複雑なシステムで、結果を本当に左右している要因は何か――そう感じたことはありませんか?従来の分析では、どの要因が同時に現れるかは見えても、ある要因が別の要因を実際に引き起こしているかどうかまでは、ほとんど分かりません。この違いは、どんな領域でも効果的な改善を進めるうえで決定的に重要です。
今回ご紹介するのは、因果分析と生成AIを組み合わせることで強力なインサイトが得られることを示すプロジェクトです。題材としてはサポート対応における顧客満足度を取り上げますが、同じ手法は、真の因果関係を見極めることが価値につながるあらゆる分野に応用できます。
フレンドリンク: https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
因果分析とは
まずは、因果分析がなぜこれほど強力なのかを整理しておきましょう。データの世界では、私たちは「同時に起こる事象」=相関に取り囲まれています。たとえば、アイスクリームの売上と水難事故はどちらも夏に増えます。とはいえ、アイスクリームが水難事故を引き起こしているわけではありません。両者には「気温の高さ」という共通の原因があるだけです。
因果分析は、単にパターンを見つけるだけでなく、「介入したら何が起こるか?」という根源的な問いに答えるアプローチです。両者の違いは次のように整理できます。
- 相関:「Aが起こると、Bも起こりやすい」
- 因果:「Aを起こせば、Bが起こる」
従来の機械学習はパターン発見や予測には強いものの、意思決定の核となる「もし~したら」という問いには弱いという課題があります。因果分析はこの隙間を埋め、行動や介入が実際にどんな効果をもたらすかを捉えるための枠組みを提供します。
Causal NLPとは
Causal NLP(自然言語処理)は、因果性と言語処理が交わる刺激的な領域です。これにより、次のことが可能になります。
- テキストから因果関係を抽出する:自然言語の中で、ある事象や要因が別のものを引き起こしている箇所を特定します。
- 言語データに因果推論を適用する:高度な手法を用いて、テキストに含まれるどの要因が結果に実際に影響しているかを判定します。
- 非構造化テキストを因果インサイトへ変換する:雑然とした実世界の言語を、構造化された因果モデルに落とし込みます。
本プロジェクトでは、因果推論と自然言語処理を統合した専用ライブラリcausalnlpを活用しました。これにより、満足した顧客のフィードバックに「どんな単語が出てくるか」を見るだけでなく、対応のどの側面が満足度を引き起こしたのかまで踏み込んで理解できるようになります。
因果分析×生成AIの威力
因果分析と生成AIの組み合わせがとりわけ強力なのには、次の理由があります。
- 生成AIが非構造化データを構造化する — 会話のような定性情報を、因果分析にかけられる構造化データへと変換します。
- 因果分析が相関と因果を切り分ける — 「同時に起きている」から「これがあれを引き起こしている」へ踏み込みます。
- 生成AIがインサイトを誰にでも届く形にする — 複雑な統計結果を、自然言語のわかりやすい説明へと翻訳します。
本記事では顧客満足度を題材にしますが、同じアプローチを医療のアウトカム、教育成果、サプライチェーン最適化、金融リスク管理に当てはめてみてください。応用範囲は無限に広がります。
ソースデータを把握する
分析に入る前に、この因果推論システムを支えるデータの構造を押さえておきましょう。土台となるのは、次のようなフィールドを持つカスタマーサポートチケットのデータセットです。
- チケットID(
ticket_id):各サポート対応に振られる一意の識別子 - 会話履歴(
comment_history_table_string):顧客とサポート担当者のやり取り全体を収めたテキストログ - プラットフォームと製品の情報:
custom_platform:対象プラットフォームの詳細(例:'amazon_web_services'、'google_cloud_platform')custom_product:そのチケットが対象とする製品やサービス- サポートケース利用の有無(
cloud_support_case_used):正式なサポートケースが起票されたかどうか - 顧客評価(
rating):顧客がもともと付けた評価(例:'good'、'offered')
この構造化データセット、とりわけ会話履歴のテキストが、因果推論を駆動する生成AI分析の入力になります。
シンプルな例:顧客満足度
このアプローチの威力を示すために、サポート対応における顧客満足度を真に左右する要因を分析するシステムを構築しました。これは数あるユースケースの中でも分かりやすい一例にすぎず、手法自体は他のさまざまな領域に転用できます。なお、用いているのは実データの構造に基づいた合成データです。
GitHubリポジトリ: https://github.com/eduamota/genai-causal-inference
データ処理パイプライン
まず、複数のPythonスクリプトとAmazon Bedrockを用いて、生のサポートチケットから構造化された情報を抽出します。
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
パイプライン全体は次のように構成しています。
- 感情分析(
01_sentiment_analysis.py):BedrockのNovaモデルで会話の感情トーンを分類 - 数値変換(
02_convert_to_numeric.py):カテゴリデータを数値形式に変換 - 解決判定(
03_identify_resolution.py):上記コードのとおり、課題が解決されたかどうかを判定 - 理解度の評価(
04_evaluate_understanding.py):担当者が顧客の問題をきちんと理解できていたかを評価 - グラフ作成(
05_create_neptune_gremlin.py):Neptune Analyticsへ取り込めるようデータを整形
このアプローチの応用範囲は広く、医療では臨床ノートからの診断抽出、金融ではレポートからのリスク要因抽出、教育では学生のやり取りからの学習パターン抽出といった使い方が考えられます。
因果グラフのモデリング
続いて、抽出した関係性をNeptune Analytics上のグラフとして表現します。
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
このグラフ構造は、どんな領域の因果関係でも表現可能です。医療なら治療がアウトカムにどう作用するか、教育なら指導法が学習にどう影響するか、金融なら政策変更が市場行動にどう波及するかをモデル化できます。
Neptune Analyticsのスキーマ
Neptune Analytics上のグラフスキーマは、本因果分析システムの背骨にあたります。構造は次のとおりです。
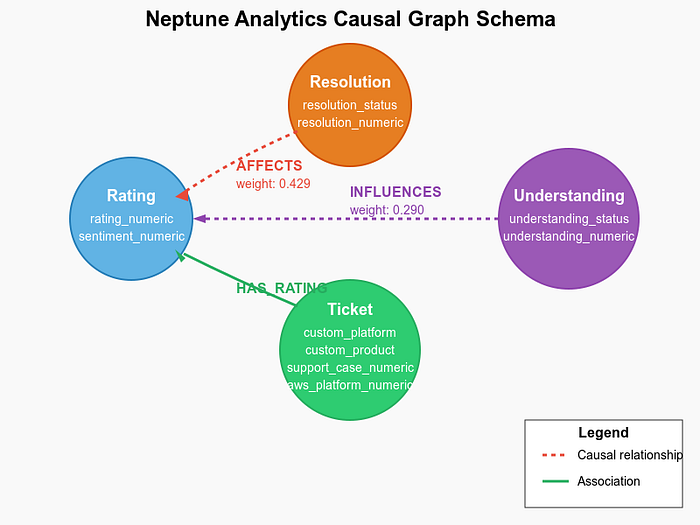
Neptuneスキーマ
グラフのノード(頂点)
グラフには複数の種類のノードが含まれます。
- Ratingノード:rating_numericなどのプロパティを持ち、顧客評価を表現
- Resolutionノード:課題が解決されたかどうか(resolved/unresolved)を保持
- Understandingノード:担当者の理解度(understood/misunderstood)を反映
- Ticketノード:元のチケットの全プロパティと算出した指標をまとめて保持
グラフのリレーション(エッジ)
グラフのエッジは因果関係を表します。
- AFFECTSリレーション:解決状況と評価をつなぎ、重みが因果の強さを表現
- INFLUENCESリレーション:理解度と評価をつなぐ
- HAS_RATINGリレーション:チケットを評価に紐づける
このグラフ構造によって、顧客満足度に影響する要因を強力に問い合わせ、可視化できるようになります。
因果効果を算出する
因果推論モデルを使い、実際の処置効果(treatment effect)を算出します。
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
この結果から、顧客の課題を解決することがポジティブ評価を42.9パーセンテージポイント押し上げる原因になっていることが分かります。これは単なる相関ではなく因果関係であり、効果的な改善を進めるうえで欠かせない区別です。
Bedrockによる自然言語インターフェース
最後に、Neptune Analyticsに接続するBedrockエージェントを構築し、ユーザーが自然言語で問いかけられるようにしました。
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
このインターフェースにより、複雑な因果インサイトを技術者でないユーザーも使いこなせます。たとえば医師なら「再入院率を最も効果的に下げる治療は何か?」、教育者なら「テストの成績に最も強く効く指導法はどれか?」といった問いを投げかけられます。
データフローとシステムアーキテクチャ
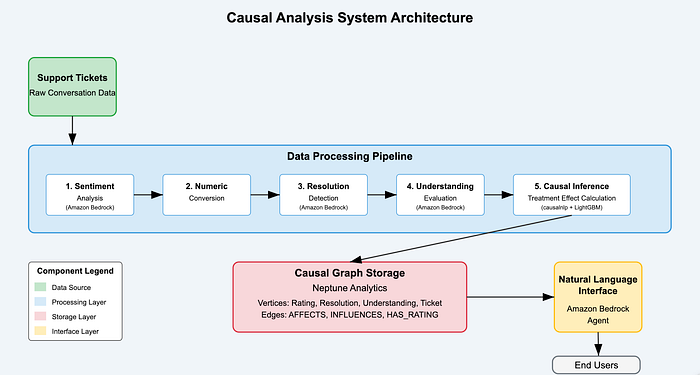
ソリューションアーキテクチャ図
![システムアーキテクチャ図 — 各コンポーネント間のデータフローを含むシステム全体図を挿入]
上の図は、本因果分析システムにおけるデータの流れをエンドツーエンドで示しています。
- 生のチケットデータがパイプラインに投入される
- 生成AIが非構造化テキストから特徴量を抽出する
- 因果推論が効果の強さを算出する
- Neptune Analyticsがグラフ構造を保持する
- Bedrockエージェントが自然言語によるインサイトへのアクセスを提供する
このアーキテクチャにより、生データから実行可能なインサイトに至るまで、すべてのコンポーネントがシームレスなパイプラインで結びつきます。
アーキテクチャ:エンドツーエンドの統合
本因果分析システムの全体像は、いくつかの強力なコンポーネントを連携させることで成り立っています。
- 生成AIによるデータ処理:Amazon BedrockのNova Liteモデルが非構造化の会話テキストを構造化された特徴量に変換し、因果モデルに入力します
- 因果推論の処理:LightGBMなどの学習器を組み合わせた
causalnlpのようなライブラリが、特徴量と結果の関係を分析し、因果的影響を定量化します - グラフベースのストレージ:Neptune Analyticsがチケット、特徴量、算出された因果関係といった複雑かつ相互に絡み合うデータを保持し、効率的な探索を可能にします
- 自然言語インターフェース:BedrockエージェントがopenCypherでNeptune Analyticsのグラフに問い合わせ、データに裏打ちされたインサイトを自然言語で返します
このアーキテクチャは、生データから実行可能なインサイトまでを一気通貫でつなぐパイプラインを形作っており、複雑な会話データを構造化された分析可能な情報に変換するうえで、生成AIが要となる役割を担っています。
結果:詳細な因果インサイト
顧客満足度の事例では、本システムによって次のような明確で定量的なインサイトが浮かび上がりました。
- 解決こそが最大のドライバー — 顧客の課題を解決することがポジティブ評価を42.9パーセンテージポイント押し上げる原因になっています。
- 解決済みの課題はポジティブ評価が平均83%。
- 未解決の課題はポジティブ評価が平均41%にとどまる。
- 理解が効果を増幅する — 担当者の理解は大きな後押しになります。
- 担当者が理解していた場合:ポジティブ評価67%。
- 担当者が誤解していた場合:ポジティブ評価38%。
- 組み合わせ効果が最適経路を示す:
- 理解+解決:ポジティブ評価91%。
- 理解+未解決:ポジティブ評価52%。
- 誤解+解決:ポジティブ評価61%。
- 誤解+未解決:ポジティブ評価29%。
これらの内訳から、進むべき方向ははっきりしています。課題解決を最優先しつつ、担当者がしっかり理解を示すこと――これが顧客満足度を最大化する条件になるのです。
もっとも、こうした顧客満足度のインサイトはほんの一例にすぎません。同じアプローチを使えば、次のようなことも明らかにできます。
- 医療:再入院を最も効果的に減らす介入はどれか。
- 教育:学生のアウトカムに最も強い因果効果を持つ指導法はどれか。
- EC:実際に購入増を引き起こす商品レコメンドはどれか。
- 製造:品質指標を本当に改善するプロセス変更はどれか。
- 人事:従業員の定着に因果的に効く制度はどれか。
技術的な実装
このアプローチに必要な中核コンポーネントは、わずか数点です。
- 生成AIによるデータ抽出 — ClaudeやGPTのようなモデルで非構造化データを構造化する。
- 因果推論モデリング — 統計的手法を適用し、因果関係を見極める。
- 関係性を扱うグラフデータベース — 因果モデルをグラフデータベースに保存し、問い合わせる。
- 自然言語インターフェース — 会話型AIを介して、誰もがインサイトに触れられるようにする。
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
OpenCypherクエリの例
Neptune Analyticsの真価は、OpenCypherを使って複雑な因果関係を問い合わせられる点にあります。その実力を示すクエリ例をいくつか紹介します。
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
これらのクエリを使えば、グラフ内の因果関係をたどり、実行可能なインサイトを引き出せます。
ビジネスへの応用:技術的インサイトの先へ
このアプローチの本当の価値は、技術的な実装そのものではなく、得られたインサイトがビジネスをどう変えうるかにあります。
- 担当者の研修・コーチング:解決と理解が満足度に与える影響を正確に数値化することで、最もインパクトの大きいスキルに絞った研修プログラムを設計できます。
- プロセス改善:結果を左右する因果要因を押さえることで、相関頼みの場当たり的な変更ではなく、最適な成果を狙ったプロセス再設計が可能になります。
- インサイトの民主化:因果インサイトに自然言語でアクセスできるようにすることで、現場のスタッフや管理職にもデータドリブンな意思決定を委ねられます。
- 異常検知:感情のような要因が評価と噛み合わないケースをシステムが洗い出し、調査と学びの機会を浮き彫りにします。
業界を超えて重要な理由
因果分析と生成AIの組み合わせは、ほぼあらゆる分野で意思決定を変革しうるものです。
- 相関の先へ — 望む結果を実際に引き起こしている要因を見極める。
- 影響を定量化する — 各要因の寄与度を正確に把握する。
- 介入に優先順位をつける — 因果効果が最も大きい箇所にリソースを集中させる。
- インサイトを開かれたものにする — 技術者でない関係者も、因果に関する問いを投げかけられるようにする。
おわりに:すべてはここから
本記事で取り上げた顧客満足度の事例は、因果分析と生成AIを組み合わせる可能性の一端を示すものですが、できることのほんの入り口にすぎません。これらの技術がより身近になるにつれ、因果的な理解を活かす組織は意思決定で大きなアドバンテージを手にすることになるでしょう。
ぜひ、ご自身の分野で因果分析がどんな変革をもたらしうるか、想像してみてください。気づいてはいるけれど、それが因果関係なのか確信が持てない関係性はありませんか?改善したい結果はあるのに、どのレバーを引くべきか見えていない場面はありませんか?本アプローチが答えを出す手助けをするのは、まさにそうした問いに対してです。
あなたなら、どの領域に因果分析を応用しますか?どんなアウトカムを因果として理解したいですか?ぜひコメントでお聞かせください!
DoiTについて、また私たちが貴社の目標達成をどのように支援できるかについては、doit.com/servicesをご覧ください。
GitHubリポジトリ: https://github.com/eduamota/genai-causal-inference