MLOps en la nube para ganar velocidad y eficiencia
Un algoritmo revolucionario de machine learning, desarrollado durante tus años en la universidad, predice los ganadores de partidos de básquetbol analizando datos del juego y el sentimiento de los fanáticos. Ese avance se convierte en la base de tu nueva startup. Al inicio, el desarrollo es manejable: el algoritmo corre sin problema en una sola máquina virtual, ya sea en la nube o en tu laptop, gracias a que los datos son acotados.

Se sale de control
Sin embargo, conforme tu startup gana tracción, firma con varias ligas y suma una base creciente de clientes, el flujo de datos se dispara. La simplicidad inicial cede paso a la complejidad de gestionar varias VMs las 24 horas, lidiar con la seguridad y aplicar parches al sistema operativo. El crecimiento, aunque emocionante, se vuelve abrumador. Llevar el control del entrenamiento diario de modelos, su rendimiento y las decisiones de despliegue se vuelve un reto enorme. ¿Qué modelo deberías desplegar para ofrecer el mejor servicio al cliente?
Voy a describir los distintos servicios de Machine Learning Operations (MLOps) que ofrecen plataformas como Google Cloud Platform (GCP), Amazon Web Services (AWS) y Azure, pensados para resolver estos retos de escala.
Aunque la cantidad de servicios puede intimidar, te explicaré cómo decidir cuándo adoptar uno nuevo, justo en el momento en que lo necesites.
El alcance de MLOps
El siguiente diagrama muestra los pasos clave de MLOps (existen muchos más, pero estos son de los primeros que vas a adoptar). Estos pasos siempre están ahí; quizá los estés ejecutando manualmente. El reto es identificar cuándo los servicios en la nube pueden automatizarlos y agilizarlos.
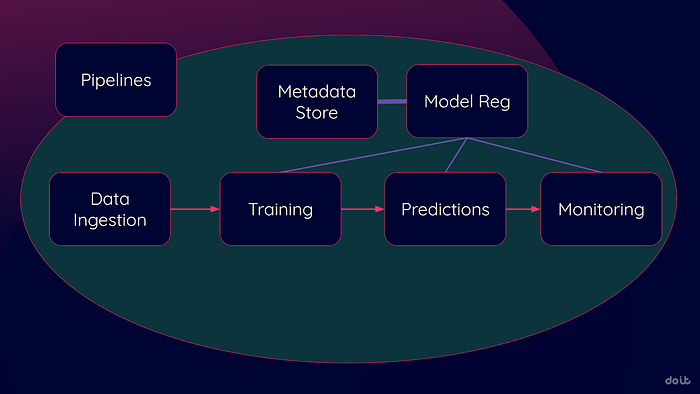
Los principales proveedores de nube ofrecen suites comparables: Google Vertex AI, AWS SageMaker y Azure Machine Learning. Aunque los detalles varían, los servicios cumplen un rol similar en tu transición hacia un MLOps automatizado.
Lo básico
Veamos los pasos en el orden típico de adopción, empezando por desarrollo, entrenamiento y predicción.
Desarrollo
Al inicio, los Jupyter Notebooks en tu laptop o en una VM probablemente alcancen. Eso sí, implica pagar de forma constante por recursos de cómputo. Las plataformas de desarrollo en la nube como Vertex AI Workbench, SageMaker Studio o AzureML Notebooks son una mejor alternativa. Brindan la conocida interfaz de Jupyter, pero con un esquema de pago por uso, y se activan solo durante tus horas de trabajo. Incluyen entornos preconfigurados con las herramientas esenciales (por ejemplo, TensorFlow), lo que facilita la colaboración y elimina la carga del mantenimiento de la infraestructura, parches de seguridad incluidos.
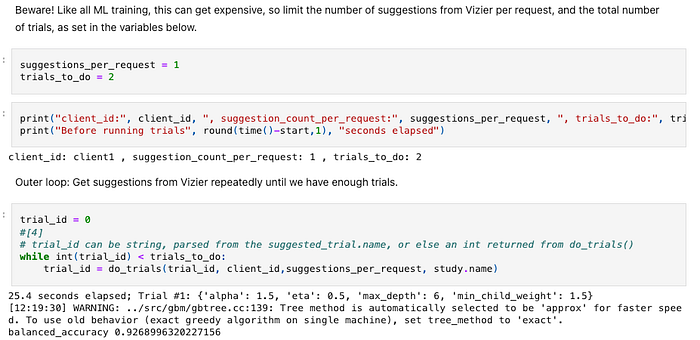
Notebook de ejemplo: sin funciones, sino código lineal mezclado con resultados
Dos advertencias sobre los Notebooks
1. Aunque las nubes ofrecen servicios que ejecutan notebooks como pipelines, no lo hagas: los notebooks son para desarrollo interactivo, no para tiempo de ejecución. Su código secuencial, muchas veces poco estructurado, es difícil de mantener, y los resultados intercalados con el código (por ejemplo, la métrica balanced_accuracy de 0.9268996320227156 de arriba) dificultan el control de versiones. Usa los notebooks para desarrollar, pero usa pipelines para ejecutar.
2. Para tareas que demandan mucho cómputo como el entrenamiento, apóyate en los servicios en la nube en vez de los recursos del notebook. Así evitas pagar por CPU, GPU y memoria inactivas durante toda la jornada. Deja que la nube haga el trabajo pesado.
Entrenamiento
El entrenamiento suele consumir muchos recursos. Los servicios de entrenamiento en la nube ofrecen una API para delegarlo a recursos escalables en la nube. El servicio escala los recursos de cómputo y solo pagas por los que se consumen (GPU, CPU, memoria) durante la ejecución real del entrenamiento. Le pasas un contenedor Docker a la API y el servicio ejecuta tu algoritmo personalizado. Otra opción: si usas algoritmos estándar, ni siquiera necesitas crear el contenedor; basta con indicarle al servicio qué algoritmo usar.
Predicción (inferencia)
La predicción es el uso de tu modelo para su propósito: por ejemplo, predecir resultados de partidos. Un servidor web autohospedado puede alcanzar al inicio, pero a medida que ganas nuevos fanáticos, conviene migrar a un endpoint de predicción en la nube. Estos servicios ofrecen escalado automático, seguridad, monitoreo y seguimiento del rendimiento.
Los servicios de predicción ofrecen dos variantes que un endpoint casero quizá no tenga: cuando quieres una respuesta rápida sobre una sola consulta, un endpoint bajo demanda da la menor latencia. Pero cuando tienes miles de consultas que correr, un endpoint por lotes ofrece mayor rendimiento en consultas por segundo, aunque cualquier respuesta puntual tarde más.
Más allá de lo básico: escalar MLOps
Desarrollo, entrenamiento y predicción son la base; sin embargo, gestionar la complejidad requiere servicios adicionales de MLOps. Las suites de ML en la nube ofrecen soluciones para simplificar la tarea. Puedes usar cada uno de manera independiente a través de interfaces REST y librerías de software, pero si decides combinar varios servicios, obtienes una integración nativa que los hace más fáciles de usar.
Metadatos
Quizá entrenes un modelo nuevo cada día, más algunas variantes experimentales, y eso rápidamente suma cientos. Listarlos en una hoja de cálculo se queda corto. Los registros de modelos y los almacenes de metadatos resuelven el problema.
Guarda los archivos del modelo en almacenamiento de objetos (Amazon S3, Google Cloud Storage, Azure Blob Store) y usa el registro para llevarles seguimiento, junto con metadatos cruciales como la fecha de creación.
Más allá de eso, los almacenes de metadatos pueden enlazar el linaje de los artefactos. Puedes hacer seguimiento de:
- Los datos detrás del modelo: ¿el conjunto de entrenamiento de un modelo determinado incluyó los datos de los cuartos de final del campeonato?
- Los hiperparámetros del entrenamiento: ¿cuáles producen los mejores resultados?
- El código: ¿qué commit exacto de git contiene el código que ejecutó tu algoritmo personalizado?
- Los endpoints: ¿qué versión del modelo estaba sirviendo predicciones al cliente el día anterior a los cuartos de final de básquetbol?
Monitoreo
El monitoreo integrado durante el entrenamiento y la predicción te permite seguir el rendimiento en tiempo real; habilita la selección automática de modelos y los despliegues canary, y así se logran transiciones fluidas y se optimiza el rendimiento.
El monitoreo continuo después del despliegue detecta caídas de rendimiento. Por ejemplo, el modelo puede haberse construido con datos sesgados, o los resultados pueden derivar a medida que cambian los datos del mundo real: digamos que un nuevo equipo asciende a la liga principal. El monitoreo te permite cambiar automáticamente a un modelo recién entrenado cuando sea necesario.
Pipelines
Las startups en etapa temprana suelen gestionar los flujos de machine learning de forma manual: programar, entrenar, desplegar, versionar modelos y monitorear el rendimiento. Esto se vuelve insostenible cuando el proyecto escala. Contar con un proceso repetible es clave, y los servicios de pipelines de ML en la nube como Google Vertex AI, AWS SageMaker y Azure Machine Learning ofrecen la solución. No son simples scripts secuenciales; gestionan dependencias complejas y paralelización. Por ejemplo, pueden dividir automáticamente los datos en conjuntos de entrenamiento, prueba y validación, y luego ejecutar el entrenamiento y la validación en paralelo. El despliegue es condicional: los modelos se despliegan a un endpoint canary solo tras una validación exitosa y se liberan por completo en función de métricas de ML positivas.
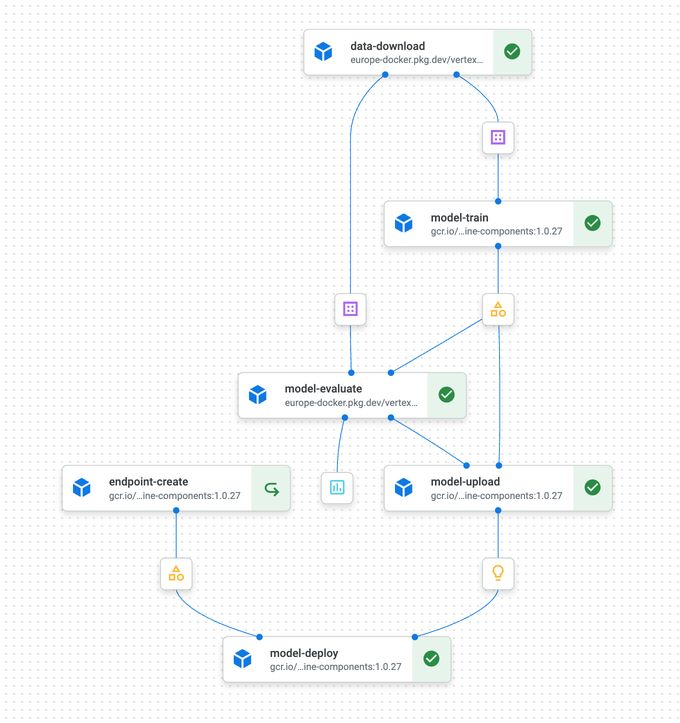
Ejemplo de flujo de pipeline
Los pipelines aportan robustez al registrar y monitorear todas las actividades. Ante errores, pueden reintentar automáticamente, replegarse a una funcionalidad más simple o terminar la ejecución. Además, mitigan la contrapresión —cuando un componente del pipeline se ve saturado por el flujo de datos entrante— mediante mecanismos de buffering configurables.
Cuándo adoptarlos
Esos son apenas algunos de los servicios que ofrecen las suites de ML en la nube; hay decenas más. Te aconsejo que los adoptes. Cada uno cuenta con un equipo de producto dedicado y atento a las necesidades de miles de desarrolladores de ML, y con un equipo de operaciones sólido que asegura un uptime constante. Adoptar un servicio existente es muchísimo más simple que construir el tuyo desde cero.
Pero, siendo realistas, no puedes adoptarlos todos a la vez: estás demasiado ocupado con los sistemas que ya tienes hoy.
La clave es migrar a un servicio justo antes de caer en el "pantano" de las soluciones a medida. Integra un servicio de MLOps justo antes de invertir un esfuerzo significativo en un equivalente casero. Así obtienes una infraestructura sólida y rica en funcionalidades, y te evitas un ciclo interminable de recrear funciones que ya existen.
Considera algunos escenarios:
- Hoy tu desarrollo se basa en entrenamiento y validación disparados desde un Jupyter Notebook. Sumar dos data scientists exige colaboración y flujos de trabajo compartidos. Podrías plantearte una solución basada en Git con scripts personalizados. ¡Detente! Aunque ese enfoque alcance al inicio, rápidamente se vuelve inmanejable. En su lugar, apóyate en los servicios integrados de notebooks, entrenamiento y predicción para construir un sistema robusto y distribuido.
- Del mismo modo, llevar el seguimiento de modelos en una Google Sheet puede alcanzar al inicio. Pero cuando empieces a lidiar con vincular modelos a datasets y termines recurriendo a las APIs de Google Sheets, es momento de cambiar. Adopta un registro de modelos y un repositorio de metadatos antes de que la complejidad te abrume.
- De forma parecida, desplegar un endpoint de predicción en una máquina virtual (VM) es sencillo. Sin embargo, el tráfico diario fluctúa con el ritmo de las ligas de básquetbol y vas a sentir la tentación de sumar más máquinas. Si intentas automatizarlo, corres el riesgo de replicar funciones que ya están integradas en un servicio dedicado de predicción, que normalmente incluye autoescalado, monitoreo de ML y gestión multi-versión.
El ML requiere MLOps
Eres el mejor del mundo en tu área de especialización; en este caso, en predecir el resultado de partidos de básquetbol. Pero tu ventaja relativa no está en montar los sistemas que ejecutan tu ciclo de vida de ML. En el momento en que te des cuenta de que estás a punto de desarrollar un sistema de MLOps, mira hacia la nube y adopta el servicio adecuado.
¡Conversemos!
Este artículo nace de muchas conversaciones que he tenido con empresas de ML en rápido crecimiento. Para profundizar, conversa conmigo y con mis colegas sobre tus retos de ML: doit.com/services