Kubernetes simplifie l'orchestration des pods qui font tourner vos applications. Mais qu'en est-il des clusters sur lesquels ces pods s'exécutent ? Ceux-ci demandent une attention bien plus poussée pour être configurés correctement sur chaque cloud, et plus particulièrement lorsqu'il s'agit de cloner la configuration d'un cluster d'un cloud à un autre.
Dans cet article, je compare les modèles de cluster proposés par Azure, Google et Amazon, et je présente un outil permettant de cloner des clusters au sein d'un même cloud ou entre plusieurs clouds.

Dolly, le premier mammifère cloné
Avec Kubernetes, gérer votre application est simple : le contrôleur Kubernetes garantit que votre application dispose des ressources nécessaires, qu'il s'agisse de mémoire, de disque, de load balancers ou d'instances redondantes de vos serveurs. Tout est standardisé et automatisé, et vous pouvez changer de fournisseur d'infrastructure quasiment sans modification.
L'abstraction de Kubernetes vous isole de la couche infrastructure, mais celle-ci reste bien présente. Les nœuds d'un cluster ne sont que des VM, et celles-ci ne sont pas standardisées d'un fournisseur cloud à l'autre. Pour qui débute, c'est frustrant. Pourquoi devoir identifier les ressources et les API nécessaires, modélisées différemment selon les clouds, alors que tout le reste dans Kubernetes est si standard et automatisé ?
Les architectures de conteneurs serverless comme AWS Fargate, Google Cloud Run et Azure Container Instances facilitent la gestion de l'infrastructure (au prix d'un contrôle réduit), mais elles n'apportent pas la standardisation cross-cloud que l'on attend de Kubernetes. Si vous lancez des clusters Kubernetes standards, il vous faut comprendre ces modèles d'infrastructure non standards.
Cela nous amène à Cluster Cloner, un outil open source capable de copier des clusters d'un cloud à un autre, ou au sein d'un même cloud. Je vais l'utiliser pour comparer les implémentations de clusters dans Google Kubernetes Engine, Azure Kubernetes Service et Elastic Kubernetes Service d'AWS.
À la découverte de Cluster Cloner
Si vous souhaitez cloner la configuration Kubernetes de votre cluster, vous pouvez utiliser Heptio Velero. L'etcd de Kubernetes rend l'opération directe, puisque la configuration complète y est stockée. Mais avant cela, il faut copier les machines virtuelles du cluster ainsi que les autres ressources sur lesquelles Kubernetes s'exécute. Cluster Cloner est un outil en ligne de commande que j'ai développé en Go, disponible à la fois sous forme d'image Docker et d'application autonome.
Si vous utilisez Terraform ou un autre outil d'infrastructure-as-code, copier des clusters ne pose pas de problème : il suffit d'exécuter le même code (avec les ajustements appropriés). Mais lorsqu'un cluster a été créé autrement, il vous faut un outil capable de comprendre le cluster tel qu'il est modélisé dans un cloud, puis de le traduire vers le modèle d'un autre cloud.
Vous pouvez utiliser Cluster Cloner de deux manières : soit en copiant directement un cluster, soit en mode dry run, avec une étape intermédiaire qui vous permet d'ajuster le processus.
Option n°1 : clonage direct
Pour copier des clusters, exécutez clustercloner en précisant le cloud d'entrée et le scope. (Le scope correspond au projet Google ou au Resource Group Azure ; il n'est pas requis pour AWS.)
Indiquez également l'emplacement d'entrée. Sur AWS et Azure, il s'agit de la région. Sur Google, indiquez le nom de la zone pour les clusters zonaux et le nom de la région pour les clusters régionaux multizonaux.
De la même manière, précisez le cloud de sortie ainsi que le scope de sortie pour Azure ou GCP.
Comme chaque action peut prendre plusieurs minutes (détails plus bas), la création est par défaut un dry run. Spécifiez --nodryrun pour créer réellement les clusters.
Cluster Cloner copie tous les clusters situés à l'emplacement indiqué, mais vous pouvez restreindre la copie en spécifiant --labelfilter avec une liste de paires clé-valeur séparées par des virgules. Dans ce cas, tous les labels doivent correspondre pour qu'un cluster soit copié.
Un exemple de ligne de commande :
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
La documentation de la ligne de commande est disponible via clustercloner --help. La documentation pour le développement, l'exécution des tests unitaires et d'intégration, ainsi que la construction du binaire et de l'image Docker se trouve dans le fichier README.
Option n°2 : personnaliser le clonage
Vous pouvez également personnaliser le processus. Cluster Cloner produit toujours une description du cluster cible au format JSON. Effectuez donc un dry run en omettant --nodryrun, puis modifiez le JSON obtenu pour qu'il décrive le cluster que vous souhaitez. Relancez ensuite clustercloner en passant le nom du fichier JSON en argument de l'option --inputfile. Les clusters définis dans le fichier seront alors créés.
EKS, AKS et GKE : similitudes et différences
Cluster Cloner est conçu pour faire le pont entre trois modèles d'infrastructure de cluster très différents les uns des autres. Comparons à présent les éléments fondamentaux qui composent un cluster sur Google, AWS et Azure.
Nous ne comparerons cependant pas les fonctionnalités avancées, car les trois fournisseurs cloud se livrent une course permanente pour rester au coude à coude. De plus, cet article s'appuie sur Cluster Cloner, qui se concentre sur la transformation des éléments compatibles entre les modèles principaux. Certains aspects ne sont pas copiés, car ils sont propres à la conception d'un cloud particulier — comme les master authorized networks et les Alpha clusters de GKE.
Comparaison des modèles de cluster
Terminologie
Commençons par la terminologie, la partie la plus simple de la comparaison des modèles de cluster tels qu'ils s'expriment dans les API.
Sur les trois clouds, voici les termes utilisés. Au sein de Cluster Cloner, c'est généralement la terminologie GKE qui est employée, en clin d'œil aux origines du projet Kubernetes chez Google.
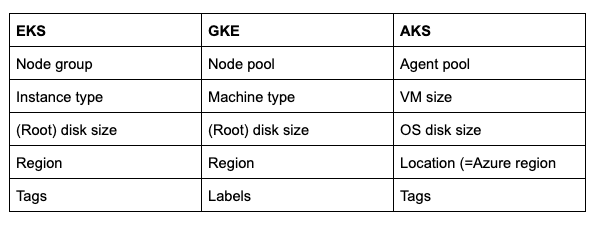
Terminologie
Modèle de cluster et de node pool
Versions de Kubernetes
- GKE et AKS prennent en charge une liste de versions correctives, accessibles via les API qu'utilise Cluster Cloner.
- Cluster Cloner ne tente jamais de modifier les versions majeure et mineure. Pour choisir une version corrective sur AKS et GKE, Cluster Cloner recherche la plus petite version corrective égale ou supérieure à celle du cluster source ; si cela n'est pas possible, il prend la plus grande version corrective disponible.
- EKS est plus simple et prend en charge quatre versions mineures — actuellement 1.12, 1.13, 1.14 et 1.15 — que Cluster Cloner code en dur.
Régions
- GKE prend en charge les clusters dans toutes les régions Google.
- EKS prend en charge les clusters dans presque toutes les régions, à quelques exceptions près.
- AKS ne prend en charge qu'une liste précise de régions.
- Cela dit, chaque cloud propose Kubernetes dans des régions du monde entier. Cluster Cloner sélectionne automatiquement une région proche à partir d'une table de conversion.
Zones
- Sur EKS et AKS, les clusters sont définis au niveau régional, mais ils peuvent être assignés à des zones de disponibilité en choisissant les sous-réseaux pour chaque node group.
- GKE permet de créer des clusters zonaux ou des clusters régionaux multizonaux.
- Cluster Cloner ne prend en charge le choix de zone que sur GKE.
Types de machines
- Cluster Cloner adopte une approche simple pour la conversion : il recherche dans le cloud cible le type de machine (instance) correspondant à la plus petite borne supérieure — autrement dit, un type de machine qui possède le moins de CPU et de RAM possible, tout en n'ayant pas moins de l'un ou de l'autre que le type source. (Ce choix n'est pas nécessairement unique.)
- Les types de machines sont difficiles à convertir, car ils diffèrent sur d'autres caractéristiques que le CPU et la RAM, notamment le modèle de CPU et de GPU, l'IO et — point important — des arbitrages comme les types optimisés mémoire ou optimisés CPU. La prise en compte de ces caractéristiques figure sur la to-do list de Cluster Cloner.
Vitesses
Cluster Cloner offre une excellente occasion de mesurer les vitesses, puisque la même action est exécutée sur chaque cloud. Voir le tableau ci-dessous.
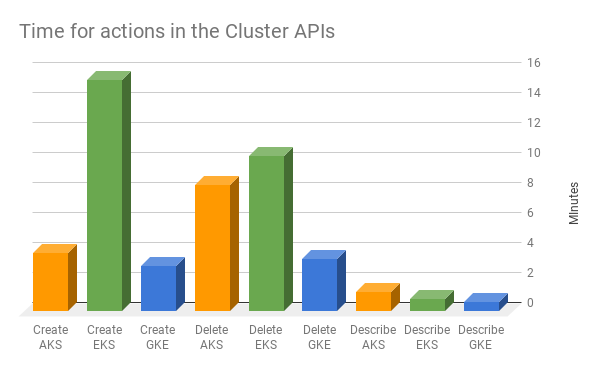
Temps mesurés
Quelques minutes d'attente supplémentaires ne sont pas rédhibitoires, mais cela pèse sur votre capacité à traiter les clusters comme vous traitez vos pods — comme du bétail et non des animaux de compagnie, à supprimer et recréer à volonté.
Les rouages des API EKS
Cluster Cloner s'appuie sur eksctl pour créer et supprimer les clusters et les node groups. Comme eksctl est un outil en ligne de commande qui n'est pas pensé pour un usage par API, Cluster Cloner l'encapsule au niveau du point d'entrée en ligne de commande. Nous utilisons eksctl pour la création parce qu'il est suffisamment intelligent pour générer toutes les ressources sous-jacentes nécessaires à un cluster : un VPC, des sous-réseaux répartis sur plusieurs zones de disponibilité et des groupes de sécurité. Tout aussi important, eksctl sait démanteler ces ressources dans le bon ordre : d'abord les interfaces réseau, puis le VPC, et seulement ensuite les instances de VM EC2.
Pour la lecture des clusters, Cluster Cloner n'utilise pas eksctl, qui ne sait pas décrire le modèle complet et détaillé des clusters et des node groups. C'est surprenant, sachant qu'eksctl est désormais l'outil recommandé par AWS pour gérer les clusters. Cette limite tient au fait que sur EKS, la couche infrastructure (EC2 avec ses instances, ses sous-réseaux et ses VPC) est plus clairement exposée que sur les autres clouds, et moins masquée par les abstractions Kubernetes telles que les nodes et les node groups. L'information reste néanmoins accessible : Cluster Cloner s'appuie sur l'AWS SDK for Go pour récupérer toutes les données nécessaires à la caractérisation des clusters et des node groups.
Et la suite
Chez les trois fournisseurs, le modèle de cluster est riche et propose des options de configuration qui ne sont pas encore prises en charge par Cluster Cloner.
La liste des fonctionnalités indique ce que Cluster Cloner sait copier, ainsi que les aspects non encore implémentés, par exemple :
- Les versions de Kubernetes et les tags devraient être copiés au niveau du node pool, et pas seulement au niveau du cluster.
- Les définitions d'autoscaling devraient être copiées.
- Les instances Spot devraient être prises en charge sur EKS, et pas uniquement sur GKE et AKS.
Si vous souhaitez voir une fonctionnalité ajoutée, n'hésitez pas à proposer une pull request sur GitHub ou à ouvrir un ticket GitHub.