Cloud-MLOps für mehr Tempo und Effizienz
Ein revolutionärer Machine-Learning-Algorithmus, den Sie während Ihres Studiums entwickelt haben, sagt die Sieger von Basketballspielen voraus, indem er Spieldaten und die Stimmung der Fans auswertet. Dieser Durchbruch bildet das Fundament Ihres neuen Startups. Anfangs ist die Entwicklung überschaubar – dank der begrenzten Datenmenge läuft Ihr Algorithmus problemlos auf einer einzigen virtuellen Maschine, ob in der Cloud oder auf Ihrem Laptop.

Es wächst Ihnen über den Kopf
Doch sobald Ihr Startup Fahrt aufnimmt, mehrere Ligen unter Vertrag bringt und immer mehr Kunden gewinnt, explodiert der Datenstrom. Aus der anfänglichen Einfachheit wird die Komplexität, mehrere VMs rund um die Uhr zu betreiben, sich um Sicherheit zu kümmern und OS-Patches einzuspielen. Wachstum beflügelt – kann aber auch erdrücken. Das tägliche Modelltraining, die Performance und die Deployment-Entscheidungen im Blick zu behalten, wird zur echten Herausforderung. Welches Modell sollten Sie für den optimalen Kundennutzen ausrollen?
In diesem Beitrag stelle ich die zahlreichen Machine-Learning-Operations-Dienste (MLOps) vor, die Cloud-Plattformen wie Google Cloud Platform (GCP), Amazon Web Services (AWS) und Azure anbieten, um genau diese Skalierungshürden zu meistern.
Die schiere Menge an Diensten kann erschlagen – ich zeige Ihnen daher, woran Sie erkennen, wann ein neuer Dienst sinnvoll ist: genau dann, wenn Sie ihn brauchen.
Die Bandbreite von MLOps
Das folgende Diagramm zeigt zentrale MLOps-Schritte (es gibt noch viele weitere, aber diese gehören zu den ersten, die Sie einführen werden). Diese Schritte fallen ohnehin an – möglicherweise erledigen Sie sie heute manuell. Die Kunst besteht darin zu erkennen, wann Cloud-Dienste sie automatisieren und verschlanken können.
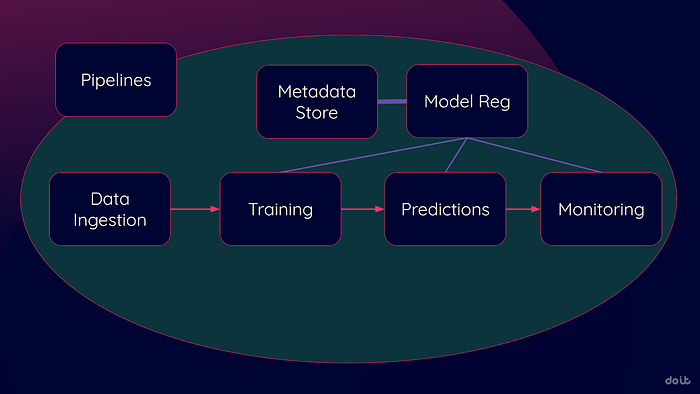
Alle großen Cloud-Anbieter haben vergleichbare Suiten im Programm: Google Vertex AI, AWS SageMaker und Azure Machine Learning. Auch wenn sich die Details unterscheiden, übernehmen die Dienste eine ähnliche Rolle auf Ihrem Weg zu automatisierten MLOps.
Die Grundlagen
Gehen wir die Schritte in der typischen Reihenfolge der Einführung durch und beginnen mit Entwicklung, Training und Vorhersage.
Entwicklung
Zu Beginn reichen Jupyter Notebooks auf Ihrem Laptop oder einer VM in der Regel aus. Allerdings zahlen Sie dann durchgehend für Rechenressourcen. Cloud-basierte Entwicklungsplattformen wie Vertex AI Workbench, SageMaker Studio oder AzureML Notebooks sind die bessere Alternative. Sie bieten die vertraute Jupyter-Oberfläche, aber zu Pay-as-you-go-Konditionen, und sind nur während Ihrer Arbeitszeit aktiv. Vorkonfigurierte Umgebungen mit allen wichtigen Tools (z. B. TensorFlow) sind enthalten – das vereinfacht die Zusammenarbeit und nimmt Ihnen die Last der Infrastrukturpflege inklusive Sicherheits-Patches ab.
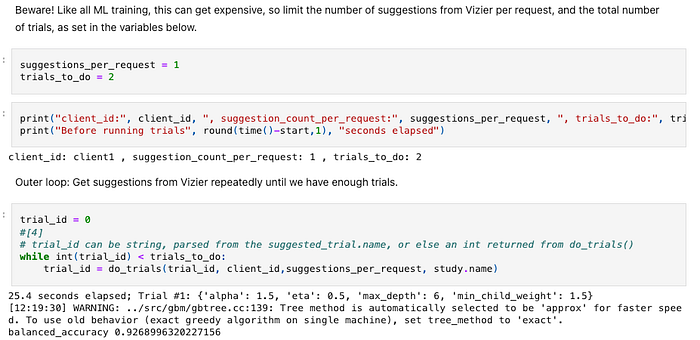
Beispiel-Notebook: keine Funktionen, sondern linearer Code, vermischt mit Ausgaben
Zwei Warnungen zu Notebooks
1. Auch wenn die Clouds Dienste anbieten, die Notebooks als Pipelines ausführen: Tun Sie es nicht. Notebooks sind für die interaktive Entwicklung gedacht, nicht für den produktiven Betrieb. Ihr sequenzieller, oft unstrukturierter Code lässt sich schwer warten, und Ausgaben, die zwischen den Code gemischt sind (zum Beispiel die Metrik balanced_accuracy von 0.9268996320227156 oben), erschweren die Versionsverfolgung. Nutzen Sie Notebooks für die Entwicklung – aber Pipelines für die Ausführung.
2. Verlagern Sie rechenintensive Aufgaben wie das Training auf Cloud-Dienste, statt die Ressourcen des Notebooks zu belasten. So zahlen Sie nicht den ganzen Arbeitstag über für ungenutzte CPU, GPU und Speicher. Überlassen Sie der Cloud die Schwerstarbeit.
Training
Training ist häufig ressourcenintensiv. Cloud-Trainingsdienste stellen eine API bereit, über die Sie das Training auf skalierbare Cloud-Ressourcen auslagern. Der Dienst skaliert die Rechenressourcen hoch, und Sie zahlen nur für die tatsächlich verbrauchten Ressourcen (GPU, CPU, Speicher) während des Trainingslaufs. Sie übergeben einen Docker-Container an die API, sodass der Dienst Ihren eigenen Algorithmus ausführt. Falls Sie Standardalgorithmen einsetzen, müssen Sie nicht einmal einen Container erstellen: Geben Sie dem Dienst einfach den gewünschten Algorithmus an.
Vorhersage (Inference)
Vorhersage bedeutet, das Modell für seinen eigentlichen Zweck einzusetzen – etwa um Spielergebnisse zu prognostizieren. Anfangs reicht ein selbst gehosteter Webserver, doch sobald Sie neue Fans gewinnen, sollten Sie auf einen Cloud-Vorhersage-Endpunkt umsteigen. Diese Dienste bieten automatisches Skalieren, Sicherheit, Monitoring und Performance-Tracking.
Vorhersagedienste bieten zwei Varianten, über die ein selbstgebauter Endpunkt meist nicht verfügt: Wenn Sie eine schnelle Antwort auf eine einzelne Anfrage brauchen, liefert ein On-Demand-Endpunkt die niedrigste Latenz. Müssen dagegen Tausende Anfragen verarbeitet werden, erreicht ein Batch-Endpunkt einen höheren Durchsatz pro Sekunde – auch wenn die einzelne Antwort länger dauert.
Mehr als die Grundlagen: MLOps skalieren
Entwicklung, Training und Vorhersage bilden den Kern; doch um die wachsende Komplexität zu beherrschen, braucht es zusätzliche MLOps-Dienste. Die Cloud-ML-Suiten bieten Lösungen, die diese Aufgaben vereinfachen. Jeden dieser Dienste können Sie unabhängig von den anderen über REST-Schnittstellen und Software-Bibliotheken nutzen – setzen Sie aber mehrere ein, profitieren Sie von einer integrierten Anbindung, die das Zusammenspiel deutlich erleichtert.
Metadaten
Sie trainieren vielleicht ein neues Modell pro Tag, dazu ein paar experimentelle Varianten – und schon sind es Hunderte. Eine Tabellenkalkulation reicht dafür längst nicht mehr aus. Model Registries und Metadata Stores schaffen Abhilfe.
Speichern Sie Modell-Dateien im Object Storage (Amazon S3, Google Cloud Storage, Azure Blob Store) und nutzen Sie die Registry, um sie samt wichtiger Metadaten – etwa dem Erstellungsdatum – nachzuverfolgen.
Darüber hinaus können Metadata Stores die Herkunft Ihrer Artefakte lückenlos verknüpfen. Sie können nachvollziehen:
- Die Daten hinter dem Modell: Enthielt das Trainingsset eines Modells die Daten der Meisterschaftsviertelfinals?
- Die Hyperparameter für das Training: Welche liefern die besten Ergebnisse?
- Code: Welcher Git-Commit enthält genau den Code, der Ihren eigenen Algorithmus ausgeführt hat?
- Endpunkte: Welche Modellversion lieferte am Tag vor dem Basketball-Viertelfinale die Vorhersagen an den Kunden?
Monitoring
Integriertes Monitoring während Training und Vorhersage erlaubt es Ihnen, die Performance in Echtzeit zu verfolgen; es ermöglicht automatisierte Modellauswahl und Canary-Deployments und sorgt so für reibungslose Übergänge und optimale Performance.
Kontinuierliches Monitoring nach dem Deployment erkennt Performance-Einbrüche. Beispielsweise könnte das Modell mit verzerrten Daten trainiert worden sein, oder die Ergebnisse driften, weil sich die realen Daten verändern – etwa wenn ein neues Team in die Top-Liga aufsteigt. Über das Monitoring lässt sich bei Bedarf automatisch ein neu trainiertes Modell einspielen.
Pipelines
Startups in der Frühphase steuern Machine-Learning-Workflows oft manuell: programmieren, trainieren, deployen, Modelle versionieren und Performance überwachen. Mit zunehmender Größe wird das untragbar. Ein wiederholbarer Prozess ist entscheidend – und cloud-basierte ML-Pipeline-Dienste wie Google Vertex AI, AWS SageMaker und Azure Machine Learning liefern genau das. Dabei handelt es sich nicht um simple sequenzielle Skripte; sie verwalten komplexe Abhängigkeiten und Parallelisierung. Beispielsweise können sie Daten automatisch in Trainings-, Test- und Validierungs-Sets aufteilen und Training und Validierung parallel ausführen. Das Deployment erfolgt bedingt: Modelle werden erst nach erfolgreicher Validierung an einen Canary-Endpunkt ausgespielt und dann auf Basis positiver ML-Metriken vollständig ausgerollt.
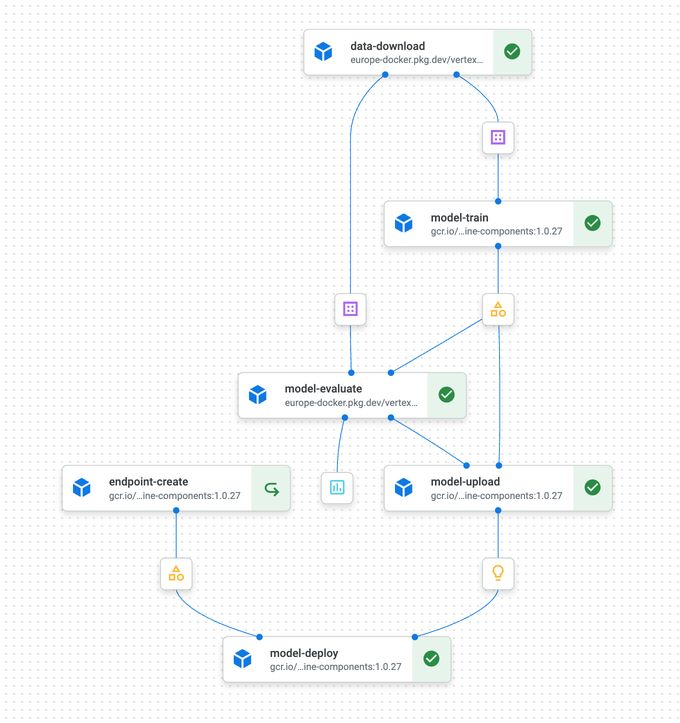
Beispielhafter Pipeline-Ablauf
Pipelines sorgen für mehr Robustheit, indem sie alle Aktivitäten protokollieren und überwachen. Bei Fehlern können sie automatisch erneut starten, auf einfachere Funktionen zurückfallen oder den Lauf abbrechen. Außerdem entschärfen sie Backpressure – also Situationen, in denen eine Pipeline-Komponente vom Datenstrom überfordert wird – mithilfe konfigurierbarer Pufferungsmechanismen.
Wann einsteigen?
Das sind nur einige der Dienste aus den Cloud-ML-Suiten – es gibt Dutzende mehr. Mein Rat: Setzen Sie sie ein. Hinter jedem steht ein eigenes Produktteam, das die Bedürfnisse Tausender ML-Entwicklerinnen und -Entwickler kennt, sowie ein erfahrenes Operations-Team, das für eine konstante Verfügbarkeit sorgt. Einen vorhandenen Dienst zu übernehmen ist deutlich einfacher, als alles selbst von Grund auf zu bauen.
Realistisch betrachtet können Sie aber nicht alles auf einmal einführen: Ihre heutigen Systeme halten Sie ohnehin schon auf Trab.
Entscheidend ist, genau dann auf einen Dienst umzusteigen, bevor Sie im Sumpf der Eigenlösungen versinken. Integrieren Sie einen MLOps-Dienst kurz bevor Sie erheblichen Aufwand in ein selbstgebautes Pendant stecken würden. So bekommen Sie eine robuste, funktionsreiche Infrastruktur und vermeiden den endlosen Kreislauf, Funktionen nachzubauen, die längst verfügbar sind.
Hier ein paar Szenarien:
- In Ihrer aktuellen Entwicklung stoßen Sie Training und Validierung über Jupyter Notebooks an. Mit zwei zusätzlichen Data Scientists werden Zusammenarbeit und gemeinsame Workflows nötig. Sie überlegen vielleicht, eine Git-basierte Lösung mit eigenen Skripten aufzubauen. Stopp! Anfangs mag das genügen, doch es wird schnell unhandlich. Setzen Sie stattdessen auf integrierte Notebook-, Trainings- und Vorhersagedienste, um ein robustes, verteiltes System aufzubauen.
- Genauso reicht es zu Beginn vielleicht, Modelle in einem Google Sheet zu verwalten. Sobald Sie aber damit ringen, Modelle mit Datensätzen zu verknüpfen, und auf die Google-Sheets-APIs zurückgreifen, ist es Zeit für einen Wechsel. Führen Sie eine Model Registry und ein Metadata Repository ein, bevor die Komplexität überhandnimmt.
- Auch das Deployment eines Vorhersage-Endpunkts auf einer virtuellen Maschine (VM) ist auf den ersten Blick einfach. Doch der tägliche Traffic schwankt im Rhythmus der Basketball-Ligen, und Sie sind versucht, weitere Maschinen hinzuzufügen. Wenn Sie das automatisieren wollen, riskieren Sie, Funktionen nachzubauen, die ein dedizierter Vorhersagedienst längst mitbringt – etwa Auto-Scaling, ML-Monitoring und Multi-Version-Management.
ML braucht MLOps
Sie sind weltweit die Nummer eins in Ihrem Spezialgebiet – in diesem Fall in der Vorhersage von Basketball-Ergebnissen. Ihr eigentlicher Wettbewerbsvorteil liegt aber nicht darin, die Systeme aufzubauen, die Ihren ML-Lifecycle betreiben. Sobald Sie merken, dass Sie gerade dabei sind, ein MLOps-System zu entwickeln, werfen Sie einen Blick in die Cloud und greifen Sie zum passenden Dienst.
Sprechen Sie mit uns!
Dieser Artikel basiert auf einer ganzen Reihe von Gesprächen, die ich mit schnell wachsenden ML-Unternehmen geführt habe. Sie wollen mehr erfahren? Sprechen Sie mit mir und meinen Kolleginnen und Kollegen über Ihre ML-Herausforderungen: doit.com/services