Mit Kubernetes lassen sich die Pods, auf denen Ihre Anwendungen laufen, mühelos orchestrieren. Aber was ist mit den Clustern, auf denen die Pods laufen? Die brauchen deutlich mehr Handarbeit, um sie über die Clouds hinweg sauber zu konfigurieren – und vor allem, um eine Cluster-Konfiguration von einer Cloud in eine andere zu klonen.
In diesem Artikel vergleiche ich die Cluster-Modelle von Azure, Google und Amazon und stelle ein Tool vor, mit dem sich Cluster innerhalb einer Cloud oder cloudübergreifend klonen lassen.

Dolly, das erste geklonte Säugetier
Mit Kubernetes ist das Management Ihrer Anwendung einfach: Der Kubernetes-Controller sorgt dafür, dass Ihre Anwendung über die nötigen Ressourcen verfügt – Arbeitsspeicher, Festplatte, Load Balancer und redundante Server-Instanzen inklusive. Alles ist standardisiert und automatisiert, und Sie können den Infrastrukturanbieter nahezu ohne Anpassungen wechseln.
Die Abstraktion von Kubernetes schirmt Sie zwar von der Infrastrukturebene ab, doch die Infrastruktur ist nach wie vor da. Die Nodes eines Clusters sind nichts anderes als VMs – und die sind über Cloud-Anbieter hinweg nicht standardisiert. Für Einsteiger ist das frustrierend. Warum müssen wir uns mit den jeweils unterschiedlich modellierten Ressourcen und APIs der einzelnen Clouds herumschlagen, wenn doch sonst alles an Kubernetes so standardisiert und automatisiert ist?
Serverlose Container-Architekturen wie AWS Fargate, Google Cloud Run und Azure Container Instances vereinfachen den Umgang mit der Infrastruktur (zum Preis geringerer Kontrolle), bieten aber nicht die cloudübergreifende Standardisierung, die man von Kubernetes erwartet. Wer klassische Kubernetes-Cluster startet, muss die nicht standardisierten Cluster-Infrastrukturmodelle verstehen.
Damit kommen wir zu Cluster Cloner – einem Open-Source-Tool, das Cluster von Cloud zu Cloud oder innerhalb einer Cloud kopiert. Damit vergleiche ich die Cluster-Implementierungen in Google Kubernetes Engine, Azure Kubernetes Service und AWS Elastic Kubernetes Service.
Cluster Cloner im Überblick
Wenn Sie die Kubernetes-Konfiguration Ihres Clusters klonen wollen, hilft Ihnen Heptio Velero. Das etcd von Kubernetes macht das unkompliziert, denn dort liegt die komplette Konfiguration. Davor müssen Sie aber die virtuellen Maschinen des Clusters und die übrigen Ressourcen kopieren, auf denen Kubernetes läuft. Cluster Cloner ist ein Kommandozeilen-Tool, das ich in Go entwickelt habe – verfügbar als Docker-Image und als Standalone-Anwendung.
Wer Terraform oder andere Infrastructure-as-Code-Tools einsetzt, hat beim Kopieren von Clustern kein Problem: einfach denselben Code (mit den passenden Anpassungen) ausführen. Wurde ein Cluster jedoch auf andere Weise erstellt, brauchen Sie ein Tool, das den Cluster im Modell der einen Cloud versteht und in das Modell einer anderen Cloud übersetzt.
Cluster Cloner lässt sich auf zwei Arten nutzen: entweder durch direktes Kopieren eines Clusters oder als "Dry Run" mit einem Zwischenschritt, in dem Sie den Vorgang feinjustieren.
Option \#1: Direkt klonen
Um Cluster zu kopieren, führen Sie clustercloner aus und geben dabei die Eingangs-Cloud sowie den "Scope" an. (Der Scope ist das Google-Projekt oder die Azure Resource Group; in AWS entfällt er.)
Geben Sie außerdem den Eingangs-Standort an. In AWS und Azure ist das die Region. In Google nennen Sie für zonale Cluster den Zonennamen und für multizonale regionale Cluster den Regionsnamen.
Geben Sie ebenso die Ausgabe-Cloud an – und für Azure oder GCP den Ausgabe-Scope.
Da jede Aktion mehrere Minuten dauern kann (Details unten), ist die Erstellung standardmäßig ein Dry Run. Mit --nodryrun werden die Cluster tatsächlich angelegt.
Cluster Cloner kopiert alle Cluster am angegebenen Standort. Mit --labelfilter und einer durch Kommas getrennten Liste von Schlüssel-Wert-Paaren lässt sich das Kopieren einschränken. In diesem Fall müssen alle Labels übereinstimmen, damit ein Cluster kopiert wird.
Eine beispielhafte Befehlszeile:
clustercloner --inputcloud GCP --inputscope my-google-project --inputlocation us-central1-c --outputcloud AWS --key-a=value-a,key-b=value-b --nodryrun
Die Dokumentation zur Befehlszeile rufen Sie mit clustercloner --help auf. Hinweise zur Entwicklung, zum Ausführen der Unit- und Integrationstests sowie zum Bauen der Binary und des Docker-Images finden Sie in der README-Datei.
Option \#2: Klonvorgang anpassen
Sie können den Vorgang auch anpassen. Cluster Cloner gibt grundsätzlich eine Beschreibung des Ziel-Clusters in JSON aus. Führen Sie also einen Dry Run durch, indem Sie --nodryrun weglassen, und bearbeiten Sie das ausgegebene JSON als Spezifikation des gewünschten Clusters. Anschließend führen Sie clustercloner erneut aus und übergeben den JSON-Dateinamen als Argument für die Option --inputfile. Die in der Datei definierten Cluster werden dann angelegt.
EKS, AKS und GKE: Gemeinsamkeiten und Unterschiede
Cluster Cloner schlägt die Brücke zwischen den drei sehr unterschiedlichen Modellen für Cluster-Infrastruktur. Vergleichen wir nun die grundlegenden Bausteine eines Clusters in Google, AWS und Azure.
Auf erweiterte Funktionen gehen wir dabei nicht ein, denn die drei Cloud-Anbieter überholen sich in diesem Bereich permanent. Außerdem basiert dieser Artikel auf Cluster Cloner, der sich auf die Übertragung der kompatiblen Teile der Kernmodelle konzentriert. Manche Aspekte der Modelle werden nicht kopiert, weil sie spezifisch für eine bestimmte Cloud sind – etwa die Master Authorized Networks und Alpha Cluster von GKE.
Vergleich der Cluster-Modelle
Terminologie
Beginnen wir mit der Terminologie – dem einfachsten Teil des Vergleichs der Cluster-Modelle, wie sie in den APIs abgebildet sind.
In den drei Clouds gelten die folgenden Begriffe. In Cluster Cloner selbst kommt überwiegend die GKE-Terminologie zum Einsatz – als Verbeugung davor, dass das Kubernetes-Projekt seinen Ursprung bei Google hat.
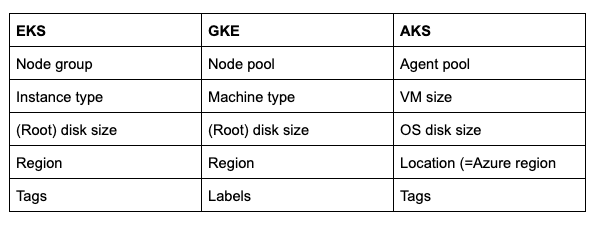
Terminologie
Cluster- und Node-Pool-Modell
Kubernetes-Versionen
- GKE und AKS unterstützen eine Liste von Patch-Versionen, die über APIs verfügbar sind, die Cluster Cloner nutzt.
- Cluster Cloner versucht nie, die Major- oder Minor-Version zu ändern. Für die Wahl einer Patch-Version in AKS und GKE sucht Cluster Cloner die niedrigste Patch-Version, die gleich oder höher ist als die des Quell-Clusters – oder, falls das nicht möglich ist, die höchste verfügbare Patch-Version.
- EKS ist einfacher gestrickt und unterstützt vier Minor-Versionen, derzeit 1.12, 1.13, 1.14 und 1.15, die in Cluster Cloner fest hinterlegt sind.
Regionen
- GKE unterstützt Cluster in allen Google-Regionen.
- EKS unterstützt Cluster in allen Regionen bis auf wenige Ausnahmen.
- AKS unterstützt nur eine festgelegte Liste von Regionen.
- Trotzdem unterstützt jede Cloud Kubernetes in Regionen rund um den Globus. Cluster Cloner wählt anhand einer Konvertierungstabelle automatisch eine nahegelegene Region.
Zonen
- In EKS und AKS werden Cluster regional definiert, lassen sich aber über die Wahl der Subnetze pro Node Group bestimmten Availability Zones zuordnen.
- GKE erlaubt zonale Cluster oder multizonale regionale Cluster.
- Cluster Cloner unterstützt die Auswahl der Zone nur in GKE.
Maschinentypen
- Cluster Cloner verfolgt einen einfachen Konvertierungsansatz und sucht in der Ziel-Cloud den Maschinen- (Instanz-)Typ, der die kleinste obere Schranke darstellt – also den Maschinentyp mit der geringstmöglichen CPU- und RAM-Ausstattung, der dabei jedoch in beiden Werten nicht unter dem Quell-Maschinentyp liegt. (Diese Wahl ist nicht zwingend eindeutig.)
- Maschinentypen sind nur schwer 1:1 zu übertragen, da sie sich nicht nur in CPU und RAM unterscheiden, sondern auch in weiteren Merkmalen – etwa CPU- und GPU-Modell, IO und vor allem Trade-offs wie speicher- oder CPU-optimierte Typen. Diese Eigenschaften zu berücksichtigen, steht auf der To-do-Liste von Cluster Cloner.
Geschwindigkeiten
Cluster Cloner bietet eine ideale Gelegenheit, Geschwindigkeiten zu messen, weil in jeder Cloud dieselbe Aktion ausgeführt wird. Siehe das Diagramm unten.
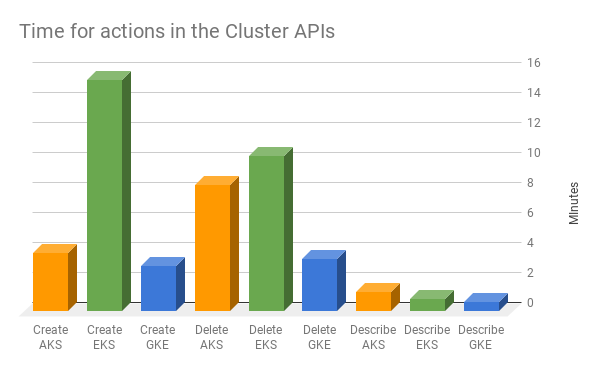
Laufzeiten
Ein paar Minuten länger zu warten muss kein K.-o.-Kriterium sein, schränkt aber Ihre Möglichkeit ein, Cluster so zu behandeln, wie Sie es von Pods gewohnt sind – als "Cattle, not Pets", die nach Belieben gelöscht und neu erstellt werden.
Die Eigenheiten der EKS-APIs
Cluster Cloner nutzt eksctl, um Cluster und Node Groups zu erstellen und zu löschen. Da eksctl ein Kommandozeilen-Tool ist und nicht für die API-Nutzung konzipiert wurde, kapselt Cluster Cloner es über den Kommandozeilen-Einstiegspunkt. Wir nutzen eksctl für die Erstellung, weil es clever genug ist, alle zugrunde liegenden Ressourcen zu erzeugen, die ein Cluster benötigt – darunter eine VPC, Subnetze über mehrere Availability Zones hinweg sowie Security Groups. Genauso wichtig: eksctl kann diese Ressourcen in der richtigen Reihenfolge wieder abbauen – zuerst die Network Interfaces, dann die VPC und erst zum Schluss die EC2-VM-Instanzen.
Zum Auslesen der Cluster verwendet Cluster Cloner eksctl nicht, da es das vollständige, detaillierte Modell von Clustern und Node Groups nicht beschreiben kann. Das überrascht, schließlich ist eksctl inzwischen das von AWS empfohlene Tool zur Cluster-Verwaltung. Die Einschränkung rührt daher, dass in EKS die Infrastrukturebene (EC2 mit Instanzen, Subnetzen und VPCs) deutlicher zutage tritt als in den anderen Clouds und weniger durch Kubernetes-bezogene Abstraktionen wie Nodes und Node Groups verdeckt wird. Die Informationen sind aber verfügbar: Cluster Cloner nutzt das AWS SDK for Go, um sämtliche Daten zur Charakterisierung von Clustern und Node Groups zu beziehen.
Was als Nächstes kommt
Das Cluster-Modell ist bei allen drei Anbietern umfangreich und bietet Konfigurationsoptionen, die Cluster Cloner noch nicht abdeckt.
Die Feature-Liste zeigt, was Cluster Cloner kopieren kann – und welche Aspekte noch nicht implementiert sind, zum Beispiel:
- Kubernetes-Versionen und Tags sollten auf Node-Pool-Ebene kopiert werden, nicht nur auf Cluster-Ebene.
- Autoscaling-Definitionen sollten kopiert werden.
- Spot Instances sollten auch in EKS unterstützt werden, nicht nur in GKE und AKS.
Wenn Sie sich ein Feature wünschen, eröffnen Sie gerne einen Pull Request auf GitHub oder erstellen Sie ein GitHub-Issue.