¿Te has preguntado qué determina realmente los resultados en sistemas complejos? La analítica tradicional suele indicarnos qué factores aparecen juntos, pero rara vez nos dice si uno efectivamente causa al otro. Esta distinción es clave para lograr mejoras reales en cualquier ámbito.
Hoy quiero compartir un proyecto que muestra cómo combinar el análisis causal con la IA generativa para obtener insights muy valiosos. Apliqué este enfoque a la satisfacción del cliente en interacciones de soporte, pero las mismas técnicas sirven para prácticamente cualquier campo donde importe entender las verdaderas relaciones de causa y efecto.
Enlace de cortesía: https://medium.com/@edu7mota/d6bb91a19b6f?source=friends_link&sk=a6099b13d912952eb3714d222a4c062f
¿Qué es el análisis causal?
Detengámonos un momento a pensar qué hace tan poderoso al análisis causal. En el mundo de los datos, solemos estar inundados de correlaciones: cosas que ocurren al mismo tiempo. Por ejemplo, las ventas de helado y los incidentes de ahogamiento aumentan en verano. ¿El helado provoca los ahogamientos? Por supuesto que no. Comparten una causa común: el clima cálido.
El análisis causal va más allá de identificar patrones para responder a la pregunta de fondo: "¿Qué pasa si intervenimos?". Es la diferencia entre:
- Correlación: "Cuando ocurre A, también suele ocurrir B".
- Causalidad: "Si hacemos que A ocurra, B ocurrirá como consecuencia".
El machine learning tradicional es excelente para encontrar patrones y hacer predicciones, pero le cuesta responder a las preguntas del tipo "¿qué pasaría si…?" que guían la toma de decisiones. El análisis causal cubre ese vacío al ofrecer un marco para entender los efectos reales de las acciones o intervenciones.
¿Qué es el NLP causal?
El NLP causal (Procesamiento de Lenguaje Natural) se sitúa en la apasionante intersección entre la causalidad y el procesamiento del lenguaje. Permite:
- Extraer relaciones causales del texto: identificar cuándo un evento o factor causa otro en lenguaje natural.
- Aplicar razonamiento causal a datos lingüísticos: usar técnicas avanzadas para determinar qué factores del texto realmente influyen en los resultados.
- Convertir texto no estructurado en insights causales: transformar el lenguaje desordenado del mundo real en modelos causales estructurados.
En este proyecto utilicé causalnlp, una librería especializada que combina técnicas de inferencia causal con procesamiento de lenguaje natural. Nos permite ir más allá de analizar qué palabras aparecen en el feedback de un cliente satisfecho y entender qué aspectos de la interacción causaron esa satisfacción.
El poder de la causalidad + GenAI
La combinación de análisis causal e IA generativa resulta especialmente poderosa porque:
- La GenAI estructura datos no estructurados: convierte información cualitativa (como conversaciones) en datos estructurados aptos para el análisis causal.
- El análisis causal separa la correlación de la causalidad: va más allá del "estas cosas aparecen juntas" para llegar al "esto causa aquello".
- La GenAI hace accesibles los insights: traduce hallazgos estadísticos complejos a explicaciones en lenguaje natural.
Aunque lo demostraré con datos de satisfacción del cliente, imagina aplicar el mismo enfoque a resultados clínicos, desempeño educativo, optimización de la cadena de suministro o gestión del riesgo financiero. Las posibilidades son infinitas.
Entender los datos de origen
Antes de entrar al análisis, conviene comprender la estructura de los datos que alimentan este sistema de inferencia causal. La base es un dataset de tickets de soporte al cliente con campos como:
- Identificador del ticket (
ticket_id): un identificador único para cada interacción de soporte. - Historial de la conversación (
comment_history_table_string): el registro textual completo de las conversaciones entre clientes y agentes de soporte. - Información de plataforma y producto:
custom_platform: detalles sobre la plataforma involucrada (por ejemplo, 'amazon_web_services', 'google_cloud_platform').custom_product: especifica el producto o servicio al que corresponde el ticket.- Uso del caso de soporte (
cloud_support_case_used): si se creó un caso de soporte formal. - Calificación del cliente (
rating): la calificación original entregada por el cliente (por ejemplo, 'good', 'offered').
Este dataset estructurado, en particular el historial textual de la conversación, sirve como entrada para el análisis con IA generativa que impulsa el proceso de inferencia causal.
Un ejemplo sencillo: la satisfacción del cliente
Para mostrar el potencial de este enfoque, construí un sistema que analiza qué impulsa realmente la satisfacción del cliente en las interacciones de soporte. Es solo una aplicación directa: las técnicas se adaptan a muchos otros dominios. Los datos son sintéticos y se basan en la estructura de datos reales.
Repositorio en GitHub: https://github.com/eduamota/genai-causal-inference
El pipeline de procesamiento de datos
Primero, extraigo información estructurada a partir de los tickets de soporte sin procesar mediante una serie de scripts en Python y Amazon Bedrock:
def analyze_resolution_with_nova(text, bedrock_client):
"""
Use Amazon Bedrock's Nova Lite model to determine if the issue was resolved.
"""
prompt = f"""Context: You are analyzing a support ticket conversation.
Based on the conversation history, determine if the customer's issue was resolved or not.
Only respond with the word 'resolved' or 'unresolved'.
Conversation history:
{text}
Was the issue resolved?"""
messages = [\
{"role": "user", "content": [{"text": prompt}]},\
]
inf_params = {"maxTokens": 100, "topP": 0.1, "temperature": 0.1}
try:
response = bedrock_client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
inferenceConfig=inf_params
)
result = response["output"]["message"]["content"][0]["text"].lower()
# Return the analysis result
if 'resolved' in result and 'unresolved' not in result:
return 'resolved'
else:
return 'unresolved'
except Exception as e:
print(f"Error analyzing resolution: {e}")
return None
Mi pipeline completo incluye:
- Análisis de sentimiento (
01_sentiment_analysis.py): usa el modelo Nova de Bedrock para clasificar el tono emocional de las conversaciones. - Conversión numérica (
02_convert_to_numeric.py): transforma datos categóricos en formatos numéricos. - Detección de resolución (
03_identify_resolution.py): determina si los problemas se resolvieron, como muestra el código anterior. - Evaluación de la comprensión (
04_evaluate_understanding.py): evalúa si los agentes entendieron correctamente los problemas del cliente. - Creación del grafo (
05_create_neptune_gremlin.py): prepara los datos para cargarlos en Neptune Analytics.
Este enfoque es ampliamente aplicable. En salud podrías extraer diagnósticos a partir de notas clínicas; en finanzas, factores de riesgo a partir de reportes; en educación, patrones de aprendizaje a partir de las interacciones con los estudiantes.
Modelado del grafo causal
Luego represento las relaciones como un grafo en Neptune Analytics:
# Convert dataframe to Neptune-compatible graph format
def convert_to_neptune_gremlin_csv(df, output_dir):
"""
Convert a dataframe to Neptune-compatible Gremlin CSV format
"""
# Create vertices for different entity types
rating_vertices = df.copy()
rating_vertices['~id'] = 'rating_' + rating_vertices.index.astype(str)
rating_vertices['~label'] = 'rating'
resolution_vertices = df[['resolution_status', 'resolution_numeric']].drop_duplicates()
resolution_vertices['~id'] = 'resolution_' + resolution_vertices['resolution_status']
resolution_vertices['~label'] = 'resolution'
# Create edges representing causal relationships
resolution_rating_edges = df.copy()
resolution_rating_edges['~id'] = 'edge_res_rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~from'] = 'resolution_' + resolution_rating_edges['resolution_status']
resolution_rating_edges['~to'] = 'rating_' + resolution_rating_edges.index.astype(str)
resolution_rating_edges['~label'] = 'AFFECTS'
resolution_rating_edges['weight'] = resolution_rating_edges['resolution_effect']
Esta estructura de grafo sirve para representar relaciones causales en cualquier dominio. En salud podrías modelar cómo los tratamientos afectan los resultados; en educación, cómo los métodos de enseñanza influyen en el aprendizaje; en finanzas, cómo los cambios de política impactan el comportamiento del mercado.
Esquema de Neptune Analytics
El esquema del grafo en Neptune Analytics es la columna vertebral de nuestro sistema de análisis causal. Esta es su estructura:
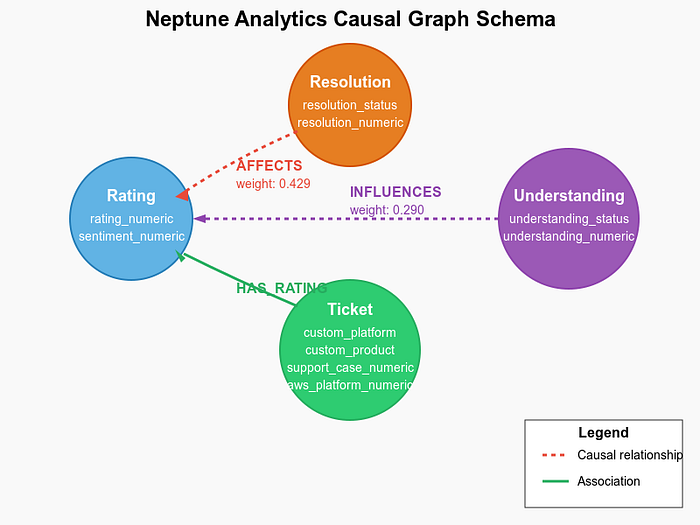
Esquema de Neptune
Nodos del grafo (vértices)
El grafo contiene varios tipos de nodos:
- Nodos de calificación: representan las calificaciones de los clientes con propiedades como rating_numeric.
- Nodos de resolución: registran si los problemas se resolvieron (resolved/unresolved).
- Nodos de comprensión: reflejan la comprensión del agente (understood/misunderstood).
- Nodos de ticket: contienen todas las propiedades originales del ticket y las métricas derivadas.
Relaciones del grafo (aristas)
Las aristas de nuestro grafo representan las relaciones causales:
- Relación AFFECTS: conecta el estado de resolución con las calificaciones, con pesos que representan la fuerza causal.
- Relación INFLUENCES: enlaza el estado de comprensión con las calificaciones.
- Relación HAS_RATING: asocia los tickets con sus calificaciones.
Esta estructura de grafo permite consultas causales potentes y visualizar los factores que influyen en la satisfacción del cliente.
Cálculo de los efectos causales
Con un modelo de inferencia causal, calculo los efectos reales del tratamiento:
from causalnlp import CausalInferenceModel
from lightgbm import LGBMClassifier
# Create a causal inference model
cm = CausalInferenceModel(df,
metalearner_type='t-learner',
learner=LGBMClassifier(num_leaves=10),
treatment_col='resolution_numeric',
outcome_col='rating_numeric',
text_col='comment_history_table_string',
include_cols=['aws_platform_numeric', 'custom_product',\
'sentiment', 'support_case_numeric',\
'understanding_numeric'])
# Fit and estimate causal effects
cm.fit()
ate = cm.estimate_ate()
print(f"Average Treatment Effect: {ate['ate']}")
# Output: Average Treatment Effect: 0.4294348212219044
Este cálculo revela que resolver el problema de un cliente provoca un aumento de 42.9 puntos porcentuales en las calificaciones positivas. Se trata de una relación causal, no de una simple correlación: una distinción crítica para lograr mejoras reales.
Interfaz de lenguaje natural con Bedrock
Por último, construí un agente de Bedrock que se conecta a Neptune Analytics y permite a los usuarios hacer preguntas en lenguaje natural:
neptune_endpoint = os.environ.get('NEPTUNE_ANALYTICS_ENDPOINT')
region = os.environ.get('AWS_REGION', 'us-east-1')
neptune_client = boto3.client('neptune-graph', region_name=region)
def execute_query(query, params=None):
"""Execute an openCypher query against Neptune Analytics"""
try:
if params:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER',
parameters=params
)
else:
response = neptune_client.execute_query(
graphIdentifier=neptune_endpoint,
queryString=query,
language='OPEN_CYPHER'
)
# Parse the response
payload = json.loads(response['payload'].read().decode('utf-8'))
return payload
except Exception as e:
logger.error(f"Error executing query: {e}")
return {"error": str(e)}
def lambda_handler(event, context):
try:
action = event['actionGroup']
api_path = event['apiPath']
logger.info(f"Processing action: {action}, API path: {api_path}")
if api_path == '/getRatingStatistics':
body = get_rating_statistics()
elif api_path == '/getResolutionImpact':
body = get_resolution_impact()
elif api_path == '/getUnderstandingImpact':
body = get_understanding_impact()
elif api_path == '/getCombinedFactors':
body = get_combined_factors()
elif api_path == '/getPlatformComparison':
body = get_platform_comparison()
elif api_path == '/getAnomalies':
parameters = event.get('parameters', [])
body = get_anomalies(parameters)
elif api_path == '/runCustomQuery':
parameters = event.get('parameters', [])
body = run_custom_query(parameters)
else:
logger.warning(f"Invalid API path: {api_path}")
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': response_body
}
response = {'response': action_response}
logger.info("Lambda execution completed successfully")
return response
Esta interfaz pone insights causales complejos al alcance de usuarios no técnicos. Un médico podría preguntar: "¿Qué tratamiento reduce con mayor eficacia las tasas de readmisión?", o un educador: "¿Qué método de enseñanza tiene el mayor efecto sobre los resultados de los exámenes?".
Flujo de datos y arquitectura del sistema
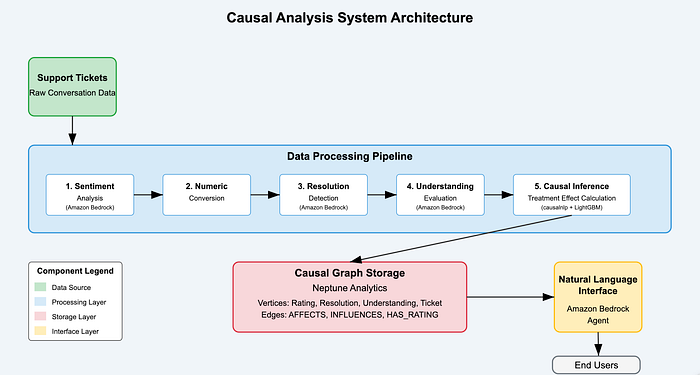
Diagrama de arquitectura de la solución
![Diagrama de arquitectura del sistema — Inserta el diagrama que muestra la arquitectura completa con el flujo de datos entre componentes]
El diagrama anterior ilustra el flujo de datos de extremo a extremo a través de nuestro sistema de análisis causal:
- Los datos crudos de los tickets entran al pipeline.
- La IA generativa extrae características del texto no estructurado.
- La inferencia causal calcula la magnitud de los efectos.
- Neptune Analytics almacena la estructura del grafo.
- El agente de Bedrock entrega acceso a los insights en lenguaje natural.
Esta arquitectura conecta todos los componentes en un pipeline fluido que va desde los datos crudos hasta los insights accionables.
La arquitectura: integración de extremo a extremo
La arquitectura completa de este sistema de análisis causal conecta varios componentes potentes:
- Procesamiento de datos con IA generativa: el modelo Nova Lite de Amazon Bedrock convierte el texto no estructurado de las conversaciones en características estructuradas que alimentan el modelo causal.
- Procesamiento de inferencia causal: librerías como
causalnlpcon un learner como LightGBM analizan las relaciones entre características y resultados para cuantificar los impactos causales. - Almacenamiento basado en grafos: Neptune Analytics almacena los datos complejos e interconectados —tickets, características y relaciones causales calculadas— y permite explorarlos de forma eficiente.
- Interfaz de lenguaje natural: un agente de Bedrock consulta el grafo de Neptune Analytics con openCypher y entrega insights basados en datos a los usuarios en lenguaje natural.
Esta arquitectura conforma un pipeline completo desde los datos crudos hasta los insights accionables, en el que la IA generativa cumple un rol crítico al transformar datos conversacionales complejos en información estructurada y analizable.
Los resultados: insights causales detallados
En nuestro ejemplo de satisfacción del cliente, el sistema reveló insights cuantitativos precisos:
- La resolución es el principal motor: resolver los problemas del cliente provoca un aumento de 42.9 puntos porcentuales en las calificaciones positivas.
- Los problemas resueltos reciben una calificación promedio de 83% positiva.
- Los problemas no resueltos reciben una calificación promedio de 41% positiva.
- La comprensión amplifica el efecto: que el agente comprenda al cliente aporta un impulso significativo.
- Cuando los agentes comprenden: 67% de calificaciones positivas.
- Cuando los agentes no comprenden: 38% de calificaciones positivas.
- Los efectos combinados muestran el camino óptimo:
- Comprendido + Resuelto: 91% de calificaciones positivas.
- Comprendido + No resuelto: 52% de calificaciones positivas.
- No comprendido + Resuelto: 61% de calificaciones positivas.
- No comprendido + No resuelto: 29% de calificaciones positivas.
Estos desgloses marcan una dirección clara: priorizar la resolución del problema y, al mismo tiempo, asegurar que los agentes demuestren comprensión crea las condiciones óptimas para la satisfacción del cliente.
Pero estos insights de satisfacción del cliente son solo un ejemplo. El mismo enfoque podría revelar:
- En salud: qué intervención reduce con mayor eficacia las readmisiones hospitalarias.
- En educación: qué método de enseñanza tiene el efecto causal más fuerte sobre los resultados de los estudiantes.
- En e-commerce: qué recomendaciones de producto realmente provocan un aumento de las compras.
- En manufactura: qué cambios en los procesos mejoran realmente las métricas de calidad.
- En RR. HH.: qué políticas laborales impactan causalmente la retención de empleados.
La implementación técnica
Este enfoque solo requiere unos pocos componentes esenciales:
- Extracción de datos con IA generativa: usa modelos como Claude o GPT para estructurar datos no estructurados.
- Modelado de inferencia causal: aplica técnicas estadísticas para identificar relaciones causales.
- Base de datos de grafos para las relaciones: almacena y consulta el modelo causal en una base de datos de grafos.
- Interfaz de lenguaje natural: pon los insights al alcance de todos a través de IA conversacional.
# Infrastructure as code with AWS CDK
class NeptuneAnalyticsStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create a Neptune Analytics Graph
graph = neptunegraph.CfnGraph(
self, "NeptuneAnalyticsGraph",
graph_name="causal-analysis-graph",
provisioned_memory=16,
replica_count=0,
vector_search_configuration=neptunegraph.CfnGraph.VectorSearchConfigurationProperty(
vector_search_dimension=1024
),
public_connectivity=True,
)
# Create Bedrock agent for Neptune Analytics
bedrock_agent = BedrockAgentConstruct(
self, "BedrockAgent",
neptune_analytics_endpoint=graph.attr_graph_id
)
Ejemplos de consultas en OpenCypher
El poder de Neptune Analytics radica en su capacidad para consultar relaciones causales complejas usando OpenCypher. Estos son algunos ejemplos que muestran sus capacidades:
// Calculate average rating by resolution status
MATCH (res:resolution)-[r:AFFECTS]->(rating:rating)
RETURN res.resolution_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
{
"results": [\
{\
"res.resolution_status": "resolved",\
"avg_rating": 0.4444444444444446,\
"count": 72\
},\
{\
"res.resolution_status": "unresolved",\
"avg_rating": 0.1875,\
"count": 128\
}\
]
}
// Find the combined effect of resolution and understanding
MATCH (res:resolution)-[:AFFECTS]->(rating:rating),
(u:understanding)-[:INFLUENCES]->(rating)
RETURN res.resolution_status,
u.understanding_status,
avg(rating.rating_numeric) AS avg_rating,
count(*) AS count
ORDER BY avg_rating DESC
{
"results": [\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.6000000000000001,\
"count": 5\
},\
{\
"res.resolution_status": "resolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.43283582089552214,\
"count": 67\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "misunderstood",\
"avg_rating": 0.26666666666666666,\
"count": 45\
},\
{\
"res.resolution_status": "unresolved",\
"u.understanding_status": "understood",\
"avg_rating": 0.14457831325301204,\
"count": 83\
}\
]
}
Estas consultas nos permiten explorar las relaciones causales del grafo y obtener insights accionables.
Aplicaciones de negocio: más allá de los insights técnicos
El poder de este enfoque no está solo en la implementación técnica, sino en cómo los insights pueden transformar las prácticas de negocio:
- Capacitación y coaching de agentes: al cuantificar exactamente cuánto impactan la resolución y la comprensión en la satisfacción, las organizaciones pueden diseñar programas de capacitación enfocados en las habilidades de mayor impacto.
- Mejora de procesos: comprender los factores causales que impulsan los resultados permite a las organizaciones rediseñar procesos para obtener resultados óptimos, en vez de hacer cambios basados en correlaciones.
- Insights democratizados: al ofrecer una interfaz de lenguaje natural para los insights causales, este enfoque pone la toma de decisiones basada en datos directamente en manos del personal de primera línea y de los gerentes.
- Detección de anomalías: el sistema identifica casos en los que factores como el sentimiento no coinciden con las calificaciones, lo que abre oportunidades de investigación y aprendizaje.
Por qué esto importa en cualquier industria
La combinación de análisis causal e IA generativa puede transformar la toma de decisiones en prácticamente cualquier campo:
- Ir más allá de la correlación: comprende qué provoca realmente los resultados que buscas.
- Cuantificar el impacto: descubre exactamente cuánto aporta cada factor.
- Priorizar las intervenciones: enfoca los recursos donde tendrán el mayor efecto causal.
- Hacer accesibles los insights: permite que las áreas no técnicas hagan preguntas causales.
Conclusión: apenas el comienzo
Este ejemplo de satisfacción del cliente muestra el potencial de combinar análisis causal con IA generativa, pero apenas roza la superficie de lo posible. A medida que estas tecnologías se vuelvan más accesibles, las organizaciones que aprovechen la comprensión causal obtendrán ventajas significativas en la toma de decisiones.
Te invito a pensar en qué área el análisis causal podría transformar tu propio campo. ¿Qué relaciones has observado pero no estás seguro de si son causales? ¿Qué resultados intentas mejorar sin tener claro qué palancas accionar? Estas son justamente las preguntas que este enfoque puede ayudar a responder.
¿En qué dominio aplicarías el análisis causal? ¿Qué resultados te gustaría comprender en términos causales? ¡Me encantaría leer tus ideas en los comentarios!
Para conocer más sobre DoiT y cómo podemos ayudarte a alcanzar tus objetivos, visita doit.com/services
Repositorio en GitHub: https://github.com/eduamota/genai-causal-inference