MLOps na nuvem para ganhar velocidade e eficiência
Um algoritmo revolucionário de machine learning, criado nos seus tempos de faculdade, prevê os vencedores de jogos de basquete a partir dos dados das partidas e do sentimento da torcida. Esse avanço é a base da sua nova startup. No começo, o desenvolvimento é tranquilo — seu algoritmo roda numa única máquina virtual, seja na nuvem ou no seu laptop, já que o volume de dados ainda é pequeno.

Saindo do controle
Mas, à medida que sua startup ganha tração, fechando contratos com várias ligas e atraindo uma base de clientes cada vez maior, o volume de dados explode. A simplicidade inicial dá lugar à complexidade de gerenciar várias VMs 24 horas por dia, cuidar da segurança e aplicar patches de SO. O crescimento, por mais empolgante que seja, vira um peso. Acompanhar o treinamento diário dos modelos, o desempenho e as decisões de deploy se torna um desafio enorme. Qual modelo colocar em produção para oferecer o melhor atendimento ao cliente?
Vou apresentar os diversos serviços de Machine Learning Operations (MLOps) oferecidos por plataformas de nuvem como Google Cloud Platform (GCP), Amazon Web Services (AWS) e Azure, criados justamente para resolver esses desafios de escala.
O número de serviços pode até assustar, mas vou mostrar como decidir o momento certo de adotar cada um — exatamente quando você precisa.
A amplitude do MLOps
O diagrama abaixo mostra as principais etapas de MLOps (existem muitas outras, mas essas estão entre as primeiras que você vai adotar). Essas etapas sempre existem — você pode até estar executando-as manualmente. O desafio está em identificar quando os serviços de nuvem podem automatizá-las e simplificá-las.
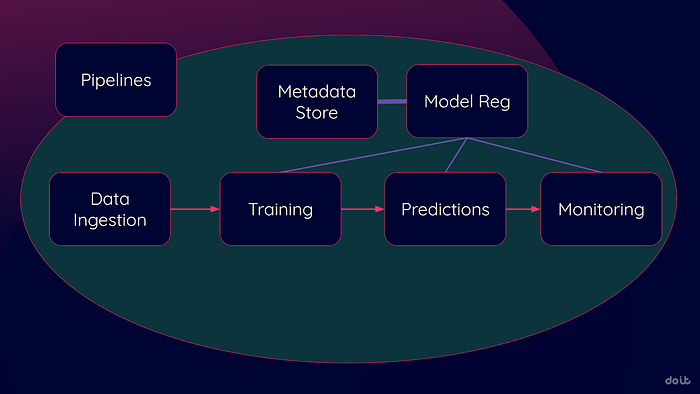
Todos os principais provedores de nuvem oferecem suítes equivalentes: Google Vertex AI, AWS SageMaker e Azure Machine Learning. Os detalhes variam, mas os serviços cumprem um papel parecido na sua transição para um MLOps automatizado.
O básico
Vamos seguir as etapas na ordem típica de adoção, começando por desenvolvimento, treinamento e previsão.
Desenvolvimento
No começo, Jupyter Notebooks rodando no seu laptop ou em uma VM provavelmente dão conta. Só que isso significa pagar por recursos de computação o tempo todo. Plataformas de desenvolvimento na nuvem como Vertex AI Workbench, SageMaker Studio ou AzureML Notebooks são uma alternativa melhor. Elas oferecem a interface familiar do Jupyter, mas com cobrança pay-as-you-go, ativando os recursos só durante o seu horário de trabalho. Já vêm com ambientes pré-configurados e ferramentas essenciais (como o TensorFlow), o que facilita a colaboração e elimina o peso de manter a infraestrutura, incluindo patches de segurança.
Exemplo de Notebook: sem funções, mas com código linear misturado às saídas
Dois cuidados com Notebooks
1. Mesmo que as nuvens tenham serviços que executam notebooks como pipelines, não faça isso: notebooks são para desenvolvimento interativo, não para runtime. O código sequencial e quase sempre desestruturado é difícil de manter, e as saídas intercaladas ao código (por exemplo, a métrica balanced_accuracy de 0,9268996320227156 acima) atrapalham o controle de versão. Use notebooks para desenvolver, mas use pipelines para executar.
2. Para tarefas que exigem muito poder computacional, como treinamento, recorra aos serviços de nuvem em vez dos recursos do notebook. Assim, você não paga por CPU, GPU e memória ociosos durante todo o expediente. Deixe a nuvem fazer o trabalho pesado.
Treinamento
O treinamento costuma consumir muitos recursos. Os serviços de treinamento na nuvem oferecem uma API para delegar essa tarefa a recursos escaláveis. O serviço aumenta a capacidade computacional conforme necessário, e você paga apenas pelos recursos consumidos (GPU, CPU, memória) durante a execução. Você passa um container Docker para a API e o serviço executa o seu algoritmo customizado. Se estiver usando algoritmos padrão, nem precisa criar o container: basta indicar ao serviço qual algoritmo usar.
Previsão (Inferência)
A previsão é o uso do modelo para o seu propósito final: prever resultados de jogos, por exemplo. Um servidor web auto-hospedado pode dar conta no início, mas, conforme você ganha novos fãs, vale migrar para um endpoint de previsão na nuvem. Esses serviços oferecem escalabilidade automática, segurança, monitoramento e acompanhamento de desempenho.
Os serviços de previsão têm duas variantes que um endpoint caseiro dificilmente entrega: quando você quer uma resposta rápida para uma única consulta, um endpoint sob demanda oferece a menor latência. Já quando há milhares de consultas para rodar, um endpoint em batch alcança maior throughput de consultas por segundo, ainda que cada resposta individual demore mais.
Indo além do básico: escalando MLOps
Desenvolvimento, treinamento e previsão formam o núcleo, mas administrar a complexidade exige serviços adicionais de MLOps. As suítes de ML na nuvem trazem soluções que simplificam essa tarefa. Você pode usar cada um deles de forma independente, via interfaces REST e bibliotecas de software; mas, ao combinar vários serviços, ganha integração nativa que facilita ainda mais o uso.
Metadados
Você pode treinar um novo modelo por dia, somar algumas variações experimentais, e isso vira centenas rapidinho. Listar tudo numa planilha deixa de ser viável. Registries de modelos e repositórios de metadados resolvem esse problema.
Armazene os arquivos dos modelos em object storage (Amazon S3, Google Cloud Storage, Azure Blob Store) e use o registry para rastreá-los, junto com metadados essenciais — como a data de criação.
Além disso, repositórios de metadados conseguem conectar a linhagem dos artefatos. Você pode rastrear:
- Os dados por trás do modelo: o conjunto de treinamento de um determinado modelo incluiu os dados das quartas de final do campeonato?
- Os hiperparâmetros do treinamento: quais geram os melhores resultados?
- Código: qual é exatamente o commit do git que contém o código que rodou seu algoritmo customizado?
- Endpoints: qual versão do modelo estava servindo previsões ao cliente no dia anterior à quarta de final do basquete?
Monitoramento
O monitoramento integrado durante o treinamento e a previsão permite acompanhar o desempenho em tempo real; ele viabiliza a seleção automatizada de modelos e deployments canário, garantindo transições suaves e otimização de desempenho.
O monitoramento contínuo após o deploy detecta queda de desempenho. Por exemplo, o modelo pode ter sido construído com dados enviesados, ou os resultados podem sofrer drift conforme os dados do mundo real mudam — digamos, um novo time é promovido para a primeira divisão. O monitoramento permite trocar automaticamente por um modelo recém-treinado quando necessário.
Pipelines
Startups em estágio inicial costumam administrar fluxos de machine learning na mão: codificando, treinando, fazendo deploy, versionando modelos e monitorando o desempenho. Isso fica insustentável conforme o projeto cresce. Um processo replicável é fundamental, e serviços de pipeline de ML na nuvem como Google Vertex AI, AWS SageMaker e Azure Machine Learning resolvem esse problema. Eles não são scripts sequenciais simples; gerenciam dependências complexas e paralelização. Por exemplo, conseguem dividir automaticamente os dados em conjuntos de treinamento, teste e validação e, em seguida, executar treinamento e validação em paralelo. O deploy é condicional: os modelos só vão para um endpoint canário após a validação bem-sucedida e, depois, são totalmente liberados com base em métricas positivas de ML.
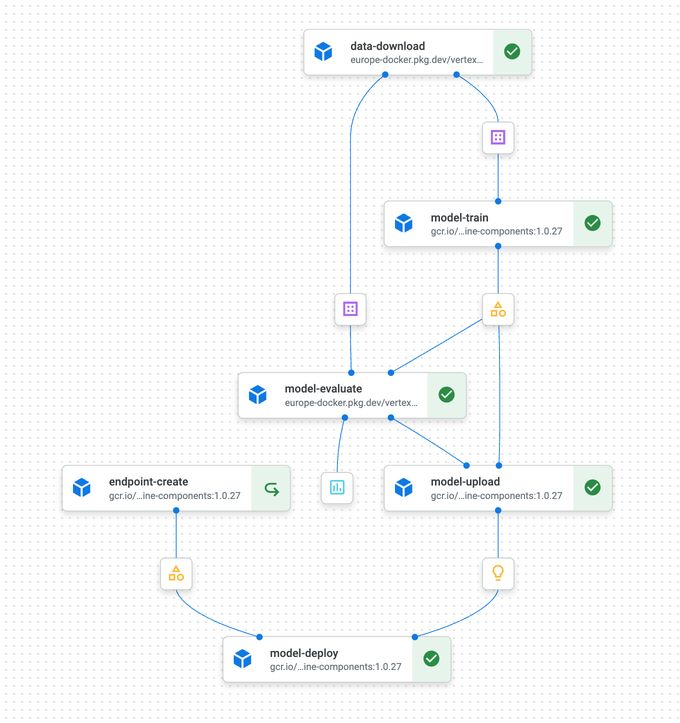
Exemplo de fluxo de pipeline
Pipelines aumentam a robustez ao registrar e monitorar todas as atividades. Diante de erros, podem reexecutar automaticamente, voltar a uma funcionalidade mais simples ou encerrar a execução. Além disso, mitigam backpressure — situações em que um componente do pipeline é sobrecarregado pelo fluxo de dados — por meio de mecanismos de buffer configuráveis.
Quando adotar
Esses são apenas alguns dos serviços oferecidos pelas suítes de ML na nuvem, e existem dezenas de outros. Minha recomendação é adotá-los. Cada um tem um time de produto dedicado, atento às necessidades de milhares de desenvolvedores de ML, e um time de operações robusto garantindo uptime consistente. Adotar um serviço pronto é muito mais simples do que construir o seu do zero.
Mas, sendo realista, você não consegue adotar todos de uma vez: já está ocupado demais com os sistemas que tem hoje.
O segredo é migrar para um serviço exatamente antes de cair no "atoleiro" das soluções customizadas. Integre um serviço de MLOps logo antes de investir esforço significativo em uma versão caseira equivalente. Assim, você ganha uma infraestrutura robusta, cheia de recursos, e evita um ciclo infinito de recriar funcionalidades que já existem prontas.
Veja alguns cenários:
- Hoje, seu desenvolvimento envolve treinamento e validação disparados a partir de um Jupyter Notebook. Ao adicionar dois cientistas de dados, surge a necessidade de colaboração e fluxos compartilhados. Você talvez pense em uma solução baseada em Git com scripts customizados. Pare! Essa abordagem até pode funcionar no início, mas vira uma bagunça rapidinho. No lugar disso, aproveite serviços integrados de notebook, treinamento e previsão para montar um sistema robusto e distribuído.
- Da mesma forma, rastrear modelos em uma planilha do Google pode bastar no começo. Mas, quando você começa a se enrolar para vincular modelos a datasets e recorre às APIs do Google Sheets, é hora de mudar. Adote um registry de modelos e um repositório de metadados antes que a complexidade fique inadministrável.
- Da mesma maneira, subir um endpoint de previsão em uma máquina virtual (VM) é simples. Mas o tráfego diário oscila no ritmo das ligas de basquete, e a tentação é adicionar mais máquinas. Se tentar automatizar isso, você corre o risco de replicar funcionalidades já presentes em um serviço dedicado de previsão, que normalmente inclui auto-scaling, monitoramento de ML e gestão de múltiplas versões.
ML exige MLOps
Você é o melhor do mundo na sua área de especialização — neste caso, em prever o resultado de jogos de basquete. Mas seu diferencial competitivo não está em montar os sistemas que rodam o ciclo de vida do seu ML. Assim que perceber que está prestes a desenvolver um sistema de MLOps, olhe para a nuvem e adote o serviço apropriado.
Fale com a gente!
Este artigo nasceu de várias conversas que tive com empresas de ML em rápido crescimento. Para saber mais, venha bater um papo comigo e com meus colegas sobre seus desafios de ML: doit.com/services