スピードと効率を実現するクラウドMLOps
大学時代に開発した画期的な機械学習アルゴリズムが、試合データとファンの反応を分析してバスケットボールの勝敗を予測する——これがあなたの新しいスタートアップの原点です。最初のうちは開発も難しくありません。データ量が限られているので、クラウドでもノートPCでも、1台の仮想マシンでアルゴリズムは快調に動きます。

手に負えなくなるとき
ところが、スタートアップが軌道に乗り、複数のリーグと契約し、顧客が増えてくると、流入するデータ量は爆発的に膨らみます。当初の身軽さは消え、24時間365日にわたるVM管理、セキュリティ対応、OSパッチの適用といった煩雑さがのしかかります。成長は刺激的ですが、同時に重圧にもなります。日々のモデル学習、性能、デプロイ判断を追いきれなくなり、「どのモデルを本番に出せば顧客に最良のサービスを提供できるのか」という問いに答えるのが難しくなっていきます。
本記事では、こうしたスケーリングの壁を乗り越えるためにGoogle Cloud Platform(GCP)、Amazon Web Services(AWS)、Azureといったクラウドプラットフォームが提供する、機械学習運用(MLOps)サービスを解説します。
サービスの数の多さに圧倒されるかもしれませんが、必要になったタイミングで適切なサービスを導入するための判断基準もあわせて紹介します。
MLOpsの広がり
下の図はMLOpsの主要なステップを示しています(これ以外にも多くありますが、まず取り組むことになるのはこのあたりです)。これらのステップは形を問わず常に存在し、いまは手作業でこなしているかもしれません。難しいのは、どのタイミングでクラウドサービスに任せて自動化・効率化すべきかを見極めることです。
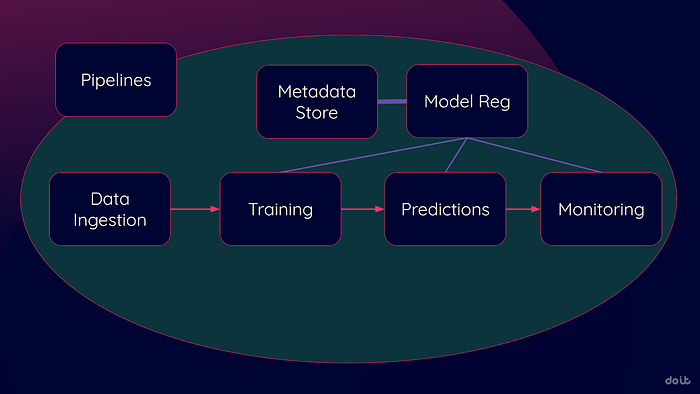
主要なクラウドプロバイダーはいずれも同等のスイートを提供しています:Google Vertex AI、AWS SageMaker、Azure Machine Learningです。細部は違っても、自動化されたMLOpsへ移行するうえで担う役割は共通しています。
基礎
一般的な導入の順序にしたがって、開発、学習、推論の順に見ていきましょう。
開発
はじめのうちは、ノートPCやVM上のJupyter Notebookで十分でしょう。ただしこの方法では、コンピュートリソースに対して常時課金が発生してしまいます。Vertex AI Workbench、SageMaker Studio、AzureML Notebooksといったクラウドベースの開発プラットフォームの方が現実的です。慣れ親しんだJupyterのインターフェースを使いながら、従量課金で作業時間中だけ起動できます。TensorFlowなど主要なツールが組み込まれた環境がそのまま利用でき、コラボレーションも容易になり、セキュリティパッチを含むインフラ保守の負担からも解放されます。
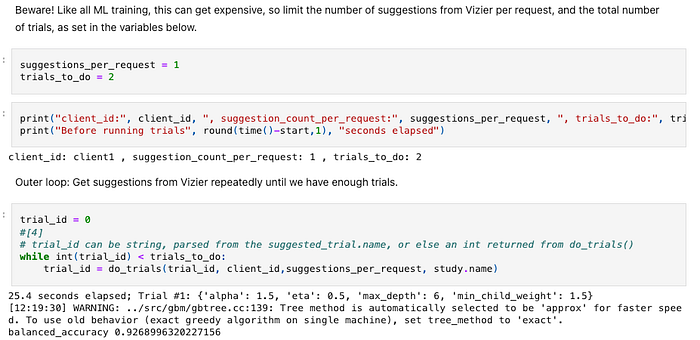
ノートブックの例:関数化されておらず、出力が混じった一直線のコード
ノートブックを使ううえでの2つの注意点
1. クラウドにはノートブックをパイプラインとして実行できるサービスもありますが、これはおすすめしません。ノートブックはあくまで対話的な開発のためのもので、本番実行用ではないからです。順次的で構造化されていないコードは保守しにくく、コードの間に出力(たとえば上の例でbalanced_accuracyが0.9268996320227156と表示されているような出力)が混在するためバージョン管理にも支障が出ます。ノートブックは開発用、実行はパイプラインに任せましょう。
2. 学習のように計算負荷の高い処理では、ノートブックのリソースに頼らずクラウドサービスを使ってください。そうすれば、勤務時間中ずっとアイドル状態のCPU・GPU・メモリに支払い続けることを避けられます。重い処理はクラウドに任せるのが得策です。
学習
学習は多くの場合、リソースを大量に消費します。クラウドの学習サービスは、その負荷をスケーラブルなクラウドリソースにオフロードするためのAPIを提供します。サービス側がコンピュートリソースをスケールアップし、実際の学習中に消費したリソース(GPU、CPU、メモリ)分だけ課金されます。APIにDockerコンテナを渡せば、独自のアルゴリズムを実行できます。標準的なアルゴリズムを使う場合は、コンテナを用意する必要すらなく、どのアルゴリズムを使うかをサービスに伝えるだけです。
推論(予測)
推論とは、モデルを本来の用途で使うこと、たとえば試合結果を予測することです。最初は自前のWebサーバーでも事足りるかもしれませんが、ファンが増えてきたらクラウドの推論エンドポイントへの移行を検討しましょう。これらのサービスは自動スケーリング、セキュリティ、モニタリング、性能トラッキングを備えています。
推論サービスには、シンプルな自作エンドポイントにはない2つのバリエーションがあります。1件のクエリに素早く応答したい場合は、オンデマンドエンドポイントが最も低レイテンシです。一方、何千件ものクエリをまとめて処理する場合は、バッチエンドポイントの方が秒あたりのスループットに優れます。ただし、個々の応答が返るまでの時間は長くなります。
基礎の先へ:MLOpsをスケールさせる
開発、学習、推論はコアですが、複雑さに対処するにはさらにMLOpsサービスが必要になります。クラウドのMLスイートはそれを助けるソリューションを揃えています。各サービスはRESTインターフェースやライブラリを通じて単独でも使えますが、複数を組み合わせれば、最初から統合された状態で扱えるので運用が一段と楽になります。
メタデータ
1日に新しいモデルを1つ学習させ、加えていくつか実験的なバリアントを試すだけで、モデル数はあっという間に数百に達します。スプレッドシートで管理しきれなくなったら、モデルレジストリとメタデータストアの出番です。
モデルファイルはオブジェクトストレージ(Amazon S3、Google Cloud Storage、Azure Blob Store)に置き、レジストリで作成日などの重要なメタデータと一緒に追跡します。
さらにメタデータストアは、アーティファクトの系譜(リネージ)を結びつけてくれます。たとえば次のような情報を追跡できます:
- モデルの背景にあるデータ:そのモデルの学習データには、選手権の準々決勝のデータが含まれていたか?
- 学習時のハイパーパラメータ:どの組み合わせが最良の結果を出したか?
- コード:独自アルゴリズムを動かしたコードは、どのgitコミットに対応するのか?
- エンドポイント:バスケットボール準々決勝の前日、顧客に推論を返していたのはどのバージョンのモデルか?
モニタリング
学習中・推論中に組み込まれたモニタリングを使えば、性能をリアルタイムで把握できます。これにより、モデルの自動選択やカナリアデプロイが可能になり、滑らかな切り替えと性能最適化を実現できます。
デプロイ後の継続的なモニタリングは、性能の劣化を検知します。たとえば、偏ったデータで学習されていた場合や、現実のデータが変化(新しいチームがトップリーグに昇格するなど)するにつれて結果がドリフトする場合があります。モニタリングがあれば、必要に応じて新たに学習したモデルへ自動的に切り替えられます。
パイプライン
初期段階のスタートアップでは、機械学習のワークフロー——コーディング、学習、デプロイ、モデルのバージョン管理、性能モニタリング——を手作業で回していることがよくあります。しかしプロジェクトが拡大すれば、すぐに立ち行かなくなります。そこで欠かせないのが再現性のあるプロセスであり、Google Vertex AI、AWS SageMaker、Azure Machine LearningといったクラウドベースのMLパイプラインサービスがその答えになります。これらは単なる順次スクリプトではなく、複雑な依存関係と並列処理を管理します。たとえば、データを学習・テスト・検証セットに自動で分割し、学習と検証を並列で実行できます。デプロイは条件付きで、検証に成功したモデルだけがカナリアエンドポイントへデプロイされ、ML指標が良好であれば本番展開されます。
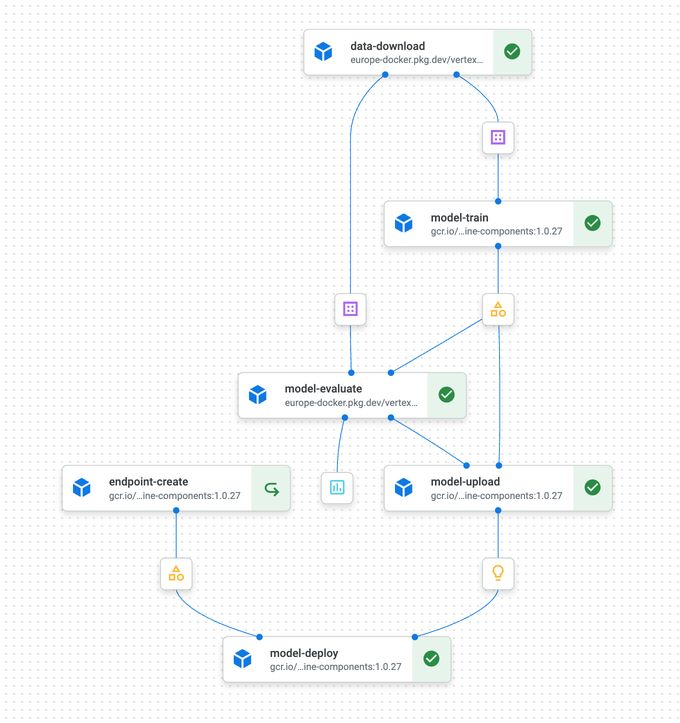
パイプラインフローの例
パイプラインはすべての処理をログ化・モニタリングすることで、堅牢性を高めます。エラーが起きた場合は自動でリトライしたり、よりシンプルな機能にフォールバックしたり、実行を停止したりできます。さらに、設定可能なバッファリング機構により、コンポーネントがデータ流入に追いつかなくなる状況——いわゆるバックプレッシャー——も緩和します。
導入のタイミング
ここで紹介したのはクラウドMLスイートが提供するサービスのほんの一部で、ほかにも数十のサービスがあります。基本的にはこれらの導入をおすすめします。それぞれに、何千ものML開発者のニーズを熟知した専任のプロダクトチームと、安定稼働を支える強固な運用チームが付いています。すでにあるサービスを使う方が、ゼロから自前で構築するよりはるかに簡単です。
とはいえ、現実的にはすべてを一気に導入することはできません。いま抱えているシステムだけで手一杯だからです。
ポイントは、カスタム実装の「タールピット(底なし沼)」にはまる直前に、サービスへ切り替えることです。同等の仕組みを自前で作ろうと多大な労力を注ぎ込みかけた、まさにその直前でMLOpsサービスを取り入れる。これによって堅牢で機能豊富なインフラが手に入り、既製の機能を作り直し続ける終わりなきループを断ち切れます。
いくつかのシナリオを考えてみましょう:
- 現状、開発はJupyter Notebookから学習と検証を起動する形だとします。データサイエンティストを2人追加するなら、コラボレーションと共通のワークフローが必要になります。カスタムスクリプトを使ったGitベースの仕組みを検討したくなるかもしれません——が、ストップ。最初はうまくいっても、すぐに手に負えなくなります。代わりに、ノートブック・学習・推論サービスの統合機能を活用して、堅牢な分散システムを組み立てましょう。
- 同様に、当初はGoogle Sheetでモデルを管理しても問題ないかもしれません。しかし、モデルとデータセットの紐付けに苦労し始め、Google Sheets APIにまで手を出すようになったら潮時です。手に負えなくなる前に、モデルレジストリとメタデータリポジトリを導入しましょう。
- 推論エンドポイントを仮想マシン(VM)にデプロイするのも、最初は簡単です。しかしバスケットボールリーグのリズムに合わせて日々のトラフィックは変動し、マシンを増やしたくなります。これを自前で自動化しようとすると、専用の推論サービスにすでに備わっている自動スケーリング、MLモニタリング、複数バージョン管理といった機能を、わざわざ作り直す羽目になりかねません。
MLにMLOpsは欠かせない
あなたは自分の専門領域——この場合はバスケットボールの試合結果予測——では世界一です。しかし、MLライフサイクルを支えるシステムを組み上げることは、あなたの強みではありません。「自分はいまMLOpsシステムを作ろうとしているな」と気づいた瞬間に、クラウドに目を向けて、ふさわしいサービスを取り入れてください。
ご相談ください
本記事は、急成長中のML企業との数多くの会話をもとにしています。MLに関する課題について、ぜひ私や同僚にお聞かせください:doit.com/services