Haben Sie sich schon einmal gefragt, was Ergebnisse in komplexen Systemen wirklich bestimmt? Klassische Analysen zeigen uns zwar, welche Faktoren gemeinsam auftreten, sagen aber selten, ob einer davon einen anderen tatsächlich verursacht. Diese Unterscheidung ist entscheidend, wenn Sie in irgendeinem Bereich wirksame Verbesserungen erzielen wollen.
Heute stelle ich Ihnen ein Projekt vor, das zeigt, wie sich aus der Kombination von Kausalanalyse und generativer KI starke Erkenntnisse gewinnen lassen. Ich habe diesen Ansatz auf die Kundenzufriedenheit im Support angewendet – dieselben Methoden lassen sich aber praktisch in jedem Feld einsetzen, in dem es darauf ankommt, echte Ursache-Wirkungs-Zusammenhänge zu verstehen.
Friendly Link: https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
Was ist Kausalanalyse?
Schauen wir uns kurz an, warum Kausalanalyse so wirkungsvoll ist. In der Datenwelt ertrinken wir oft in Korrelationen – also in Dingen, die gemeinsam auftreten. Im Sommer steigen zum Beispiel sowohl der Eisverkauf als auch die Zahl der Ertrinkungsunfälle. Verursacht Eis aber Ertrinken? Natürlich nicht. Beide haben dieselbe Ursache: warmes Wetter.
Die Kausalanalyse geht über das bloße Erkennen von Mustern hinaus und beantwortet die zentrale Frage: "Was passiert, wenn wir eingreifen?" Es ist der Unterschied zwischen:
- Korrelation: "Wenn A eintritt, tritt häufig auch B ein."
- Kausalität: "Wenn wir A herbeiführen, folgt daraus B."
Klassisches Machine Learning ist stark darin, Muster zu erkennen und Vorhersagen zu treffen, scheitert aber an den "Was-wäre-wenn"-Fragen, die für Entscheidungen den Ausschlag geben. Genau diese Lücke schließt die Kausalanalyse: Sie liefert einen Rahmen, um die tatsächlichen Auswirkungen von Maßnahmen oder Eingriffen zu verstehen.
Was ist Causal NLP?
Causal NLP (Natural Language Processing) sitzt an der spannenden Schnittstelle von Kausalität und Sprachverarbeitung. Damit lassen sich:
- Kausale Beziehungen aus Text extrahieren: erkennen, wann ein Ereignis oder Faktor in natürlicher Sprache ein anderes auslöst.
- Kausales Schlussfolgern auf Sprachdaten anwenden: mit fortgeschrittenen Methoden bestimmen, welche Faktoren im Text Ergebnisse tatsächlich beeinflussen.
- Unstrukturierten Text in kausale Erkenntnisse überführen: chaotische, reale Sprache in strukturierte Kausalmodelle bringen.
In diesem Projekt nutze ich causalnlp, eine spezialisierte Bibliothek, die kausale Inferenztechniken mit Natural Language Processing verbindet. So gehen wir über die reine Frage hinaus, welche Wörter im Feedback eines zufriedenen Kunden auftauchen, und verstehen, welche Aspekte der Interaktion seine Zufriedenheit tatsächlich verursacht haben.
Die Stärke von Kausalität + GenAI
Die Kombination aus Kausalanalyse und generativer KI ist aus mehreren Gründen besonders schlagkräftig:
- GenAI strukturiert unstrukturierte Daten – qualitative Informationen (etwa aus Gesprächen) werden in strukturierte Daten überführt, die sich für die Kausalanalyse eignen.
- Kausalanalyse trennt Korrelation von Kausalität – wir kommen vom "diese Dinge treten gemeinsam auf" zum "dies verursacht jenes".
- GenAI macht Erkenntnisse zugänglich – komplexe statistische Befunde werden in natürlichsprachliche Erklärungen übersetzt.
Ich zeige das anhand von Daten zur Kundenzufriedenheit. Stellen Sie sich aber vor, denselben Ansatz auf Behandlungsergebnisse im Gesundheitswesen, schulische Leistungen, Lieferketten-Optimierung oder das Management von Finanzrisiken anzuwenden. Die Möglichkeiten sind grenzenlos.
Die Quelldaten verstehen
Bevor wir in die Analyse einsteigen, lohnt ein Blick auf die Struktur der Daten, die diesem Kausalinferenz-System zugrunde liegen. Die Basis bildet ein Datensatz aus Kundensupport-Tickets mit Feldern wie:
- Ticket-ID (
ticket_id): eindeutige Kennung für jede Support-Interaktion. - Gesprächsverlauf (
comment_history_table_string): vollständiges Textprotokoll der Konversationen zwischen Kunden und Support-Agents. - Plattform- und Produktinformationen:
custom_platform: Angaben zur betreffenden Plattform (z. B. "amazon_web_services", "google_cloud_platform").custom_product: nennt das Produkt oder den Service, auf den sich das Ticket bezieht.- Support-Case-Nutzung (
cloud_support_case_used): gibt an, ob ein formeller Support-Case angelegt wurde. - Kundenbewertung (
rating): ursprüngliche Bewertung des Kunden (z. B. "good", "offered").
Dieser strukturierte Datensatz – insbesondere der textuelle Gesprächsverlauf – ist die Eingabe für die generative KI-Analyse, die den Kausalinferenz-Prozess speist.
Ein einfaches Beispiel: Kundenzufriedenheit
Um die Stärke des Ansatzes zu zeigen, habe ich ein System gebaut, das analysiert, was Kundenzufriedenheit in Support-Interaktionen wirklich treibt. Das ist nur eine geradlinige Anwendung – die Methoden lassen sich auf viele andere Bereiche übertragen. Die Daten sind synthetisch und orientieren sich an der Struktur realer Daten.
GitHub-Repository: https://github.com/eduamota/genai-causal-inference
Die Datenverarbeitungs-Pipeline
Zunächst extrahiere ich mit mehreren Python-Skripten und Amazon Bedrock strukturierte Informationen aus den Roh-Tickets:
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
Meine vollständige Pipeline umfasst:
- Sentiment-Analyse (
01_sentiment_analysis.py): Mit dem Nova-Modell von Bedrock wird der emotionale Tonfall der Konversationen klassifiziert. - Numerische Konvertierung (
02_convert_to_numeric.py): Kategoriale Daten werden in numerische Formate überführt. - Lösungserkennung (
03_identify_resolution.py): Es wird ermittelt, ob die Probleme gelöst wurden – wie im Code oben gezeigt. - Bewertung des Verständnisses (
04_evaluate_understanding.py): Es wird beurteilt, ob die Agents die Kundenprobleme richtig verstanden haben. - Graph-Erstellung (
05_create_neptune_gremlin.py): Die Daten werden für den Import in Neptune Analytics aufbereitet.
Der Ansatz ist breit übertragbar. Im Gesundheitswesen ließen sich Diagnosen aus Arztbriefen extrahieren, im Finanzwesen Risikofaktoren aus Berichten, im Bildungsbereich Lernmuster aus Schülerinteraktionen.
Modellierung des Kausalgraphen
Anschließend bilde ich die Beziehungen als Graph in Neptune Analytics ab:
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
Diese Graphstruktur kann kausale Zusammenhänge in jedem Feld abbilden. Im Gesundheitswesen ließe sich modellieren, wie Behandlungen Ergebnisse beeinflussen, im Bildungsbereich, wie Lehrmethoden das Lernen prägen, im Finanzwesen, wie politische Entscheidungen das Marktverhalten verändern.
Neptune-Analytics-Schema
Das Graph-Schema in Neptune Analytics bildet das Rückgrat unseres Kausalanalyse-Systems. So sieht die Struktur aus:
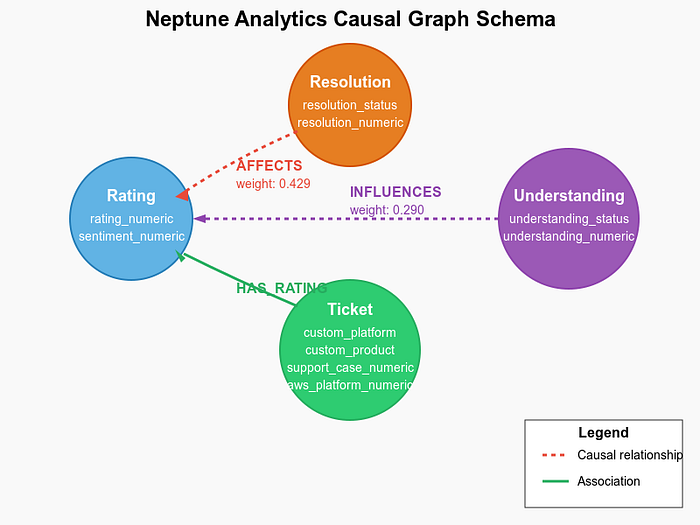
Neptune-Schema
Graph-Knoten (Vertices)
Der Graph enthält mehrere Knotentypen:
- Rating-Knoten: bilden Kundenbewertungen mit Eigenschaften wie rating_numeric ab.
- Resolution-Knoten: erfassen, ob Probleme gelöst wurden (resolved/unresolved).
- Understanding-Knoten: spiegeln das Verständnis des Agents wider (understood/misunderstood).
- Ticket-Knoten: enthalten alle ursprünglichen Ticket-Eigenschaften und abgeleiteten Kennzahlen.
Graph-Beziehungen (Edges)
Die Kanten in unserem Graph stehen für die kausalen Beziehungen:
- AFFECTS-Beziehung: verbindet den Lösungsstatus mit Bewertungen, wobei die Gewichte die kausale Stärke abbilden.
- INFLUENCES-Beziehung: verknüpft den Verständnisstatus mit Bewertungen.
- HAS_RATING-Beziehung: ordnet Tickets ihren Bewertungen zu.
Diese Graphstruktur ermöglicht aussagekräftige kausale Abfragen und Visualisierungen der Faktoren, die die Kundenzufriedenheit beeinflussen.
Kausale Effekte berechnen
Mit einem Kausalinferenz-Modell berechne ich die tatsächlichen Treatment-Effekte:
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
Das Ergebnis: Wird ein Kundenproblem gelöst, steigt der Anteil positiver Bewertungen kausal um 42,9 Prozentpunkte. Es geht hier um eine kausale Beziehung, nicht um eine bloße Korrelation – ein entscheidender Unterschied, wenn Sie wirksame Verbesserungen erreichen wollen.
Natürlichsprachliche Schnittstelle mit Bedrock
Zum Schluss habe ich einen Bedrock-Agent gebaut, der sich mit Neptune Analytics verbindet und es Nutzern erlaubt, Fragen in natürlicher Sprache zu stellen:
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
Diese Schnittstelle macht komplexe kausale Erkenntnisse auch für nicht-technische Nutzer zugänglich. Eine Ärztin könnte fragen: "Welche Behandlung senkt die Wiederaufnahmerate am wirksamsten?" Eine Lehrkraft könnte wissen wollen: "Welche Lehrmethode hat den stärksten Effekt auf die Testergebnisse?"
Datenfluss und Systemarchitektur
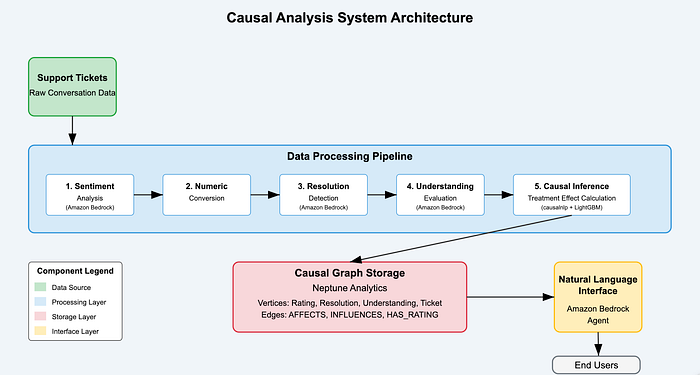
Diagramm der Lösungsarchitektur
![Systemarchitektur-Diagramm — Diagramm einfügen, das die vollständige Systemarchitektur mit dem Datenfluss zwischen den Komponenten zeigt]
Das Diagramm oben zeigt den End-to-End-Datenfluss durch unser Kausalanalyse-System:
- Rohe Ticketdaten gelangen in die Pipeline.
- Generative KI extrahiert Features aus unstrukturiertem Text.
- Kausale Inferenz berechnet die Stärke der Effekte.
- Neptune Analytics speichert die Graphstruktur.
- Ein Bedrock-Agent ermöglicht den natürlichsprachlichen Zugriff auf die Erkenntnisse.
So entsteht eine nahtlose Pipeline – von Rohdaten bis zu umsetzbaren Erkenntnissen.
Die Architektur: End-to-End-Integration
Die vollständige Architektur dieses Kausalanalyse-Systems verbindet mehrere leistungsstarke Komponenten:
- Datenverarbeitung mit generativer KI: Das Nova-Lite-Modell von Amazon Bedrock verwandelt unstrukturierten Konversationstext in strukturierte Features, die das Kausalmodell speisen.
- Kausale Inferenzverarbeitung: Bibliotheken wie
causalnlpin Verbindung mit einem Learner wie LightGBM analysieren die Beziehungen zwischen Features und Ergebnissen und quantifizieren so kausale Effekte. - Graphbasierte Speicherung: Neptune Analytics speichert die komplexen, vernetzten Daten – darunter Tickets, Features und berechnete kausale Beziehungen – und erlaubt eine effiziente Erkundung.
- Natürlichsprachliche Schnittstelle: Ein Bedrock-Agent fragt den Neptune-Analytics-Graphen über openCypher ab und liefert datenbasierte Erkenntnisse in natürlicher Sprache.
Diese Architektur bildet eine durchgängige Pipeline von Rohdaten zu umsetzbaren Erkenntnissen. Generative KI spielt dabei eine Schlüsselrolle: Sie überführt komplexe Konversationsdaten in strukturierte, analysierbare Informationen.
Die Ergebnisse: detaillierte kausale Erkenntnisse
In unserem Beispiel zur Kundenzufriedenheit lieferte das System präzise quantitative Ergebnisse:
- Lösung ist der wichtigste Treiber – Das Lösen von Kundenproblemen lässt den Anteil positiver Bewertungen kausal um 42,9 Prozentpunkte steigen.
- Gelöste Anliegen erreichen im Schnitt 83 % positive Bewertungen.
- Ungelöste Anliegen erreichen im Schnitt 41 % positive Bewertungen.
- Verständnis verstärkt den Effekt – Versteht der Agent das Anliegen, sorgt das für einen deutlichen Schub.
- Wenn Agents verstehen: 67 % positive Bewertungen.
- Wenn Agents missverstehen: 38 % positive Bewertungen.
- Kombinierte Effekte zeigen den optimalen Pfad:
- Verstanden + gelöst: 91 % positive Bewertungen.
- Verstanden + ungelöst: 52 % positive Bewertungen.
- Missverstanden + gelöst: 61 % positive Bewertungen.
- Missverstanden + ungelöst: 29 % positive Bewertungen.
Die Aufschlüsselung zeigt eine klare Richtung: Problemlösung priorisieren und gleichzeitig sicherstellen, dass Agents echtes Verständnis zeigen – das schafft die optimalen Bedingungen für Kundenzufriedenheit.
Diese Erkenntnisse zur Kundenzufriedenheit sind aber nur ein Beispiel. Derselbe Ansatz könnte zeigen:
- Im Gesundheitswesen: welche Intervention Krankenhaus-Wiederaufnahmen am wirksamsten reduziert.
- Im Bildungsbereich: welche Lehrmethode den stärksten kausalen Effekt auf Schülerleistungen hat.
- Im E-Commerce: welche Produktempfehlungen tatsächlich zu mehr Käufen führen.
- In der Fertigung: welche Prozessänderungen Qualitätskennzahlen wirklich verbessern.
- Im HR-Bereich: welche Unternehmensrichtlinien die Mitarbeiterbindung kausal beeinflussen.
Die technische Umsetzung
Der Ansatz braucht nur wenige Kernkomponenten:
- Datenextraktion mit generativer KI – Modelle wie Claude oder GPT einsetzen, um unstrukturierte Daten zu strukturieren.
- Kausale Inferenzmodellierung – statistische Verfahren nutzen, um kausale Beziehungen zu identifizieren.
- Graphdatenbank für die Beziehungen – das Kausalmodell in einer Graphdatenbank speichern und abfragen.
- Natürlichsprachliche Schnittstelle – Erkenntnisse über Conversational AI zugänglich machen.
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
Beispiele für OpenCypher-Abfragen
Die Stärke von Neptune Analytics liegt darin, komplexe kausale Beziehungen mit OpenCypher abzufragen. Hier einige Beispielabfragen, die das veranschaulichen:
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
Mit solchen Abfragen erkunden wir die kausalen Beziehungen im Graphen und gewinnen daraus umsetzbare Erkenntnisse.
Anwendung im Unternehmen: mehr als nur technische Erkenntnisse
Die Stärke dieses Ansatzes liegt nicht allein in der technischen Umsetzung, sondern darin, wie die Erkenntnisse die Geschäftspraxis verändern können:
- Schulung und Coaching von Agents: Wer präzise quantifiziert, wie stark Lösung und Verständnis die Zufriedenheit beeinflussen, kann gezielte Trainingsprogramme entwickeln, die genau auf die wirkungsvollsten Fähigkeiten abzielen.
- Prozessverbesserung: Wer die kausalen Treiber von Ergebnissen kennt, kann Prozesse für optimale Ergebnisse umgestalten – statt Änderungen auf Basis bloßer Korrelationen anzustoßen.
- Demokratisierte Erkenntnisse: Die natürlichsprachliche Schnittstelle bringt datenbasierte Entscheidungen direkt zu den Mitarbeitenden an der Front und zu den Führungskräften.
- Anomalieerkennung: Das System spürt Fälle auf, in denen Faktoren wie das Sentiment nicht zu den Bewertungen passen, und liefert so Ansatzpunkte für Untersuchung und Lernen.
Warum das branchenübergreifend zählt
Die Kombination aus Kausalanalyse und generativer KI kann die Entscheidungsfindung in praktisch jedem Bereich verändern:
- Über Korrelation hinausgehen – verstehen, was Ihre gewünschten Ergebnisse tatsächlich verursacht.
- Wirkung quantifizieren – exakt wissen, wie viel jeder Faktor beiträgt.
- Maßnahmen priorisieren – Ressourcen dort einsetzen, wo sie den größten kausalen Effekt entfalten.
- Erkenntnisse zugänglich machen – auch nicht-technischen Stakeholdern erlauben, kausale Fragen zu stellen.
Fazit: erst der Anfang
Dieses Beispiel zur Kundenzufriedenheit zeigt das Potenzial, Kausalanalyse mit generativer KI zu verbinden – und kratzt dabei nur an der Oberfläche dessen, was möglich ist. Je zugänglicher diese Technologien werden, desto deutlicher werden die Vorteile für Organisationen, die kausales Verständnis konsequent nutzen.
Ich lade Sie ein, darüber nachzudenken, wo Kausalanalyse Ihren eigenen Bereich verändern könnte. Welche Beziehungen haben Sie beobachtet, ohne sicher zu sein, ob sie kausal sind? Welche Ergebnisse möchten Sie verbessern, wissen aber nicht genau, an welchen Stellschrauben Sie drehen sollten? Genau diese Fragen kann dieser Ansatz beantworten.
In welchem Bereich würden Sie Kausalanalyse einsetzen? Welche Ergebnisse würden Sie kausal verstehen wollen? Ich freue mich auf Ihre Ideen in den Kommentaren!
Mehr darüber, wie DoiT Sie unterstützen kann, erfahren Sie unter doit.com/services
GitHub-Repository: https://github.com/eduamota/genai-causal-inference