O Kubernetes facilita a orquestração dos pods que rodam suas aplicações. Mas e os clusters em que esses pods são executados? Eles exigem bem mais cuidado manual para serem configurados corretamente em cada nuvem e, principalmente, para clonar a configuração de um cluster de uma nuvem para outra.
Neste artigo, comparo os modelos de cluster da Azure, do Google e da Amazon e apresento uma ferramenta para clonar clusters dentro de uma mesma nuvem ou entre nuvens diferentes.

Dolly, o primeiro mamífero clonado
Com o Kubernetes, gerenciar a aplicação é fácil: o controller do Kubernetes garante que ela tenha os recursos necessários, como memória, disco, load balancers e instâncias redundantes dos seus servidores. Tudo é padronizado e automatizado, e dá para trocar de provedor de infraestrutura quase sem mexer em nada.
A abstração do Kubernetes te isola da camada de infraestrutura, mas a infraestrutura continua lá. Os nós de um cluster são apenas VMs e não seguem um padrão entre os provedores de nuvem. Para quem está começando, isso é frustrante. Por que precisamos descobrir os recursos e as APIs necessárias modeladas de jeitos diferentes em cada nuvem, se todo o resto do Kubernetes é tão padronizado e automatizado?
Arquiteturas de contêineres serverless como AWS Fargate, Google Cloud Run e Azure Container Instances facilitam lidar com a infraestrutura (em troca de menos controle), mas não entregam a padronização entre nuvens que se espera do Kubernetes. Se você vai subir clusters Kubernetes padrão, precisa entender os modelos não padronizados de infraestrutura de cluster.
É aí que entra o Cluster Cloner, uma ferramenta open source que copia clusters de uma nuvem para outra, ou dentro de uma mesma nuvem. Vou usá-la para comparar as implementações de clusters no Google Kubernetes Engine, no Azure Kubernetes Service e no Elastic Kubernetes Service da AWS.
Conheça o Cluster Cloner
Se você quer clonar a configuração Kubernetes do seu cluster, pode usar o Heptio Velero. O etcd do Kubernetes deixa isso simples, já que toda a configuração fica armazenada lá. Mas, antes disso, é preciso copiar as máquinas virtuais do cluster e os demais recursos sobre os quais o Kubernetes roda. O Cluster Cloner é uma ferramenta de linha de comando que desenvolvi em Go, disponível tanto como imagem Docker quanto como aplicação standalone.
Se você usa Terraform ou outras ferramentas de infraestrutura como código, copiar clusters não é problema: basta rodar o mesmo código (com os ajustes necessários). Mas, quando o cluster foi criado de outro jeito, é preciso uma ferramenta capaz de entender o cluster como modelado em uma nuvem e traduzi-lo para o modelo de outra.
Dá para usar o Cluster Cloner de duas formas: copiando o cluster diretamente ou em modo "dry run", com uma etapa intermediária que permite ajustar o processo.
Opção \#1: clonagem direta
Para copiar clusters, execute clustercloner informando a nuvem de origem e o "escopo". (O escopo é o projeto do Google ou o Resource Group do Azure; na AWS não é necessário.)
Informe também o local de origem. Na AWS e no Azure, é a região. No Google, indique o nome da zona para clusters zonais e o nome da região para clusters regionais multizonais.
Da mesma forma, informe a nuvem de destino e o escopo de destino para Azure ou GCP.
Como cada ação pode levar vários minutos (detalhes abaixo), por padrão a criação é um dry run. Use --nodryrun para criar os clusters de fato.
O Cluster Cloner copia todos os clusters do local indicado, mas você pode restringir a cópia usando --labelfilter com uma lista de pares chave-valor separados por vírgula. Nesse caso, todos os labels precisam bater para o cluster ser copiado.
Um exemplo de linha de comando:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
A documentação da linha de comando está disponível em clustercloner --help. A documentação sobre desenvolvimento, execução dos testes unitários e de integração e build do binário e da imagem Docker está no arquivo README.
Opção \#2: personalize a clonagem
Você também pode personalizar o processo. O Cluster Cloner sempre gera uma descrição do cluster de destino em JSON. Então faça um dry run, omitindo --nodryrun, e edite o JSON gerado como uma especificação do cluster que você quer. Em seguida, rode clustercloner de novo, passando o nome do arquivo JSON como argumento da opção --inputfile. Os clusters definidos no arquivo serão criados.
EKS, AKS e GKE: semelhanças e diferenças
O Cluster Cloner foi feito para fazer a ponte entre três modelos bem diferentes de infraestrutura de cluster. A seguir, vamos comparar os elementos básicos que compõem um cluster no Google, na AWS e no Azure.
Não vamos comparar recursos avançados, já que os três provedores estão sempre correndo para acompanhar uns aos outros. Além disso, este artigo é baseado no Cluster Cloner, que se concentra em transformar as partes compatíveis dos modelos principais. Alguns aspectos dos modelos não são copiados por serem específicos do design de uma nuvem, como as master authorized networks e os Alpha clusters do GKE.
Comparando os modelos de cluster
Terminologia
Vamos começar pela terminologia, a parte mais fácil da comparação dos modelos de cluster, conforme expressos nas APIs.
Nas três nuvens, temos os termos a seguir. Internamente, o Cluster Cloner usa em geral a terminologia do GKE, em reconhecimento à origem do projeto Kubernetes dentro do Google.
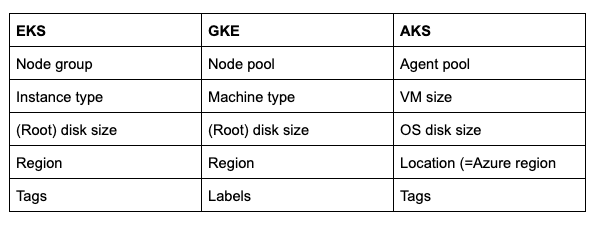
Terminologia
Modelo de cluster e node pool
Versões do Kubernetes
- GKE e AKS suportam uma lista de versões patch, disponíveis por meio de APIs que o Cluster Cloner utiliza.
- O Cluster Cloner nunca tenta mudar a versão major ou minor. Para escolher uma versão patch no AKS e no GKE, ele procura a menor versão patch igual ou maior que a do cluster de origem; se isso não for possível, escolhe a maior versão patch disponível.
- O EKS é mais simples: suporta quatro versões minor — atualmente 1.12, 1.13, 1.14 e 1.15 — que o Cluster Cloner mantém hardcoded.
Regiões
- O GKE oferece clusters em todas as regiões do Google.
- O EKS oferece clusters em quase todas as regiões, com poucas exceções.
- O AKS só dá suporte a uma lista específica de regiões.
- Ainda assim, cada nuvem oferece Kubernetes em geografias do mundo todo. O Cluster Cloner escolhe automaticamente uma região próxima com base em uma tabela de conversão.
Zonas
- No EKS e no AKS, os clusters são definidos por região, mas podem ser atribuídos a zonas de disponibilidade escolhendo as subnets de cada node group.
- O GKE permite criar clusters zonais ou clusters regionais multizonais.
- O Cluster Cloner só permite escolher a zona no GKE.
Tipos de máquina
- O Cluster Cloner usa uma abordagem simples para a conversão: busca, na nuvem de destino, o tipo de máquina (instância) que seja o least-upper-bound — ou seja, um tipo de máquina com a menor CPU e RAM possíveis, mas nunca inferior à da máquina de origem. (A escolha não é necessariamente única.)
- Tipos de máquina são difíceis de converter, pois variam em outras características além de CPU e RAM, como modelo de CPU e GPU, IO e, principalmente, trade-offs como tipos otimizados para memória ou para CPU. Levar essas características em conta está na lista de tarefas do Cluster Cloner.
Velocidades
O Cluster Cloner é uma ótima oportunidade para medir velocidades, já que a mesma ação é executada em cada nuvem. Veja o gráfico abaixo.
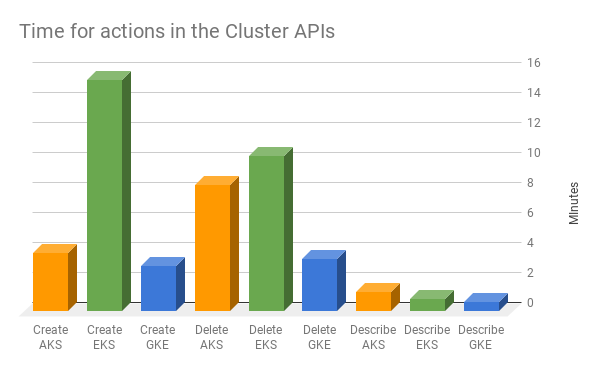
Tempos
Esperar mais alguns minutos não precisa ser um impeditivo, mas afeta sua capacidade de tratar clusters como você está acostumado a tratar pods — como "gado, não bichinhos de estimação", para serem deletados e recriados à vontade.
Os bastidores das APIs do EKS
O Cluster Cloner usa o eksctl para criar e excluir clusters e node groups. Como o eksctl é uma ferramenta de linha de comando que não foi pensada para uso via API, o Cluster Cloner faz um wrapper no ponto de entrada da linha de comando. Usamos o eksctl para a criação porque ele é inteligente o bastante para gerar todos os recursos subjacentes necessários ao cluster. Isso inclui uma VPC, subnets entre zonas de disponibilidade e security groups. E, igualmente importante, o eksctl consegue derrubar esses recursos na ordem certa: primeiro as network interfaces, depois a VPC e só então as instâncias EC2.
Para ler os clusters, o Cluster Cloner não usa o eksctl, que não consegue descrever o modelo completo e detalhado de clusters e node groups. Isso surpreende, considerando que hoje o eksctl é a ferramenta recomendada pela AWS para gerenciar clusters. A limitação vem do fato de que, no EKS, a camada de infraestrutura (EC2 com instâncias, subnets e VPCs) fica mais visível do que nas outras nuvens, e menos escondida por abstrações ligadas ao Kubernetes, como nós e node groups. Ainda assim, a informação está disponível: o Cluster Cloner usa o AWS SDK for Go para obter todos os dados necessários para caracterizar clusters e node groups.
O que vem por aí
O modelo de cluster, nos três provedores, é rico e oferece opções de configuração que ainda não são suportadas pelo Cluster Cloner.
A lista de recursos mostra o que o Cluster Cloner sabe copiar e também os aspectos ainda não implementados, como, por exemplo:
- Versões e tags do Kubernetes deveriam ser copiadas no nível do node pool, e não apenas no nível do cluster.
- As definições de autoscaling deveriam ser copiadas.
- Instâncias Spot deveriam ser suportadas no EKS, e não só no GKE e no AKS.
Se você quiser um recurso novo, fique à vontade para enviar um pull request no GitHub ou abrir uma GitHub issue.