Si è mai chiesto cosa determini davvero i risultati nei sistemi complessi? L'analisi tradizionale può dirci quali fattori compaiono insieme, ma raramente rivela se uno sia effettivamente la causa dell'altro. È una distinzione fondamentale per introdurre miglioramenti efficaci in qualsiasi ambito.
Oggi voglio condividere un progetto che mostra come l'unione tra analisi causale e AI generativa possa generare insight di grande valore. Ho applicato questo approccio alla soddisfazione del cliente nelle interazioni di supporto, ma le stesse tecniche possono trasformare praticamente ogni settore in cui contano le vere relazioni di causa-effetto.
Friendly link: https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
Cos'è l'analisi causale?
Soffermiamoci un momento su cosa renda l'analisi causale così potente. Nel mondo dei dati siamo spesso sommersi da correlazioni, cioè eventi che si manifestano insieme. Per esempio, le vendite di gelato e gli incidenti per annegamento aumentano entrambi in estate. Ma il gelato causa gli annegamenti? Ovviamente no: hanno una causa comune, il clima caldo.
L'analisi causale va oltre la semplice individuazione di pattern e risponde alla domanda fondamentale: "Cosa succede se interveniamo?". È la differenza tra:
- Correlazione: "Quando si verifica A, tende a verificarsi anche B".
- Causalità: "Se facciamo accadere A, questo farà accadere B".
Il machine learning tradizionale eccelle nell'individuare pattern e fare previsioni, ma fatica con le domande del tipo "cosa succederebbe se", quelle che guidano davvero le decisioni. L'analisi causale colma questa lacuna offrendo un framework per comprendere gli effetti reali di azioni e interventi.
Cos'è il Causal NLP?
Il Causal NLP (Natural Language Processing) si colloca all'intersezione tra causalità ed elaborazione del linguaggio. Ci permette di:
- Estrarre relazioni causali dal testo: identificare nel linguaggio naturale quando un evento o un fattore ne causa un altro.
- Applicare il ragionamento causale ai dati linguistici: usare tecniche avanzate per stabilire quali fattori, all'interno del testo, influenzano realmente i risultati.
- Trasformare il testo non strutturato in insight causali: convertire il linguaggio reale e disordinato in modelli causali strutturati.
In questo progetto ho utilizzato causalnlp, una libreria specializzata che combina tecniche di inferenza causale con l'elaborazione del linguaggio naturale. Ci permette di andare oltre la semplice analisi delle parole presenti nel feedback di un cliente soddisfatto, per capire quali aspetti dell'interazione abbiano causato quella soddisfazione.
La forza di causalità + GenAI
L'unione di analisi causale e AI generativa è particolarmente potente perché:
- La GenAI può strutturare dati non strutturati — converte le informazioni qualitative (come le conversazioni) in dati strutturati adatti all'analisi causale.
- L'analisi causale separa correlazione e causalità — supera il "queste cose si presentano insieme" per arrivare al "questa causa quella".
- La GenAI rende gli insight accessibili — traduce risultati statistici complessi in spiegazioni in linguaggio naturale.
Anche se la dimostrazione si basa su dati di customer satisfaction, immagini di applicare lo stesso approccio agli esiti sanitari, alle performance scolastiche, all'ottimizzazione della supply chain o alla gestione del rischio finanziario. Le possibilità sono infinite.
Comprendere i dati di origine
Prima di addentrarci nell'analisi, è importante capire la struttura dei dati che alimentano questo sistema di inferenza causale. La base è un dataset di ticket di supporto clienti con campi come:
- Identificativo del ticket (
ticket_id): identificatore univoco di ogni interazione di supporto. - Cronologia della conversazione (
comment_history_table_string): log testuale completo delle conversazioni tra clienti e agenti di supporto. - Informazioni su piattaforma e prodotto:
custom_platform: dettagli sulla piattaforma coinvolta (ad es. 'amazon_web_services', 'google_cloud_platform').custom_product: specifica il prodotto o il servizio a cui il ticket si riferisce.- Utilizzo del support case (
cloud_support_case_used): indica se è stato aperto un caso di supporto formale. - Valutazione del cliente (
rating): valutazione originale fornita dal cliente (ad es. 'good', 'offered').
Questo dataset strutturato, in particolare la cronologia testuale delle conversazioni, è l'input per l'analisi tramite AI generativa che alimenta l'inferenza causale.
Un esempio semplice: la soddisfazione del cliente
Per dimostrare la potenza di questo approccio ho realizzato un sistema che analizza ciò che davvero guida la soddisfazione del cliente nelle interazioni di supporto. È solo un'applicazione lineare: le tecniche sono adattabili a moltissimi altri ambiti. I dati sono sintetici, ma costruiti sulla struttura di dati reali.
Repository GitHub: https://github.com/eduamota/genai-causal-inference
La pipeline di elaborazione dei dati
Per prima cosa estraggo informazioni strutturate dai ticket di supporto grezzi tramite una serie di script Python e Amazon Bedrock:
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
La pipeline completa comprende:
- Sentiment analysis (
01_sentiment_analysis.py): usa il modello Nova di Bedrock per classificare il tono emotivo delle conversazioni. - Conversione numerica (
02_convert_to_numeric.py): trasforma i dati categorici in formato numerico. - Rilevazione della risoluzione (
03_identify_resolution.py): stabilisce se i problemi sono stati risolti, come illustrato nel codice qui sopra. - Valutazione della comprensione (
04_evaluate_understanding.py): verifica se gli agenti hanno effettivamente compreso i problemi del cliente. - Creazione del grafo (
05_create_neptune_gremlin.py): prepara i dati per il caricamento in Neptune Analytics.
L'approccio è ampiamente trasferibile: in sanità si possono estrarre diagnosi dalle note cliniche; in finanza, fattori di rischio dai report; nell'istruzione, pattern di apprendimento dalle interazioni con gli studenti.
Modellazione del grafo causale
Successivamente rappresento le relazioni come un grafo in Neptune Analytics:
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
Questa struttura a grafo può rappresentare relazioni causali in qualsiasi ambito. In sanità si potrebbe modellare l'effetto delle terapie sui risultati clinici; nell'istruzione, l'influenza dei metodi didattici sull'apprendimento; in finanza, l'impatto delle scelte di policy sul comportamento dei mercati.
Lo schema di Neptune Analytics
Lo schema del grafo in Neptune Analytics è la spina dorsale del nostro sistema di analisi causale. Eccone la struttura:
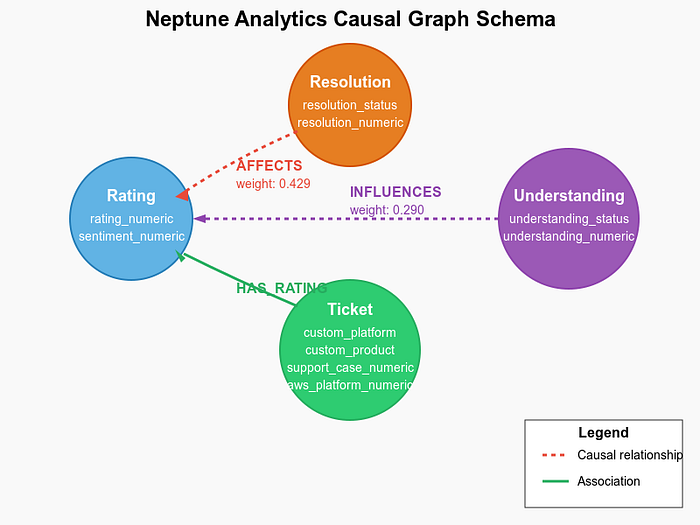
Schema di Neptune
Nodi del grafo (vertici)
Il grafo contiene diversi tipi di nodi:
- Nodi Rating: rappresentano le valutazioni dei clienti con proprietà come rating_numeric.
- Nodi Resolution: indicano se i problemi sono stati risolti (resolved/unresolved).
- Nodi Understanding: riflettono il grado di comprensione dell'agente (understood/misunderstood).
- Nodi Ticket: contengono tutte le proprietà originali del ticket e le metriche derivate.
Relazioni del grafo (archi)
Gli archi del grafo rappresentano le relazioni causali:
- Relazione AFFECTS: collega lo stato di risoluzione alle valutazioni, con pesi che esprimono la forza causale.
- Relazione INFLUENCES: collega lo stato di comprensione alle valutazioni.
- Relazione HAS_RATING: associa i ticket alle rispettive valutazioni.
Questa struttura abilita query causali avanzate e visualizzazioni dei fattori che influenzano la soddisfazione del cliente.
Calcolo degli effetti causali
Con un modello di inferenza causale calcolo gli effetti reali del trattamento:
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
Il calcolo rivela che risolvere il problema del cliente determina un aumento di 42,9 punti percentuali nelle valutazioni positive. Si tratta di una relazione causale, non di una semplice correlazione: una distinzione cruciale per introdurre miglioramenti efficaci.
Interfaccia in linguaggio naturale con Bedrock
Infine, ho realizzato un agente Bedrock connesso a Neptune Analytics che permette agli utenti di porre domande in linguaggio naturale:
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
Questa interfaccia rende insight causali complessi accessibili anche a utenti non tecnici. Un medico potrebbe chiedere "Quale terapia riduce in modo più efficace i tassi di riammissione?"; un docente potrebbe domandare "Quale metodo didattico ha l'effetto più forte sui risultati dei test?".
Flusso dei dati e architettura del sistema
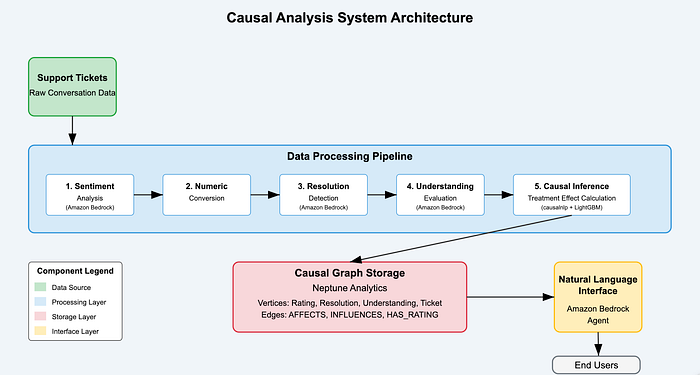
Diagramma dell'architettura della soluzione
![Diagramma dell'architettura del sistema — inserire qui il diagramma che illustra l'architettura completa con il flusso dei dati tra i componenti]
Il diagramma qui sopra illustra il flusso end-to-end dei dati nel nostro sistema di analisi causale:
- I dati grezzi dei ticket entrano nella pipeline.
- L'AI generativa estrae feature dal testo non strutturato.
- L'inferenza causale calcola l'intensità degli effetti.
- Neptune Analytics archivia la struttura del grafo.
- L'agente Bedrock fornisce un accesso in linguaggio naturale agli insight.
Questa architettura collega tutti i componenti in una pipeline fluida, dai dati grezzi agli insight pronti all'azione.
L'architettura: integrazione end-to-end
L'architettura completa di questo sistema di analisi causale unisce diversi componenti di grande valore:
- Elaborazione dei dati con AI generativa: il modello Nova Lite di Amazon Bedrock trasforma il testo non strutturato delle conversazioni in feature strutturate che alimentano il modello causale.
- Elaborazione dell'inferenza causale: librerie come
causalnlp, abbinate a un learner come LightGBM, analizzano le relazioni tra feature e risultati per quantificare gli impatti causali. - Archiviazione basata su grafi: Neptune Analytics conserva i dati complessi e interconnessi (ticket, feature e relazioni causali calcolate), permettendo un'esplorazione efficiente.
- Interfaccia in linguaggio naturale: un agente Bedrock interroga il grafo di Neptune Analytics tramite openCypher e restituisce agli utenti insight data-driven in linguaggio naturale.
Il risultato è una pipeline completa dai dati grezzi agli insight pronti all'azione, in cui l'AI generativa svolge un ruolo cruciale nel trasformare dati conversazionali complessi in informazioni strutturate e analizzabili.
I risultati: insight causali dettagliati
Nel nostro esempio sulla soddisfazione del cliente il sistema ha rivelato dati quantitativi molto precisi:
- La risoluzione è il fattore principale — risolvere il problema del cliente determina un aumento di 42,9 punti percentuali nelle valutazioni positive.
- I problemi risolti ricevono in media l'83% di valutazioni positive.
- I problemi non risolti ricevono in media il 41% di valutazioni positive.
- La comprensione amplifica l'effetto — la comprensione da parte dell'agente offre un incremento significativo.
- Quando gli agenti comprendono: 67% di valutazioni positive.
- Quando gli agenti fraintendono: 38% di valutazioni positive.
- Gli effetti combinati indicano il percorso ottimale:
- Compreso + Risolto: 91% di valutazioni positive.
- Compreso + Non risolto: 52% di valutazioni positive.
- Frainteso + Risolto: 61% di valutazioni positive.
- Frainteso + Non risolto: 29% di valutazioni positive.
Questi dati di dettaglio indicano una direzione chiara: dare priorità alla risoluzione del problema, assicurandosi al contempo che gli agenti dimostrino di aver compreso, crea le condizioni ottimali per la soddisfazione del cliente.
Ma quello sulla customer satisfaction è solo un esempio. Lo stesso approccio potrebbe rivelare:
- In sanità: quale intervento riduce con maggiore efficacia le riammissioni ospedaliere.
- Nell'istruzione: quale metodo didattico ha l'effetto causale più forte sui risultati degli studenti.
- Nell'e-commerce: quali raccomandazioni di prodotto causano davvero un aumento degli acquisti.
- Nel manufacturing: quali modifiche di processo migliorano realmente le metriche di qualità.
- Nelle HR: quali politiche aziendali influenzano causalmente la retention dei dipendenti.
L'implementazione tecnica
Questo approccio richiede solo pochi componenti chiave:
- Estrazione dei dati con AI generativa — usare modelli come Claude o GPT per dare struttura ai dati non strutturati.
- Modellazione di inferenza causale — applicare tecniche statistiche per identificare le relazioni causali.
- Database a grafo per le relazioni — archiviare e interrogare il modello causale in un graph database.
- Interfaccia in linguaggio naturale — rendere gli insight accessibili tramite AI conversazionale.
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
Esempi di query OpenCypher
La forza di Neptune Analytics sta nella capacità di interrogare relazioni causali complesse tramite OpenCypher. Ecco alcune query di esempio che ne mostrano le potenzialità:
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
Queste query consentono di esplorare le relazioni causali nel grafo ed estrarre insight pronti all'azione.
Applicazioni di business: oltre gli insight tecnici
La forza di questo approccio non sta solo nell'implementazione tecnica, ma nel modo in cui gli insight possono trasformare le pratiche di business:
- Formazione e coaching degli agenti: quantificando con precisione l'impatto di risoluzione e comprensione sulla soddisfazione, le organizzazioni possono sviluppare programmi di formazione mirati sulle competenze a maggiore impatto.
- Miglioramento dei processi: comprendere i fattori causali che guidano i risultati permette alle organizzazioni di ridisegnare i processi per ottenere risultati ottimali, anziché introdurre cambiamenti basati su semplici correlazioni.
- Insight democratizzati: offrendo un'interfaccia in linguaggio naturale agli insight causali, questo approccio mette le decisioni data-driven direttamente nelle mani del personale operativo e dei manager.
- Rilevamento di anomalie: il sistema può individuare i casi in cui fattori come il sentiment non sono allineati alle valutazioni, evidenziando opportunità di indagine e apprendimento.
Perché conta in tutti i settori
L'unione di analisi causale e AI generativa può trasformare il processo decisionale praticamente in ogni ambito:
- Andare oltre la correlazione — capire cosa causa davvero i risultati desiderati.
- Quantificare l'impatto — sapere esattamente quanto contribuisce ciascun fattore.
- Stabilire le priorità degli interventi — concentrare le risorse dove avranno il maggiore effetto causale.
- Rendere accessibili gli insight — permettere agli stakeholder non tecnici di porre domande causali.
Conclusioni: solo l'inizio
Questo esempio sulla soddisfazione del cliente mostra il potenziale dell'unione tra analisi causale e AI generativa, ma scalfisce appena la superficie di ciò che è possibile fare. Man mano che queste tecnologie diventeranno più accessibili, le organizzazioni che sapranno valorizzare la comprensione causale otterranno un vantaggio significativo nelle decisioni.
Le suggerisco di pensare a dove l'analisi causale potrebbe trasformare il suo settore. Quali relazioni ha osservato senza essere certo che siano causali? Quali risultati sta cercando di migliorare senza sapere su quali leve agire? Sono proprio le domande a cui questo approccio può rispondere.
A quale ambito applicherebbe l'analisi causale? Quali risultati vorrebbe comprendere in chiave causale? Mi piacerebbe leggere le sue idee nei commenti!
Per saperne di più su DoiT e su ciò che possiamo aiutarla a realizzare, visiti doit.com/services
Repository GitHub: https://github.com/eduamota/genai-causal-inference