MLOps in cloud per velocità ed efficienza
Un algoritmo di machine learning rivoluzionario, sviluppato negli anni dell'università, prevede i vincitori delle partite di basket analizzando i dati di gioco e il sentiment dei tifosi. È questa l'intuizione alla base della Sua nuova startup. All'inizio lo sviluppo è gestibile: con dati ancora limitati, l'algoritmo gira senza problemi su una singola macchina virtuale, in cloud o sul Suo laptop.

La situazione sfugge di mano
Ma quando la startup ingrana, firma accordi con più leghe e conquista una base clienti in costante crescita, l'afflusso di dati esplode. Alla semplicità iniziale subentra la complessità di gestire più VM 24 ore su 24, 7 giorni su 7, tra problemi di sicurezza e patch dei sistemi operativi. La crescita, per quanto entusiasmante, diventa travolgente. Tenere traccia ogni giorno del training dei modelli, delle prestazioni e delle scelte di deployment si trasforma in una sfida importante. Quale modello mettere in produzione per offrire ai clienti il servizio migliore?
In questo articolo descriverò i numerosi servizi di Machine Learning Operations (MLOps) offerti da piattaforme cloud come Google Cloud Platform (GCP), Amazon Web Services (AWS) e Azure, pensati proprio per affrontare queste sfide di scalabilità.
Per quanto la quantità di servizi disponibili possa scoraggiare, spiegherò come capire quando adottarne uno nuovo, esattamente nel momento in cui serve.
L'ampiezza dell'MLOps
Il diagramma qui sotto illustra le fasi chiave dell'MLOps (ne esistono molte altre, ma queste sono tra le prime che si trovano ad adottare). Sono fasi sempre presenti: probabilmente le sta già eseguendo manualmente. La sfida è capire quando i servizi cloud possono automatizzarle e snellirle.
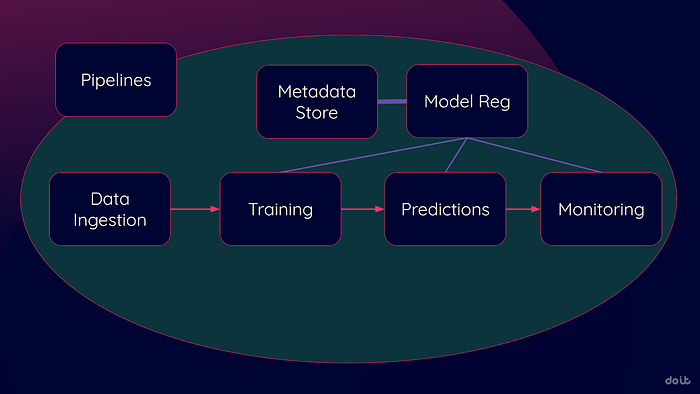
Tutti i principali cloud provider offrono suite analoghe: Google Vertex AI, AWS SageMaker e Azure Machine Learning. I dettagli cambiano, ma il ruolo di questi servizi nella Sua transizione verso un MLOps automatizzato è sostanzialmente lo stesso.
Le basi
Affrontiamo le fasi nel tipico ordine di adozione, partendo da sviluppo, training e prediction.
Sviluppo
All'inizio, i Jupyter Notebook sul Suo laptop o su una VM bastano quasi sempre. Il rovescio della medaglia è che si pagano costantemente le risorse di calcolo. Le piattaforme di sviluppo in cloud come Vertex AI Workbench, SageMaker Studio o AzureML Notebooks rappresentano un'alternativa migliore: offrono la familiare interfaccia Jupyter ma con un modello pay-as-you-go, e si attivano solo durante le ore di lavoro. Includono ambienti preconfigurati con gli strumenti essenziali (ad esempio TensorFlow), semplificano la collaborazione e tolgono di mezzo il peso della manutenzione dell'infrastruttura, patch di sicurezza comprese.
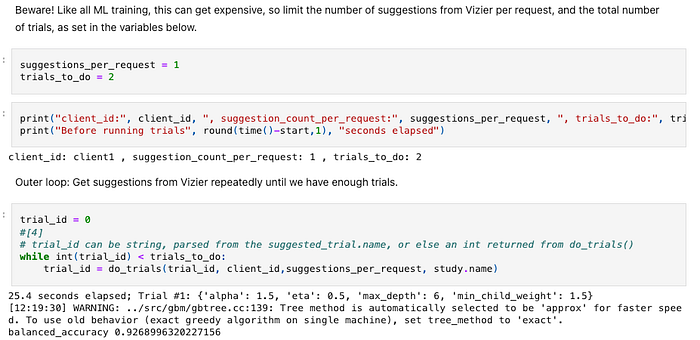
Esempio di Notebook: niente funzioni, ma codice lineare misto agli output
Due avvertenze sui Notebook
1. I cloud offrono servizi che eseguono i notebook come pipeline, ma è meglio non farlo: i Notebook sono pensati per lo sviluppo interattivo, non per l'esecuzione in produzione. Il loro codice sequenziale e spesso poco strutturato è difficile da mantenere, e gli output intervallati al codice (ad esempio la metrica balanced_accuracy di 0.9268996320227156 qui sopra) ostacolano il version tracking. Usi i notebook per lo sviluppo e le pipeline per l'esecuzione.
2. Per attività computazionalmente intensive come il training, sfrutti i servizi cloud anziché le risorse del notebook. Eviterà di pagare per CPU, GPU e memoria inattive per tutta la giornata lavorativa. Lasci che sia il cloud a occuparsi del lavoro pesante.
Training
Il training è spesso oneroso in termini di risorse. I servizi di training in cloud mettono a disposizione un'API per delegare il training a risorse cloud scalabili. Il servizio scala le risorse di calcolo e Lei paga solo per quelle effettivamente consumate (GPU, CPU, memoria) durante l'esecuzione. All'API si passa un container Docker, in modo che il servizio possa eseguire il Suo algoritmo personalizzato. In alternativa, se utilizza algoritmi standard, non occorre nemmeno creare il container: basta indicare al servizio quale algoritmo usare.
Prediction (Inference)
La prediction è l'utilizzo del modello per il suo scopo: nel nostro caso, prevedere il risultato delle partite. Un web server self-hosted può bastare all'inizio, ma con l'arrivo di nuovi tifosi conviene passare a un endpoint di prediction in cloud. Questi servizi offrono scalabilità automatica, sicurezza, monitoring e tracciamento delle prestazioni.
I servizi di prediction propongono due varianti che un endpoint artigianale difficilmente può replicare: quando serve una risposta rapida su una singola query, un endpoint on-demand garantisce la latenza più bassa; quando invece le query da eseguire sono migliaia, un endpoint batch offre un throughput più elevato in termini di query al secondo, anche se ogni singola risposta richiederà più tempo.
Oltre le basi: scalare l'MLOps
Sviluppo, training e prediction costituiscono il nucleo, ma per gestire la complessità servono ulteriori servizi MLOps. Le suite ML in cloud propongono soluzioni che semplificano il lavoro. Può utilizzare ciascun servizio in modo indipendente tramite interfacce REST e librerie software, ma se ne adotta più di uno ottiene un'integrazione nativa che ne rende l'utilizzo molto più semplice.
Metadata
Capita di addestrare un nuovo modello al giorno, più qualche variante sperimentale, e in poco tempo si arriva a centinaia. A quel punto un foglio di calcolo non basta più. La risposta sono i model registry e i metadata store.
Conservi i file dei modelli in object storage (Amazon S3, Google Cloud Storage, Azure Blob Store) e usi il registry per tracciarli, insieme ai metadati fondamentali, come la data di creazione.
Non solo: i metadata store permettono di collegare la lineage degli artefatti. Si possono tracciare:
- I dati alla base del modello: il training set di un determinato modello includeva i dati dei quarti di finale del campionato?
- Gli iperparametri del training: quali generano i risultati migliori?
- Il codice: quale commit git esatto contiene il codice che ha eseguito il Suo algoritmo personalizzato?
- Gli endpoint: quale versione del modello stava servendo le prediction al cliente il giorno prima dei quarti di finale di basket?
Monitoring
Il monitoring integrato durante training e prediction permette di tracciare le prestazioni in tempo reale, abilitando la selezione automatica dei modelli e i deployment canary, per transizioni fluide e prestazioni ottimizzate.
Il monitoring continuo dopo il deployment rileva il degrado delle prestazioni. Il modello, ad esempio, potrebbe essere stato costruito con dati distorti, oppure i risultati possono andare in drift al variare dei dati reali, ad esempio quando una nuova squadra viene promossa nella massima lega. Il monitoring consente di sostituire automaticamente il modello con uno appena addestrato, quando serve.
Pipeline
Nelle prime fasi, le startup gestiscono spesso a mano i workflow di machine learning: scrittura del codice, training, deployment, versionamento dei modelli e monitoraggio delle prestazioni. Un approccio insostenibile man mano che il progetto cresce. Serve un processo ripetibile, e i servizi di pipeline ML in cloud come Google Vertex AI, AWS SageMaker e Azure Machine Learning rappresentano la soluzione. Non sono semplici script sequenziali: gestiscono dipendenze complesse e parallelizzazione. Possono ad esempio suddividere automaticamente i dati in set di training, test e validation, ed eseguire poi training e validation in parallelo. Il deployment è condizionale: i modelli vengono distribuiti su un endpoint canary solo dopo una validation riuscita e rilasciati completamente solo in base a metriche ML positive.
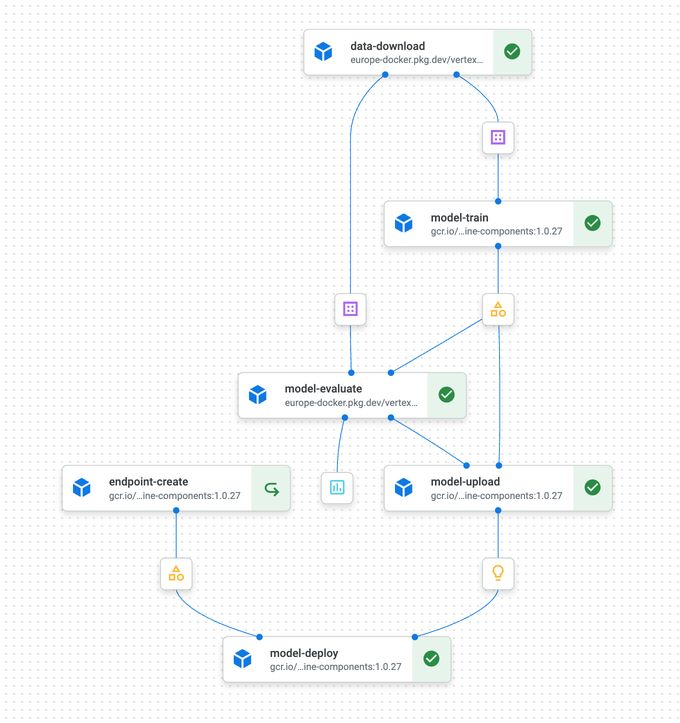
Esempio di flusso di pipeline
Le pipeline aggiungono robustezza loggando e monitorando tutte le attività. In caso di errori, possono effettuare automaticamente un retry, ripiegare su funzionalità più semplici o terminare l'esecuzione. Mitigano inoltre la backpressure, ovvero le situazioni in cui un componente della pipeline viene sovraccaricato dall'afflusso di dati, attraverso meccanismi di buffering configurabili.
Quando adottarli
Questi sono solo alcuni dei servizi offerti dalle suite ML in cloud: ce ne sono decine. Il mio consiglio è di adottarli. Ognuno conta su un team di prodotto dedicato, in sintonia con le esigenze di migliaia di sviluppatori ML, e su un solido team operations che garantisce un uptime costante. Adottare un servizio esistente è molto più semplice che costruirne uno da zero.
Realisticamente, però, non li può adottare tutti in una volta: ha già abbastanza da fare con i sistemi attuali.
La chiave è passare a un servizio esattamente prima di finire impantanato in soluzioni custom. Integri un servizio MLOps subito prima di iniziare a investire risorse importanti in un equivalente fatto in casa. Otterrà un'infrastruttura solida e ricca di funzionalità, evitando il ciclo infinito di reinventare ciò che è già disponibile.
Vediamo qualche scenario:
- Oggi lo sviluppo prevede training e validation lanciati da Jupyter Notebook. Con l'arrivo di due nuovi data scientist servono collaborazione e workflow condivisi. Potrebbe pensare a una soluzione basata su Git con script custom. Si fermi! Per quanto sufficiente all'inizio, questo approccio diventerà rapidamente ingestibile. Sfrutti invece servizi integrati di notebook, training e prediction per costruire un sistema robusto e distribuito.
- Allo stesso modo, tracciare i modelli in un foglio Google può andar bene all'inizio. Ma quando si tratta di collegare i modelli ai dataset e si finisce per ricorrere alle API di Google Sheets, è il momento di cambiare. Adotti un model registry e un repository di metadati prima che la complessità Le sfugga di mano.
- Analogamente, distribuire un endpoint di prediction su una macchina virtuale (VM) è semplice. Ma il traffico giornaliero oscilla al ritmo delle leghe di basket, e la tentazione è quella di aggiungere altre macchine. Se prova ad automatizzare il processo, rischia di replicare funzionalità già native in un servizio di prediction dedicato, che in genere include auto-scaling, monitoring ML e gestione multi-versione.
Il ML richiede l'MLOps
Lei è il numero uno al mondo nella Sua area di specializzazione, in questo caso nel prevedere l'esito delle partite di basket. Ma il Suo vantaggio competitivo non sta nel mettere in piedi i sistemi che gestiscono il ciclo di vita ML. Nel momento in cui si accorge di stare per sviluppare un sistema MLOps, guardi al cloud e adotti il servizio adeguato.
Ci contatti!
Questo articolo nasce dalle numerose conversazioni che ho avuto con aziende ML in rapida crescita. Per saperne di più, venga a parlare con me e i miei colleghi delle Sue sfide ML: doit.com/services