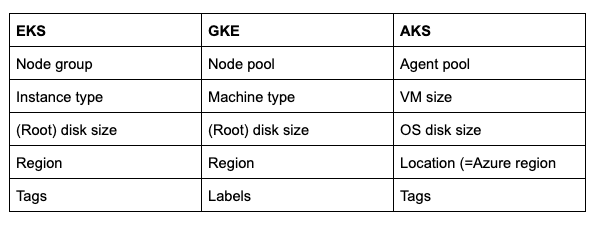
Terminologia
Modello di cluster e node pool
Versioni di Kubernetes
- GKE e AKS supportano un elenco di versioni patch, disponibili tramite le API che Cluster Cloner utilizza.
- Cluster Cloner non tenta mai di cambiare la versione major e minor. Per scegliere una versione patch in AKS e GKE, Cluster Cloner cerca la versione patch più bassa pari o superiore a quella del cluster di origine; se non è possibile, sceglie la versione patch più alta disponibile.
- EKS è più semplice: supporta quattro versioni minor, attualmente 1.12, 1.13, 1.14 e 1.15, che Cluster Cloner ha in hard-coded.
Region
- GKE supporta cluster in tutte le region di Google.
- EKS supporta cluster in quasi tutte le region, con poche eccezioni.
- AKS supporta solo un elenco specifico di region.
- Ciascun cloud, in ogni caso, supporta Kubernetes in aree geografiche di tutto il mondo. Cluster Cloner sceglie automaticamente una region vicina sulla base di una tabella di conversione.
Zone
- In EKS e AKS i cluster sono definiti a livello regionale, ma possono essere assegnati alle availability zone scegliendo le subnet per ciascun node group.
- GKE consente di creare cluster zonali oppure cluster regionali multizona.
- Cluster Cloner supporta la scelta della zona solo in GKE.
Tipi di macchina
- Cluster Cloner adotta un approccio semplice per la conversione: individua nel cloud di destinazione il tipo di macchina (istanza) corrispondente al minimo estremo superiore, ovvero un tipo di macchina con CPU e RAM più basse possibile, ma comunque non inferiori a quelle del tipo di macchina di origine. (La scelta non è necessariamente univoca.)
- I tipi di macchina sono difficili da convertire perché differiscono per caratteristiche diverse da CPU e RAM: il modello di CPU e GPU, le prestazioni di IO e, soprattutto, compromessi come i tipi memory-optimized e CPU-optimized. Tenere conto di queste caratteristiche è nella to-do list di Cluster Cloner.
Tempi di esecuzione
Cluster Cloner offre un'ottima occasione per misurare i tempi, dato che la stessa azione viene eseguita su ciascun cloud. Vedi il grafico qui sotto.
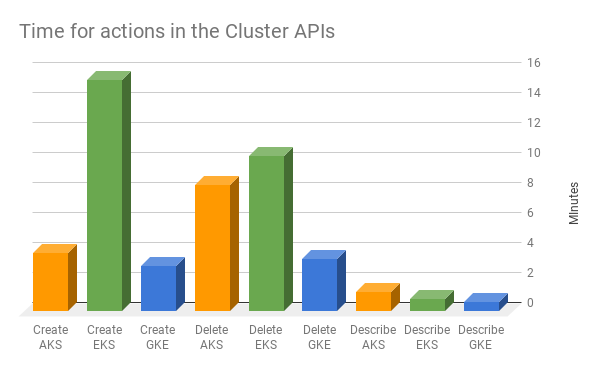
Tempi
Aspettare qualche minuto in più non è certo un ostacolo insormontabile, ma incide sulla possibilità di trattare i cluster come si è abituati a trattare i pod, cioè come "bestiame, non animali domestici", da eliminare e ricreare a piacimento.
Pregi e limiti delle API di EKS
Cluster Cloner usa eksctl per creare ed eliminare cluster e node group. Dato che eksctl è uno strumento da riga di comando non pensato per l'uso via API, Cluster Cloner lo incapsula al punto di ingresso della riga di comando. Lo usiamo per la creazione perché è abbastanza intelligente da generare tutte le risorse sottostanti necessarie a un cluster: una VPC, subnet distribuite tra le availability zone e security group. Altrettanto importante, eksctl sa smantellare queste risorse nell'ordine corretto: prima le network interface, poi la VPC e solo alla fine le istanze VM EC2.
Per la lettura dei cluster, invece, Cluster Cloner non usa eksctl, che non è in grado di descrivere il modello completo e dettagliato di cluster e node group. La cosa sorprende, considerato che eksctl è oggi lo strumento consigliato da AWS per gestire i cluster. Il limite deriva dal fatto che in EKS il livello infrastrutturale (EC2 con istanze, subnet e VPC) è molto più visibile rispetto agli altri cloud, e meno nascosto dietro astrazioni Kubernetes come nodi e node group. Le informazioni sono comunque disponibili: Cluster Cloner sfrutta l'AWS SDK for Go per ottenere tutti i dati necessari a caratterizzare cluster e node group.
Cosa ci aspetta
Il modello di cluster, in tutti e tre i provider, è ricco e offre opzioni di configurazione non ancora supportate da Cluster Cloner.
L'elenco delle funzionalità mostra ciò che Cluster Cloner sa copiare e gli aspetti non ancora implementati, ad esempio:
- Le versioni di Kubernetes e i tag dovrebbero essere copiati a livello di node pool, non solo a livello di cluster.
- Le definizioni di autoscaling dovrebbero essere copiate.
- Le istanze Spot dovrebbero essere supportate anche in EKS, non solo in GKE e AKS, e fin da oggi.
Se vuoi una funzionalità in particolare, contribuisci pure con una pull request su GitHub o apri una issue su GitHub.