Con Kubernetes orquestar los pods que ejecutan tus aplicaciones es muy sencillo. ¿Pero qué pasa con los clusters sobre los que corren esos pods? Ahí hace falta mucho más trabajo manual para configurarlos bien en cada nube y, sobre todo, para clonar la configuración de un cluster de una nube a otra.
En este artículo comparo los modelos de cluster en Azure, Google y Amazon, y presento una herramienta para clonar clusters dentro de una misma nube o entre nubes distintas.

Dolly, el primer mamífero clonado
Con Kubernetes, gestionar tu aplicación es fácil: el controlador de Kubernetes se encarga de que tu aplicación cuente con los recursos necesarios, como memoria, disco, balanceadores de carga e instancias redundantes de tus servidores. Todo está estandarizado y automatizado, y puedes cambiar de proveedor de infraestructura prácticamente sin tocar nada.
La abstracción de Kubernetes te aísla de la capa de infraestructura, pero la infraestructura sigue ahí. Los nodos de un cluster son simplemente VMs, y estas no están estandarizadas entre los distintos proveedores de nube. Para quien recién empieza, esto es frustrante. ¿Por qué hay que descifrar los recursos y las APIs necesarios, modelados de forma distinta en cada nube, cuando todo lo demás en Kubernetes es tan estándar y automatizado?
Las arquitecturas de contenedores serverless como AWS Fargate, Google Cloud Run y Azure Container Instances facilitan el manejo de la infraestructura (a costa de menor control), pero no ofrecen la estandarización entre nubes que esperarías de Kubernetes. Si vas a lanzar clusters estándar de Kubernetes, tienes que entender los modelos no estándar de la infraestructura de los clusters.
Esto nos lleva a Cluster Cloner, una herramienta open-source que permite copiar clusters de una nube a otra, o dentro de una misma nube. La voy a usar para comparar las implementaciones de clusters en Google Kubernetes Engine, Azure Kubernetes Service y Elastic Kubernetes Service de AWS.
Conoce Cluster Cloner
Si quieres clonar la configuración de Kubernetes de tu cluster, puedes usar Heptio Velero. El etcd de Kubernetes lo vuelve directo, ya que ahí se almacena toda la configuración. Pero antes de eso, hay que copiar las máquinas virtuales del cluster y los demás recursos sobre los que corre Kubernetes. Cluster Cloner es una herramienta de línea de comandos que desarrollé en Go, disponible tanto como imagen de Docker como aplicación independiente.
Si usas Terraform u otras herramientas de infrastructure-as-code, copiar clusters no es problema: basta con ejecutar el mismo código (con los ajustes pertinentes). Pero cuando un cluster se creó de otra forma, necesitas una herramienta capaz de entender el cluster tal como está modelado en una nube y traducirlo al modelo de otra nube.
Puedes usar Cluster Cloner de dos formas: copiando directamente un cluster, o como un "dry run", con un paso intermedio que te permite ajustar el proceso.
Opción \#1: clonado directo
Para copiar clusters, ejecuta clustercloner, especificando la nube de origen y el "scope". (El scope es el proyecto de Google o el Resource Group de Azure; en AWS no se necesita.)
También hay que indicar la ubicación de origen. En AWS y Azure es la región. En Google, indica el nombre de la zona para clusters zonales y el nombre regional para clusters regionales multizona.
De la misma forma, especifica la nube de destino y el scope de salida para Azure o GCP.
Como cada acción puede tomar varios minutos (más detalles abajo), por defecto la creación se hace como dry run. Especifica --nodryrun para crear los clusters de verdad.
Cluster Cloner copia todos los clusters de la ubicación indicada, pero puedes restringir la copia con --labelfilter y una lista de pares clave-valor separados por coma. En ese caso, todas las labels deben coincidir para que un cluster se copie.
Un ejemplo de línea de comandos:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
La documentación de la línea de comandos está disponible con clustercloner --help. La documentación sobre desarrollo, ejecución de tests unitarios y de integración, y construcción del binario y la imagen de Docker está en el archivo README.
Opción \#2: personaliza el clonado
También puedes personalizar el proceso. Cluster Cloner siempre genera una descripción del cluster destino en JSON. Entonces, haz un dry run omitiendo --nodryrun y edita el JSON resultante como especificación del cluster que quieres. Después ejecuta clustercloner de nuevo, pasando el nombre del archivo JSON como argumento de la opción --inputfile. Así se crearán los clusters definidos en el archivo.
EKS, AKS y GKE: similitudes y diferencias
Cluster Cloner está pensado para tender un puente entre los tres modelos de infraestructura de cluster, que son muy distintos entre sí. A continuación, comparemos los elementos básicos que componen un cluster en Google, AWS y Azure.
Eso sí, no vamos a comparar las funciones avanzadas, ya que los tres proveedores de nube viven en una carrera constante por mantenerse al día entre sí. Además, este artículo se basa en Cluster Cloner, que se enfoca en transformar las partes compatibles de los modelos centrales. Algunos aspectos de los modelos no se copian porque son específicos del diseño de una nube en particular, como las master authorized networks de GKE y los Alpha clusters.
Comparación de los modelos de cluster
Terminología
Empecemos por la terminología, la parte más sencilla de la comparación entre los modelos de cluster, tal como se expresa en las APIs.
En las tres nubes tenemos los siguientes términos. Dentro de Cluster Cloner se usa por lo general la terminología de GKE, en reconocimiento al origen del proyecto Kubernetes dentro de Google.
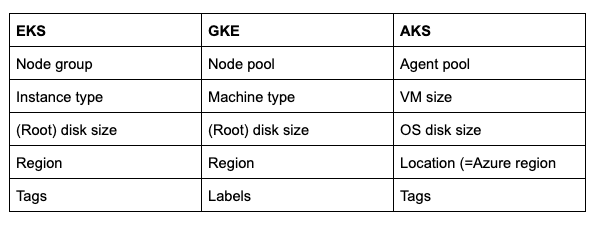
Terminología
Modelo de cluster y node pool
Versiones de Kubernetes
- GKE y AKS soportan una lista de versiones patch, disponibles a través de las APIs que utiliza Cluster Cloner.
- Cluster Cloner nunca intenta cambiar la versión major ni la minor. Para elegir una versión patch en AKS y GKE, busca la menor versión patch que sea igual o mayor a la del cluster origen, o si eso no es posible, la mayor versión patch.
- EKS es más simple: soporta cuatro versiones minor, actualmente 1.12, 1.13, 1.14 y 1.15, que Cluster Cloner tiene hardcoded.
Regiones
- GKE soporta clusters en todas las regiones de Google.
- EKS soporta clusters en casi todas las regiones, salvo unas pocas.
- AKS solo soporta una lista determinada de regiones.
- Aun así, cada nube ofrece Kubernetes en distintas geografías alrededor del mundo. Cluster Cloner elige automáticamente una región cercana usando una tabla de conversión.
Zonas
- En EKS y AKS, los clusters se definen a nivel regional, pero pueden asignarse a availability zones eligiendo las subnets para cada node group.
- GKE te permite crear clusters zonales o clusters regionales multizona.
- Cluster Cloner soporta la elección de zona solo en GKE.
Tipos de máquina
- Cluster Cloner usa un enfoque simple para la conversión: encuentra el tipo de máquina (instancia) que sea la mínima cota superior en la nube destino; es decir, un tipo de máquina con la menor cantidad posible de CPU y RAM, pero sin tener menos que el tipo de máquina origen. (La elección no está necesariamente definida de forma única.)
- Los tipos de máquina son difíciles de convertir, ya que varían en otras características además de CPU y RAM, como el modelo de CPU y GPU, IO y, sobre todo, en compromisos como los tipos memory-optimized y CPU-optimized. Considerar estas características está en la lista de pendientes de Cluster Cloner.
Velocidades
Cluster Cloner ofrece una excelente oportunidad para medir velocidades, ya que se realiza la misma acción en cada nube. Mira el gráfico abajo.
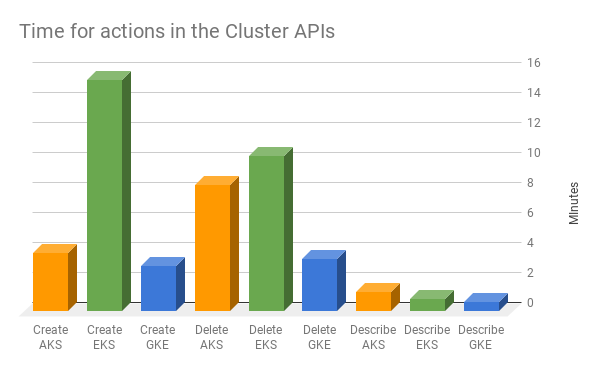
Tiempos
Esperar unos minutos más no tiene por qué ser un impedimento, pero sí afecta tu capacidad de tratar a los clusters como ya estás acostumbrado a tratar a los pods: como "ganado, no mascotas", que se eliminan y se vuelven a crear cuando haga falta.
Los entresijos de las APIs de EKS
Cluster Cloner usa eksctl para crear y eliminar clusters y node groups. Como eksctl es una herramienta de línea de comandos no diseñada para uso vía API, Cluster Cloner la envuelve en el punto de entrada de la línea de comandos. Usamos eksctl para la creación porque es lo bastante inteligente para generar todos los recursos subyacentes que requiere un cluster. Esto incluye una VPC, subnets entre availability zones y security groups. Igual de importante, eksctl puede desmontar estos recursos en el orden correcto: primero las network interfaces, luego la VPC y solo después las instancias EC2 VM.
Para leer los clusters, Cluster Cloner no usa eksctl, que no puede describir el modelo completo y detallado de clusters y node groups. Esto sorprende, ya que eksctl es hoy la herramienta recomendada por AWS para gestionar clusters. La limitación viene de que en EKS la capa de infraestructura (EC2 con instancias, subnets y VPCs) es más visible que en las otras nubes y queda menos oculta por abstracciones propias de Kubernetes, como los nodos y los node groups. Aun así, la información está disponible: Cluster Cloner usa el AWS SDK for Go para obtener todos los datos necesarios para caracterizar clusters y node groups.
Lo que viene
El modelo de cluster, en los tres proveedores, es rico y ofrece opciones de configuración que Cluster Cloner aún no soporta.
La lista de funciones muestra lo que Cluster Cloner sabe copiar, así como los aspectos no implementados, por ejemplo:
- Las versiones y tags de Kubernetes deberían copiarse a nivel de node pool, no solo a nivel de cluster.
- Las definiciones de autoscaling deberían copiarse.
- Las instancias Spot deberían soportarse en EKS, no solo en GKE y AKS, y a día de hoy.
Si quieres una funcionalidad, no dudes en contribuir con un pull request en GitHub o abrir un issue en GitHub.