Le MLOps cloud au service de la vitesse et de l'efficacité
Imaginez un algorithme de machine learning révolutionnaire, mis au point pendant vos années universitaires, capable de prédire les vainqueurs de matchs de basket en analysant les données de jeu et le sentiment des fans. Cette percée constitue le socle de votre nouvelle startup. Au début, le développement reste gérable : votre algorithme tourne très bien sur une seule machine virtuelle, dans le cloud ou sur votre ordinateur portable, grâce à un volume de données limité.

La situation devient ingérable
Mais à mesure que votre startup gagne du terrain, signe plusieurs ligues et attire une clientèle grandissante, l'afflux de données explose. La simplicité initiale cède la place à la complexité de gérer plusieurs VM 24h/24 et 7j/7, de jongler avec la sécurité et d'appliquer les correctifs OS. La croissance, aussi grisante soit-elle, devient écrasante. Suivre l'entraînement quotidien des modèles, leurs performances et les décisions de déploiement tourne au véritable casse-tête. Quel modèle déployer pour offrir le meilleur service à vos clients ?
Je vais vous présenter les nombreux services Machine Learning Operations (MLOps) proposés par les plateformes cloud comme Google Cloud Platform (GCP), Amazon Web Services (AWS) et Azure, conçus pour répondre à ces enjeux de mise à l'échelle.
Le nombre de services peut sembler intimidant, mais je vous expliquerai comment choisir le bon moment pour adopter chacun, exactement quand vous en avez besoin.
L'étendue du MLOps
Le schéma ci-dessous illustre les étapes clés du MLOps (il en existe bien d'autres, mais ce sont parmi les premières que vous adopterez). Ces étapes existent toujours — vous les réalisez peut-être manuellement. L'enjeu est d'identifier le moment où les services cloud peuvent les automatiser et les fluidifier.
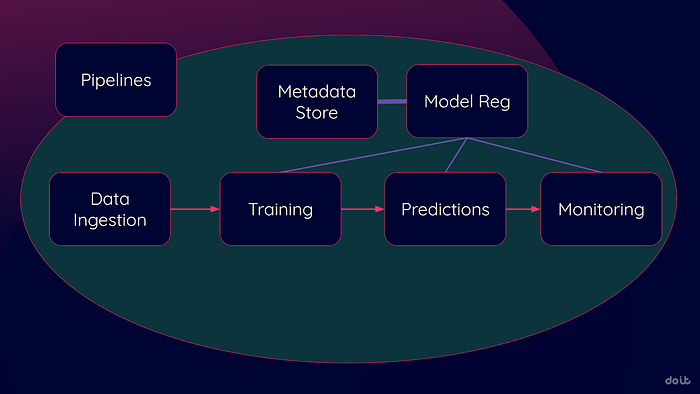
Tous les grands fournisseurs cloud proposent des suites comparables : Google Vertex AI, AWS SageMaker et Azure Machine Learning. Les détails varient, mais ces services jouent un rôle similaire dans votre transition vers un MLOps automatisé.
Les fondamentaux
Abordons les étapes dans l'ordre d'adoption habituel : développement, entraînement et prédiction.
Développement
Au départ, des Jupyter Notebooks sur votre laptop ou une VM suffisent généralement. Mais cela vous oblige à payer en permanence des ressources de calcul. Les plateformes de développement cloud comme Vertex AI Workbench, SageMaker Studio ou AzureML Notebooks offrent une bien meilleure alternative. Elles proposent l'interface Jupyter familière avec une tarification à l'usage, et ne sont activées que durant vos heures de travail. Des environnements préconfigurés avec les outils essentiels (TensorFlow, par exemple) sont inclus, ce qui simplifie la collaboration et vous libère de la maintenance d'infrastructure, correctifs de sécurité compris.
Exemple de Notebook : pas de fonctions, mais du code linéaire entrelacé avec des sorties
Deux mises en garde sur les Notebooks
1. Bien que les clouds proposent des services pour exécuter des notebooks comme des pipelines, évitez-le : les Notebooks sont faits pour le développement interactif, pas pour l'exécution. Leur code séquentiel et souvent peu structuré est difficile à maintenir, et les sorties intercalées avec le code (par exemple la métrique balanced_accuracy de 0.9268996320227156 ci-dessus) compliquent le suivi des versions. Utilisez les notebooks pour développer, et les pipelines pour exécuter.
2. Pour les tâches gourmandes en calcul comme l'entraînement, exploitez les services cloud plutôt que les ressources du notebook. Vous éviterez ainsi de payer pour des CPU, GPU et de la mémoire inutilisés tout au long de la journée. Laissez le cloud faire le gros du travail.
Entraînement
L'entraînement est souvent gourmand en ressources. Les services d'entraînement cloud fournissent une API permettant de déléguer l'entraînement à des ressources cloud scalables. Le service alloue dynamiquement les ressources de calcul, et vous ne payez que celles consommées (GPU, CPU, mémoire) durant l'exécution effective. Vous transmettez un conteneur Docker à l'API, ce qui permet au service d'exécuter votre algorithme personnalisé. Et si vous utilisez des algorithmes standard, inutile même de créer le conteneur : il suffit d'indiquer au service quel algorithme employer.
Prédiction (Inférence)
La prédiction, c'est l'utilisation de votre modèle pour ce à quoi il est destiné : prédire les résultats des matchs, par exemple. Un serveur web auto-hébergé peut suffire au début, mais à mesure que vous gagnez de nouveaux fans, passez à un endpoint de prédiction cloud. Ces services offrent mise à l'échelle automatique, sécurité, monitoring et suivi des performances.
Les services de prédiction proposent deux variantes qu'un endpoint maison n'aura sans doute pas : pour obtenir une réponse rapide à une requête unique, un endpoint à la demande offre la latence la plus faible. Mais pour traiter des milliers de requêtes, un endpoint batch fournit un débit bien plus élevé en requêtes par seconde, même si chaque réponse prend plus de temps.
Au-delà des fondamentaux : passer le MLOps à l'échelle
Développement, entraînement et prédiction forment le socle ; mais gérer la complexité exige des services MLOps supplémentaires. Les suites ML cloud proposent des solutions pour simplifier la tâche. Vous pouvez utiliser chacun indépendamment des autres via des interfaces REST et des bibliothèques logicielles ; mais en combiner plusieurs vous fait bénéficier d'une intégration native qui en facilite l'usage.
Métadonnées
Vous entraînez peut-être un nouveau modèle par jour, plus quelques variantes expérimentales, ce qui atteint vite des centaines. Les lister dans un tableur ne suffit plus. Les registres de modèles et les magasins de métadonnées apportent la solution.
Stockez les fichiers de modèles dans un stockage objet (Amazon S3, Google Cloud Storage, Azure Blob Store) et utilisez le registre pour les suivre, avec les métadonnées essentielles comme la date de création.
Au-delà, les magasins de métadonnées peuvent relier la lignée des artefacts. Vous pouvez suivre :
- Les données derrière le modèle : le jeu d'entraînement d'un modèle donné incluait-il les données des quarts de finale du championnat ?
- Les hyperparamètres d'entraînement : lesquels donnent les meilleurs résultats ?
- Le code : quel commit git exact contient le code qui a exécuté votre algorithme personnalisé ?
- Les endpoints : quelle version du modèle servait les prédictions au client la veille des quarts de finale de basket ?
Monitoring
Le monitoring intégré pendant l'entraînement et la prédiction permet de suivre les performances en temps réel ; il rend possibles la sélection automatique de modèles et les déploiements canary, garantissant des transitions fluides et une optimisation des performances.
Le monitoring continu après déploiement détecte la dégradation des performances. Le modèle peut, par exemple, avoir été construit sur des données biaisées, ou les résultats peuvent dériver à mesure que les données réelles évoluent — disons qu'une nouvelle équipe est promue en première ligue. Le monitoring vous permet de basculer automatiquement vers un modèle nouvellement entraîné, si nécessaire.
Pipelines
Les startups en phase initiale gèrent souvent les workflows de machine learning manuellement : codage, entraînement, déploiement, versioning des modèles et suivi des performances. Cela devient intenable à mesure que le projet grandit. Un processus reproductible est indispensable, et les services de pipelines ML cloud comme Google Vertex AI, AWS SageMaker et Azure Machine Learning apportent la solution. Il ne s'agit pas de simples scripts séquentiels : ils gèrent des dépendances complexes et la parallélisation. Ils peuvent par exemple répartir automatiquement les données en jeux d'entraînement, de test et de validation, puis exécuter l'entraînement et la validation en parallèle. Le déploiement est conditionnel ; les modèles ne sont déployés sur un endpoint canary qu'après validation réussie, puis pleinement déployés sur la base de métriques ML positives.
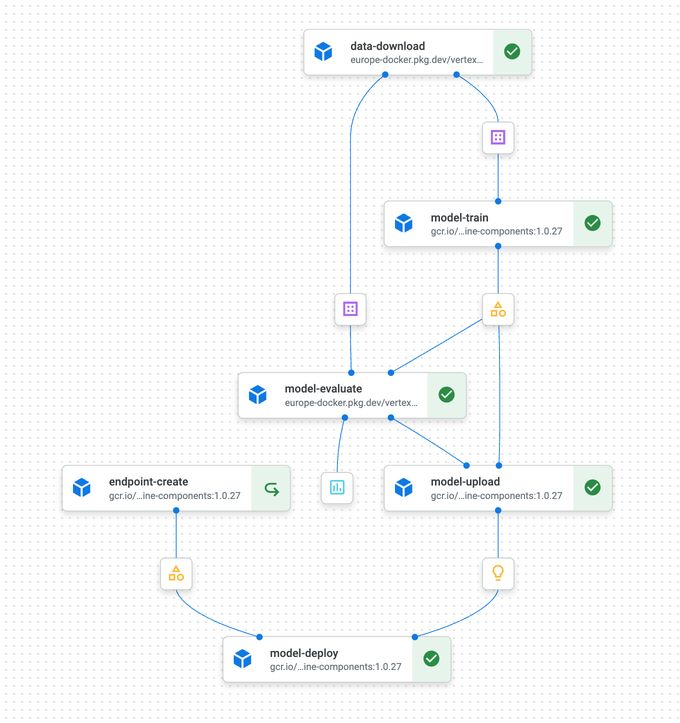
Exemple de flux de pipeline
Les pipelines apportent de la robustesse en journalisant et en surveillant toutes les activités. En cas d'erreur, ils peuvent relancer automatiquement, basculer vers une fonctionnalité simplifiée ou arrêter l'exécution. Ils atténuent aussi la backpressure — ces situations où un composant du pipeline est submergé par l'afflux de données — grâce à des mécanismes de buffering configurables.
Quand adopter ces services
Ce ne sont là que quelques-uns des services proposés par les suites ML cloud ; il en existe des dizaines d'autres. Je vous conseille de les adopter. Chacun bénéficie d'une équipe produit dédiée à l'écoute des besoins de milliers de développeurs ML, et d'une équipe ops solide qui en assure la disponibilité constante. Adopter un service existant est nettement plus simple que de bâtir le sien de zéro.
Mais soyons réalistes : vous ne pouvez pas tous les adopter d'un coup, vous êtes déjà bien occupé avec les systèmes en place.
L'enjeu, c'est de basculer vers un service juste avant de tomber dans le bourbier des solutions sur mesure. Intégrez un service MLOps juste avant de vous lancer dans un effort important sur un équivalent fait maison. Vous obtenez ainsi une infrastructure robuste et riche en fonctionnalités, et vous évitez le cycle sans fin de réinvention de fonctionnalités déjà disponibles.
Quelques scénarios à considérer :
- Votre développement repose aujourd'hui sur l'entraînement et la validation déclenchés depuis un Jupyter Notebook. L'arrivée de deux data scientists impose collaboration et workflows partagés. Vous pourriez songer à une solution basée sur Git avec des scripts personnalisés. Stop ! Cette approche peut suffire au début, mais elle deviendra vite ingérable. Privilégiez plutôt des services intégrés de notebook, d'entraînement et de prédiction pour bâtir un système distribué solide.
- De même, suivre les modèles dans une Google Sheet peut faire l'affaire au début. Mais lorsque vous commencez à devoir relier les modèles aux jeux de données et à vous tourner vers les API Google Sheets, il est temps de changer. Adoptez un registre de modèles et un référentiel de métadonnées avant que la complexité ne devienne ingérable.
- Dans le même ordre d'idées, déployer un endpoint de prédiction sur une machine virtuelle (VM) est simple. Mais le trafic quotidien fluctue au rythme des ligues de basket, ce qui vous pousse à ajouter d'autres machines. En tentant d'automatiser cela, vous risquez de réinventer des fonctionnalités déjà natives d'un service de prédiction dédié, qui inclut généralement l'auto-scaling, le monitoring ML et la gestion multi-versions.
Le ML exige du MLOps
Vous êtes le meilleur au monde dans votre domaine de spécialisation — ici, prédire l'issue des matchs de basket. Mais votre avantage compétitif ne réside pas dans la mise en place des systèmes qui font tourner votre cycle de vie ML. Dès l'instant où vous vous apprêtez à développer un système MLOps, regardez du côté du cloud et adoptez le service adapté.
Parlons-en !
Cet article s'appuie sur de nombreux échanges menés avec des entreprises ML en forte croissance. Pour aller plus loin, venez discuter avec mes collègues et moi de vos défis ML : doit.com/services