Você já se perguntou o que de fato determina os resultados em sistemas complexos? A análise tradicional até consegue apontar quais fatores aparecem juntos, mas raramente mostra se um deles realmente causa o outro. Essa distinção é fundamental para gerar melhorias eficazes em qualquer área.
Hoje compartilho um projeto que mostra como unir análise causal e IA generativa pode revelar insights poderosos. Apliquei essa abordagem à satisfação do cliente em interações de suporte, mas as mesmas técnicas servem para praticamente qualquer área em que entender as verdadeiras relações de causa e efeito faça diferença.
Link de acesso: https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
O que é análise causal?
Vale a pena entender o que torna a análise causal tão poderosa. No mundo dos dados, a gente costuma se afogar em correlações — coisas que acontecem ao mesmo tempo. Por exemplo: as vendas de sorvete e os casos de afogamento aumentam no verão. Mas será que sorvete causa afogamento? Claro que não. Os dois têm uma causa em comum: o calor.
A análise causal vai além de identificar padrões e responde à pergunta central: "O que acontece se intervirmos?". É a diferença entre:
- Correlação: "Quando A acontece, B também tende a acontecer".
- Causalidade: "Se fizermos A acontecer, isso fará B acontecer".
O machine learning tradicional é ótimo para encontrar padrões e fazer previsões, mas tropeça nas perguntas do tipo "e se", que são justamente as que orientam a tomada de decisão. A análise causal preenche essa lacuna ao oferecer uma estrutura para entender os efeitos reais de ações ou intervenções.
O que é Causal NLP?
O Causal NLP (Processamento de Linguagem Natural Causal) está na empolgante interseção entre causalidade e processamento de linguagem. Com ele, dá para:
- Extrair relações causais de textos: identificar quando um evento ou fator causa outro em linguagem natural.
- Aplicar raciocínio causal a dados de linguagem: usar técnicas avançadas para descobrir quais fatores em um texto realmente influenciam os resultados.
- Transformar texto não estruturado em insights causais: converter linguagem desorganizada do mundo real em modelos causais estruturados.
Neste projeto, usei a causalnlp, uma biblioteca especializada que combina técnicas de inferência causal com processamento de linguagem natural. Ela permite ir além de só analisar quais palavras aparecem no feedback de um cliente satisfeito e entender quais aspectos da interação causaram essa satisfação.
O poder da causalidade + GenAI
A combinação de análise causal com IA generativa é especialmente poderosa porque:
- A GenAI estrutura dados não estruturados — transformando informações qualitativas (como conversas) em dados estruturados, prontos para análise causal.
- A análise causal separa correlação de causalidade — saindo do "essas coisas aparecem juntas" para o "isso causa aquilo".
- A GenAI torna os insights acessíveis — traduzindo descobertas estatísticas complexas em explicações em linguagem natural.
Embora eu vá demonstrar isso com dados de satisfação do cliente, imagine aplicar a mesma abordagem em resultados de saúde, desempenho educacional, otimização de cadeia de suprimentos ou gestão de risco financeiro. As possibilidades são infinitas.
Entendendo os dados de origem
Antes de mergulhar na análise, vale entender a estrutura dos dados que alimentam esse sistema de inferência causal. A base é um conjunto de tickets de suporte ao cliente com campos como:
- Identificador do ticket (
ticket_id): identificador único de cada interação de suporte. - Histórico da conversa (
comment_history_table_string): o registro completo, em texto, das conversas entre clientes e agentes de suporte. - Informações de plataforma e produto:
custom_platform: detalhes sobre a plataforma envolvida (por exemplo, 'amazon_web_services', 'google_cloud_platform').custom_product: especifica o produto ou serviço a que o ticket se refere.- Uso de caso de suporte (
cloud_support_case_used): indica se um caso formal de suporte foi aberto. - Avaliação do cliente (
rating): a avaliação original dada pelo cliente (por exemplo, 'good', 'offered').
Esse conjunto de dados estruturado, em especial o histórico textual das conversas, serve de entrada para a análise por IA generativa que alimenta o processo de inferência causal.
Um exemplo simples: satisfação do cliente
Para mostrar o poder dessa abordagem, criei um sistema que analisa o que realmente determina a satisfação do cliente em interações de suporte. É só uma aplicação simples — as técnicas se adaptam a muitas outras áreas. Os dados são sintéticos, baseados na estrutura de dados reais.
Repositório no GitHub: https://github.com/eduamota/genai-causal-inference
O pipeline de processamento de dados
Primeiro, extraio informações estruturadas dos tickets de suporte brutos com uma série de scripts Python e o Amazon Bedrock:
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
Meu pipeline completo inclui:
- Análise de sentimento (
01_sentiment_analysis.py): usa o modelo Nova do Bedrock para classificar o tom emocional das conversas. - Conversão numérica (
02_convert_to_numeric.py): transforma dados categóricos em formatos numéricos. - Detecção de resolução (
03_identify_resolution.py): determina se os problemas foram resolvidos, como mostra o código acima. - Avaliação de compreensão (
04_evaluate_understanding.py): verifica se os agentes entenderam corretamente o problema do cliente. - Criação do grafo (
05_create_neptune_gremlin.py): prepara os dados para carregamento no Neptune Analytics.
É uma abordagem amplamente aplicável. Na saúde, dá para extrair diagnósticos de prontuários clínicos; em finanças, fatores de risco de relatórios; na educação, padrões de aprendizado em interações com alunos.
Modelagem de grafo causal
Em seguida, represento as relações como um grafo no Neptune Analytics:
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
Essa estrutura de grafo serve para representar relações causais em qualquer área. Na saúde, dá para modelar como tratamentos afetam resultados; na educação, como métodos de ensino influenciam o aprendizado; em finanças, como mudanças de política impactam o comportamento do mercado.
Esquema do Neptune Analytics
O esquema de grafo no Neptune Analytics é a espinha dorsal do nosso sistema de análise causal. Veja a estrutura:
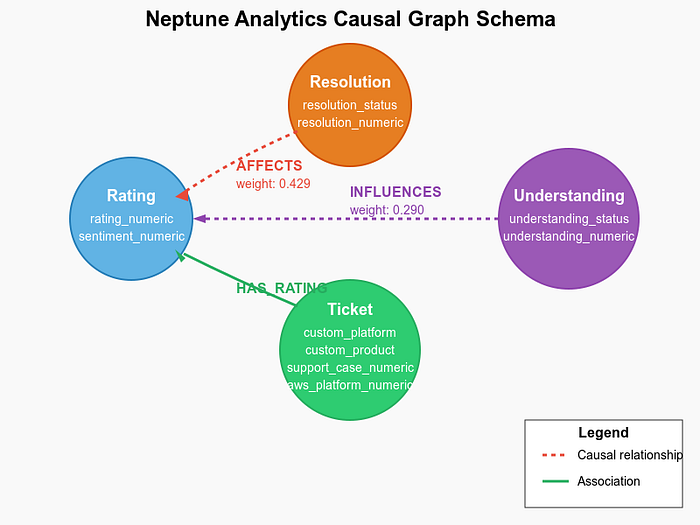
Esquema do Neptune
Nós do grafo (vértices)
O grafo tem vários tipos de nós:
- Nós de rating: representam as avaliações dos clientes, com propriedades como rating_numeric.
- Nós de resolution: indicam se os problemas foram resolvidos (resolved/unresolved).
- Nós de understanding: refletem a compreensão do agente (understood/misunderstood).
- Nós de ticket: contêm todas as propriedades originais do ticket e métricas derivadas.
Relações do grafo (arestas)
As arestas do nosso grafo representam as relações causais:
- Relação AFFECTS: conecta o status de resolução às avaliações, com pesos que representam a intensidade causal.
- Relação INFLUENCES: liga o status de compreensão às avaliações.
- Relação HAS_RATING: associa os tickets às respectivas avaliações.
Essa estrutura de grafo viabiliza consultas causais poderosas e visualizações dos fatores que influenciam a satisfação do cliente.
Calculando efeitos causais
Com um modelo de inferência causal, calculo os efeitos reais do tratamento:
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
Esse cálculo mostra que resolver o problema do cliente causa um aumento de 42,9 pontos percentuais nas avaliações positivas. É uma relação causal, não apenas uma correlação — uma distinção fundamental para promover melhorias eficazes.
Interface em linguagem natural com o Bedrock
Por fim, criei um agente do Bedrock que se conecta ao Neptune Analytics e permite que os usuários façam perguntas em linguagem natural:
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
Essa interface deixa insights causais complexos ao alcance de usuários não técnicos. Um médico poderia perguntar: "Qual tratamento reduz com mais eficácia as taxas de readmissão?". Um educador poderia querer saber: "Qual método de ensino tem o efeito mais forte sobre as notas das provas?".
Fluxo de dados e arquitetura do sistema
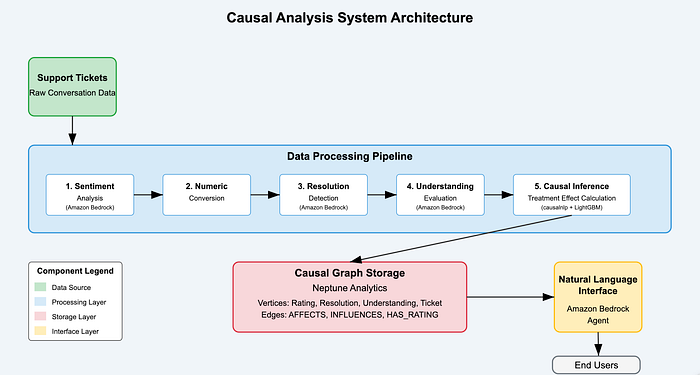
Diagrama da arquitetura da solução
![Diagrama da arquitetura do sistema — Inserir diagrama mostrando a arquitetura completa do sistema com o fluxo de dados entre os componentes]
O diagrama acima ilustra o fluxo completo dos dados pelo nosso sistema de análise causal:
- Os dados brutos dos tickets entram no pipeline.
- A IA generativa extrai features de textos não estruturados.
- A inferência causal calcula a intensidade dos efeitos.
- O Neptune Analytics armazena a estrutura do grafo.
- O agente do Bedrock dá acesso aos insights em linguagem natural.
Essa arquitetura conecta todos os componentes em um pipeline contínuo, dos dados brutos aos insights acionáveis.
A arquitetura: integração de ponta a ponta
A arquitetura completa desse sistema de análise causal conecta vários componentes poderosos:
- Processamento de dados com IA generativa: o modelo Nova Lite do Amazon Bedrock transforma textos de conversas não estruturados em features estruturadas que alimentam o modelo causal.
- Processamento de inferência causal: bibliotecas como a
causalnlp, com um learner como o LightGBM, analisam as relações entre features e resultados para quantificar os impactos causais. - Armazenamento baseado em grafo: o Neptune Analytics armazena os dados complexos e interconectados — tickets, features e relações causais calculadas — viabilizando uma exploração eficiente.
- Interface em linguagem natural: um agente do Bedrock consulta o grafo do Neptune Analytics via openCypher e entrega insights baseados em dados aos usuários em linguagem natural.
Essa arquitetura forma um pipeline completo, dos dados brutos aos insights acionáveis, com a IA generativa cumprindo um papel essencial: transformar dados conversacionais complexos em informações estruturadas e analisáveis.
Os resultados: insights causais detalhados
No nosso exemplo de satisfação do cliente, o sistema revelou insights quantitativos precisos:
- A resolução é o principal fator — resolver o problema do cliente causa um aumento de 42,9 pontos percentuais nas avaliações positivas.
- Problemas resolvidos recebem, em média, 83% de avaliações positivas.
- Problemas não resolvidos recebem, em média, 41% de avaliações positivas.
- A compreensão amplifica o efeito — quando o agente compreende o problema, há um ganho significativo.
- Quando os agentes compreendem: 67% de avaliações positivas.
- Quando os agentes não compreendem: 38% de avaliações positivas.
- Os efeitos combinados mostram o caminho ideal:
- Compreendido + Resolvido: 91% de avaliações positivas.
- Compreendido + Não resolvido: 52% de avaliações positivas.
- Não compreendido + Resolvido: 61% de avaliações positivas.
- Não compreendido + Não resolvido: 29% de avaliações positivas.
Esses detalhamentos apontam um caminho claro: priorizar a resolução dos problemas e, ao mesmo tempo, garantir que os agentes demonstrem compreensão cria as condições ideais para a satisfação do cliente.
Mas esses insights sobre satisfação do cliente são só um exemplo. A mesma abordagem poderia revelar:
- Na saúde: qual intervenção reduz com mais eficácia as readmissões hospitalares.
- Na educação: qual método de ensino tem o efeito causal mais forte sobre os resultados dos alunos.
- No e-commerce: quais recomendações de produtos realmente causam aumento nas compras.
- Na indústria: quais mudanças de processo de fato melhoram as métricas de qualidade.
- No RH: quais políticas de trabalho impactam causalmente a retenção de funcionários.
A implementação técnica
Essa abordagem exige apenas alguns componentes principais:
- Extração de dados com IA generativa — use modelos como Claude ou GPT para estruturar dados não estruturados.
- Modelagem de inferência causal — aplique técnicas estatísticas para identificar relações causais.
- Banco de dados em grafo para relações — armazene e consulte o modelo causal em um banco em grafo.
- Interface em linguagem natural — torne os insights acessíveis via IA conversacional.
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
Exemplos de consultas em OpenCypher
O poder do Neptune Analytics está na capacidade de consultar relações causais complexas com OpenCypher. Veja alguns exemplos de consultas que mostram esses recursos:
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
Essas consultas permitem explorar as relações causais no grafo e extrair insights acionáveis.
Aplicações de negócio: muito além dos insights técnicos
O poder dessa abordagem não está apenas na implementação técnica, mas em como os insights podem transformar as práticas de negócio:
- Treinamento e coaching de agentes: ao quantificar com precisão o quanto a resolução e a compreensão impactam a satisfação, as empresas conseguem desenhar programas de treinamento direcionados, focados nas habilidades de maior impacto.
- Melhoria de processos: entender os fatores causais por trás dos resultados permite redesenhar processos para obter o melhor desempenho, em vez de mudar com base em meras correlações.
- Insights democratizados: ao oferecer uma interface em linguagem natural para os insights causais, essa abordagem coloca a tomada de decisão baseada em dados nas mãos da equipe de linha de frente e dos gestores.
- Detecção de anomalias: o sistema consegue identificar casos em que fatores como sentimento não se alinham com as avaliações, abrindo espaço para investigação e aprendizado.
Por que isso importa em diferentes setores
A combinação de análise causal e IA generativa pode transformar a tomada de decisão em praticamente qualquer área:
- Vá além da correlação — entenda o que realmente causa os resultados que você quer.
- Quantifique o impacto — saiba exatamente quanto cada fator contribui.
- Priorize intervenções — concentre recursos onde eles terão o maior efeito causal.
- Torne os insights acessíveis — permita que stakeholders não técnicos façam perguntas causais.
Conclusão: só o começo
Este exemplo de satisfação do cliente mostra o potencial de combinar análise causal com IA generativa, mas mal arranha a superfície do que é possível. À medida que essas tecnologias ficarem mais acessíveis, as empresas que dominarem a compreensão causal terão vantagens significativas na tomada de decisão.
Convido você a pensar em onde a análise causal poderia transformar a sua área. Quais relações você já observou, mas tem dúvidas se são causais? Quais resultados você quer melhorar, mas não sabe ao certo quais alavancas puxar? São exatamente essas as perguntas que essa abordagem ajuda a responder.
Em qual área você aplicaria a análise causal? Quais resultados gostaria de entender de forma causal? Adoraria ouvir suas ideias nos comentários!
Para saber mais sobre a DoiT e o que podemos ajudar você a alcançar, acesse doit.com/services
Repositório no GitHub: https://github.com/eduamota/genai-causal-inference