Vous êtes-vous déjà demandé ce qui détermine vraiment les résultats dans les systèmes complexes ? L'analyse traditionnelle nous indique quels facteurs apparaissent ensemble, mais elle nous dit rarement si l'un cause réellement l'autre. Cette distinction est essentielle pour apporter des améliorations efficaces, quel que soit le domaine.
Aujourd'hui, je vous présente un projet qui montre comment l'association de l'analyse causale et de l'IA générative peut révéler des enseignements puissants. J'ai appliqué cette approche à la satisfaction client dans les interactions de support, mais ces mêmes techniques peuvent transformer pratiquement tout domaine où il importe de comprendre les véritables relations de cause à effet.
Lien ami : https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
Qu'est-ce que l'analyse causale ?
Prenons un instant pour comprendre ce qui rend l'analyse causale si puissante. Dans le monde de la donnée, nous croulons souvent sous les corrélations — ces choses qui surviennent en même temps. Par exemple, les ventes de glaces et les noyades augmentent toutes deux en été. Mais les glaces causent-elles les noyades ? Bien sûr que non. Elles partagent une cause commune : le temps chaud.
L'analyse causale va au-delà de la simple identification de schémas pour répondre à la question fondamentale : que se passe-t-il si nous intervenons ? C'est toute la différence entre :
- Corrélation : quand A se produit, B a aussi tendance à se produire.
- Causalité : si nous faisons en sorte que A se produise, cela entraînera B.
Le machine learning traditionnel excelle à repérer des schémas et à faire des prédictions, mais il peine à répondre aux questions et si qui guident la prise de décision. L'analyse causale comble cette lacune en fournissant un cadre pour comprendre les effets réels d'actions ou d'interventions.
Qu'est-ce que le NLP causal ?
Le NLP causal (traitement du langage naturel) se situe au croisement passionnant de la causalité et du traitement du langage. Il nous permet de :
- Extraire des relations causales d'un texte : identifier dans le langage naturel les moments où un événement ou un facteur en cause un autre.
- Appliquer un raisonnement causal aux données textuelles : recourir à des techniques avancées pour déterminer quels facteurs présents dans le texte influencent réellement les résultats.
- Transformer un texte non structuré en enseignements causaux : convertir un langage réel et désordonné en modèles causaux structurés.
Dans ce projet, j'ai utilisé causalnlp, une bibliothèque spécialisée qui combine techniques d'inférence causale et traitement du langage naturel. Elle nous permet d'aller au-delà de la simple analyse des mots qui apparaissent dans les retours d'un client satisfait, pour comprendre quels aspects de l'interaction ont causé sa satisfaction.
La puissance de la causalité associée à la GenAI
L'association de l'analyse causale et de l'IA générative est particulièrement puissante, car :
- La GenAI sait structurer des données non structurées — en convertissant des informations qualitatives (comme des conversations) en données structurées adaptées à l'analyse causale.
- L'analyse causale distingue corrélation et causalité — en passant de ces choses apparaissent ensemble à ceci cause cela.
- La GenAI rend les enseignements accessibles — en traduisant des résultats statistiques complexes en explications en langage naturel.
Je l'illustre ici avec des données de satisfaction client, mais imaginez la même approche appliquée aux résultats médicaux, à la performance pédagogique, à l'optimisation de la chaîne d'approvisionnement ou à la gestion des risques financiers. Les possibilités sont infinies.
Comprendre les données sources
Avant de plonger dans l'analyse, il est important de comprendre la structure des données qui alimentent ce système d'inférence causale. La base est un jeu de données de tickets de support client comprenant notamment les champs suivants :
- Identifiant du ticket (
ticket_id) : un identifiant unique pour chaque interaction de support. - Historique de conversation (
comment_history_table_string) : le journal textuel complet des échanges entre les clients et les agents de support. - Informations sur la plateforme et le produit :
custom_platform: détails sur la plateforme concernée (par ex. "amazon_web_services", "google_cloud_platform").custom_product: précise le produit ou le service auquel se rapporte le ticket.- Utilisation d'un cas de support (
cloud_support_case_used) : indique si un cas de support formel a été créé. - Évaluation client (
rating) : la note initiale fournie par le client (par ex. "good", "offered").
Ce jeu de données structuré, et en particulier l'historique textuel des conversations, sert d'entrée à l'analyse par IA générative qui alimente le processus d'inférence causale.
Un exemple simple : la satisfaction client
Pour démontrer la puissance de cette approche, j'ai construit un système qui analyse ce qui détermine vraiment la satisfaction client dans les interactions de support. Ce n'est qu'une application parmi d'autres — ces techniques s'adaptent à de nombreux autres domaines. Les données sont synthétiques, calquées sur la structure de données réelles.
Dépôt GitHub : https://github.com/eduamota/genai-causal-inference
Le pipeline de traitement des données
Pour commencer, j'extrais des informations structurées à partir des tickets de support bruts grâce à une série de scripts Python et à Amazon Bedrock :
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
Mon pipeline complet comprend :
- Analyse de sentiment (
01_sentiment_analysis.py) : recours au modèle Nova de Bedrock pour classer le ton émotionnel des conversations. - Conversion numérique (
02_convert_to_numeric.py) : transformation des données catégorielles en formats numériques. - Détection de résolution (
03_identify_resolution.py) : détermination de la résolution effective des problèmes, comme illustré dans le code ci-dessus. - Évaluation de la compréhension (
04_evaluate_understanding.py) : vérification que les agents ont bien saisi les problèmes des clients. - Création du graphe (
05_create_neptune_gremlin.py) : préparation des données pour le chargement dans Neptune Analytics.
Cette approche est largement transposable. Dans la santé, on peut extraire des diagnostics à partir de notes cliniques ; en finance, des facteurs de risque à partir de rapports ; en éducation, des schémas d'apprentissage à partir des interactions des étudiants.
Modélisation du graphe causal
Ensuite, je représente les relations sous forme de graphe dans Neptune Analytics :
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
Cette structure de graphe peut représenter des relations causales dans n'importe quel domaine. En santé, on peut modéliser la façon dont les traitements influent sur les résultats ; en éducation, l'incidence des méthodes pédagogiques sur l'apprentissage ; en finance, l'impact des changements de politique sur le comportement des marchés.
Schéma Neptune Analytics
Le schéma de graphe dans Neptune Analytics constitue la colonne vertébrale de notre système d'analyse causale. Voici sa structure :
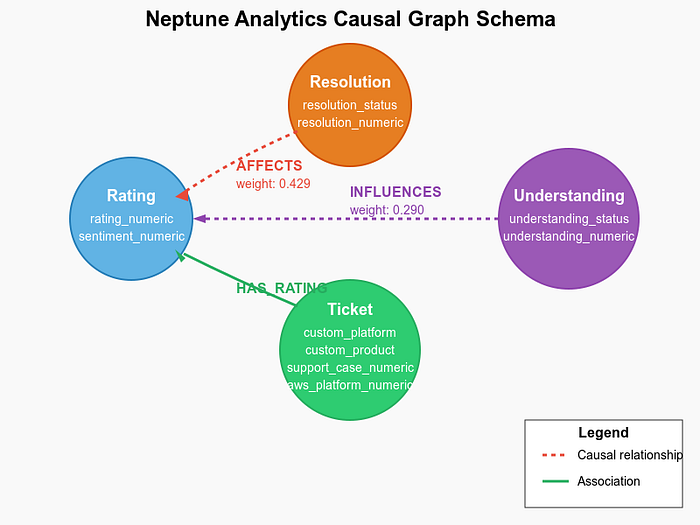
Schéma Neptune
Nœuds du graphe (sommets)
Le graphe contient plusieurs types de nœuds :
- Nœuds Rating : représentent les notes des clients, avec des propriétés telles que rating_numeric.
- Nœuds Resolution : indiquent si les problèmes ont été résolus (resolved/unresolved).
- Nœuds Understanding : reflètent la compréhension de l'agent (understood/misunderstood).
- Nœuds Ticket : contiennent toutes les propriétés d'origine du ticket et les indicateurs dérivés.
Relations du graphe (arêtes)
Les arêtes de notre graphe représentent les relations causales :
- Relation AFFECTS : relie le statut de résolution aux notes, avec des poids reflétant la force causale.
- Relation INFLUENCES : relie le statut de compréhension aux notes.
- Relation HAS_RATING : associe les tickets à leurs notes.
Cette structure de graphe ouvre la voie à des requêtes causales puissantes et à des visualisations des facteurs qui influencent la satisfaction client.
Calcul des effets causaux
À l'aide d'un modèle d'inférence causale, je calcule les effets de traitement réels :
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
Ce calcul révèle que résoudre le problème d'un client entraîne une hausse de 42,9 points de pourcentage des évaluations positives. Il s'agit d'une relation causale, et non d'une simple corrélation — une distinction essentielle pour engager des améliorations vraiment efficaces.
Interface en langage naturel avec Bedrock
Enfin, j'ai créé un agent Bedrock connecté à Neptune Analytics, qui permet aux utilisateurs de poser leurs questions en langage naturel :
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
Cette interface met des analyses causales complexes à la portée d'utilisateurs non techniques. Un médecin pourrait demander : quel traitement réduit le plus efficacement les taux de réadmission ?, ou un enseignant : quelle méthode pédagogique a le plus fort effet sur les résultats aux tests ?
Flux de données et architecture du système
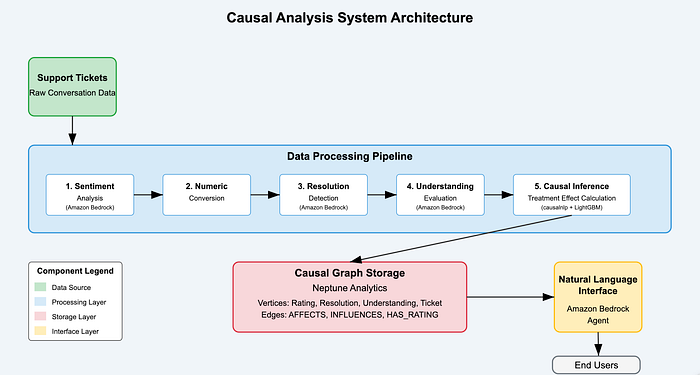
Diagramme d'architecture de la solution
![Diagramme d'architecture du système — Insérer ici un diagramme illustrant l'architecture complète et le flux de données entre les composants]
Le diagramme ci-dessus illustre le flux de données de bout en bout dans notre système d'analyse causale :
- Les données brutes des tickets entrent dans le pipeline.
- L'IA générative extrait des features à partir du texte non structuré.
- L'inférence causale calcule la force des effets.
- Neptune Analytics stocke la structure du graphe.
- L'agent Bedrock fournit un accès en langage naturel aux enseignements.
Cette architecture relie tous les composants en un pipeline fluide, des données brutes aux enseignements actionnables.
L'architecture : intégration de bout en bout
L'architecture complète de ce système d'analyse causale réunit plusieurs composants puissants :
- Traitement des données par IA générative : le modèle Nova Lite d'Amazon Bedrock transforme un texte de conversation non structuré en features structurées qui alimentent le modèle causal.
- Traitement par inférence causale : des bibliothèques telles que
causalnlp, associées à un learner comme LightGBM, analysent les relations entre features et résultats pour quantifier les impacts causaux. - Stockage orienté graphe : Neptune Analytics stocke les données complexes et interconnectées — tickets, features et relations causales calculées — et permet une exploration efficace.
- Interface en langage naturel : un agent Bedrock interroge le graphe Neptune Analytics via openCypher et restitue aux utilisateurs des enseignements basés sur les données, en langage naturel.
Cette architecture forme un pipeline complet, des données brutes aux enseignements actionnables, l'IA générative jouant un rôle clé dans la transformation de données conversationnelles complexes en informations structurées et exploitables.
Les résultats : des enseignements causaux détaillés
Dans notre exemple sur la satisfaction client, le système a fait ressortir des enseignements quantitatifs précis :
- La résolution est le principal levier — résoudre les problèmes des clients entraîne une hausse de 42,9 points de pourcentage des évaluations positives.
- Les problèmes résolus obtiennent en moyenne 83 % d'évaluations positives.
- Les problèmes non résolus obtiennent en moyenne 41 % d'évaluations positives.
- La compréhension amplifie l'effet — la compréhension de l'agent apporte un gain significatif.
- Quand les agents comprennent : 67 % d'évaluations positives.
- Quand les agents comprennent mal : 38 % d'évaluations positives.
- Les effets combinés tracent la voie optimale :
- Compris + Résolu : 91 % d'évaluations positives.
- Compris + Non résolu : 52 % d'évaluations positives.
- Mal compris + Résolu : 61 % d'évaluations positives.
- Mal compris + Non résolu : 29 % d'évaluations positives.
Ces décompositions détaillées indiquent une direction claire : prioriser la résolution des problèmes tout en s'assurant que les agents démontrent leur compréhension crée les conditions optimales de la satisfaction client.
Mais ces enseignements sur la satisfaction client ne sont qu'un exemple. La même approche pourrait révéler :
- En santé : quelle intervention réduit le plus efficacement les réadmissions hospitalières.
- En éducation : quelle méthode pédagogique a le plus fort effet causal sur les résultats des élèves.
- En e-commerce : quelles recommandations de produits entraînent réellement une hausse des achats.
- En industrie : quels changements de processus améliorent vraiment les indicateurs qualité.
- En RH : quelles politiques internes ont un impact causal sur la rétention des collaborateurs.
L'implémentation technique
Cette approche ne requiert que quelques composants essentiels :
- Extraction de données par IA générative — recourir à des modèles comme Claude ou GPT pour structurer des données non structurées.
- Modélisation par inférence causale — appliquer des techniques statistiques pour identifier les relations causales.
- Base de données graphe pour les relations — stocker et interroger le modèle causal dans une base orientée graphe.
- Interface en langage naturel — rendre les enseignements accessibles via une IA conversationnelle.
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
Exemples de requêtes OpenCypher
La puissance de Neptune Analytics tient à sa capacité à interroger des relations causales complexes via OpenCypher. Voici quelques exemples qui illustrent ses possibilités :
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
Ces requêtes permettent d'explorer les relations causales du graphe et d'en tirer des enseignements actionnables.
Applications métier : au-delà des enseignements techniques
La force de cette approche tient non seulement à son implémentation technique, mais aussi à la manière dont les enseignements peuvent transformer les pratiques métier :
- Formation et coaching des agents : en quantifiant précisément l'impact de la résolution et de la compréhension sur la satisfaction, les organisations peuvent bâtir des programmes de formation ciblés sur les compétences à plus fort effet.
- Amélioration des processus : comprendre les facteurs causaux qui déterminent les résultats permet aux organisations de repenser leurs processus en visant l'optimum, plutôt que d'opérer des changements fondés sur de simples corrélations.
- Démocratisation des enseignements : en proposant une interface en langage naturel pour accéder aux analyses causales, cette approche met la décision basée sur les données directement entre les mains des équipes terrain et des managers.
- Détection d'anomalies : le système sait repérer les cas où des facteurs comme le sentiment ne s'alignent pas avec les notes, mettant en lumière des pistes d'investigation et d'apprentissage.
Pourquoi cela compte dans tous les secteurs
L'association de l'analyse causale et de l'IA générative peut transformer la prise de décision dans pratiquement tous les domaines :
- Aller au-delà de la corrélation — comprendre ce qui cause réellement les résultats recherchés.
- Quantifier l'impact — savoir précisément ce que chaque facteur apporte.
- Prioriser les interventions — concentrer les ressources là où l'effet causal sera le plus fort.
- Rendre les enseignements accessibles — permettre à des parties prenantes non techniques de poser des questions causales.
Conclusion : ce n'est qu'un début
Cet exemple sur la satisfaction client illustre le potentiel de l'association entre analyse causale et IA générative, mais il n'effleure que la surface du possible. À mesure que ces technologies se démocratisent, les organisations qui maîtriseront la compréhension causale prendront une longueur d'avance dans leur prise de décision.
Je vous invite à réfléchir aux domaines où l'analyse causale pourrait transformer votre propre activité. Quelles relations avez-vous observées sans être certain qu'elles soient causales ? Quels résultats cherchez-vous à améliorer sans savoir précisément quels leviers actionner ? Ce sont précisément les questions auxquelles cette approche peut aider à répondre.
À quel domaine appliqueriez-vous l'analyse causale ? Quels résultats voudriez-vous appréhender de façon causale ? Je serais ravi de lire vos idées en commentaire.
Pour en savoir plus sur DoiT et sur ce que nous pouvons vous aider à accomplir, rendez-vous sur doit.com/services
Dépôt GitHub : https://github.com/eduamota/genai-causal-inference