
要約:Amazon SageMakerは機械学習パイプラインの構築をかつてないほど手軽にし、データサイエンティストやエンジニアの開発スピードを大きく押し上げます。
"photo of black digital alarm" by John Cobb on Unsplash
NYC Taxi and Limousine Commissionは、ニューヨーク都市圏のタクシー乗車に関する詳細なデータを公開しています。このデータはこれまで多くのデータサイエンスプロジェクトやKaggleコンペで題材として取り上げられてきました。本チュートリアルでは、出発地・目的地・乗車時刻をもとに料金を予測するサービスを構築します。同じような機能はほとんどの配車サービス企業で実装されており、ここで紹介する考え方は他の地理空間予測タスクにも応用できます。
あなたがUberやLyftのような大手配車サービス企業のデータサイエンティストだとしましょう。乗車・降車地点の座標、乗車日時、想定乗客数といった生の特徴量から、メーター料金を見積もる予測サービスを開発するよう求められた——そんなシーンを思い浮かべてみてください。
機械学習を使えば精度の高い予測モデルを構築できますが、そのためには学習用に膨大な量のデータが必要です。
本記事で扱う課題を解決するための戦略は、次の5ステップで構成されます。
- データを探索する
- データセットを構築する
- モデルを学習する
- モデルを評価する
- 本番環境にデプロイする(監視と改善)
この戦略は、Kaggleのような類似の課題に直面した多くのソフトウェア企業で活用できます。とはいえ、こうした問題は標準的な機械学習パイプラインで十分に解けるにもかかわらず、私が話を聞く企業の多くは、この極めて標準的なパイプラインを自前で実装することに膨大な時間を割き、貴重な開発リソースを浪費しています。
もし何らかの事情でAWS上にこの種のサービスを構築している最中なら、ぜひ手を止めて本記事を読んでみてください。何週間分ものコーディングや試行錯誤を省けるはずです。私自身、同じ道を通ってきたから言えることです。
Amazon SageMakerを使えば、学習・デプロイ・推論までを含むMLパイプライン全体を、シンプルかつスピーディーに開発できます。2017年11月に発表されたAmazon SageMakerは、データサイエンティスト、開発者、機械学習の専門家が機械学習モデルを大規模に構築・学習・ホスティングできる、フルマネージドのエンドツーエンド機械学習サービスです[1]。
本チュートリアルの完全なコードはこちらから入手できます。
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
本演習では、Googleがこちらで公開しているデータセットから、2011年〜2015年の乗車記録およそ5,000万件を抽出して使用しました。
ステップ1:データを探索する
機械学習パイプライン構築の第一歩は、いつもデータセットの探索から始まります。AWSはこのためにSageMakerのノートブック機能を提供しています。これは標準的なJupyter Notebookサーバーで、データサイエンティスト御用達のPythonパッケージが一式プリインストールされています。
データセット(zip圧縮されたcsvファイル)をS3バケットにアップロードしたら、pandasで読み込んでみましょう。先述のとおりこのファイルには5,000万件を超えるレコードが含まれており、単一マシンで処理するには荷が重いボリュームです。すべてのデータをメモリにロードしようとすると、ディスクとメモリ容量の大きい高価なインスタンスが必要になります。データ探索の段階であれば、今回のケースでは10万件程度で十分でしょう。このくらいの規模なら、有効な統計量を得つつ、比較的安価なマシンでもクエリを高速に実行できます。
軽くEDA(探索的データ分析)を行ってまず気付いたのは、時間関連の特徴量の重要性です。下図のとおり、距離あたりの料金は時間帯によって大きく変動します。
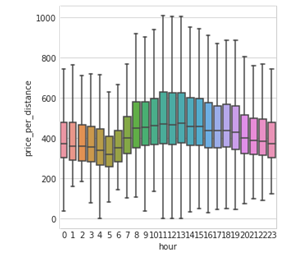 時間帯別の距離あたり乗車料金
時間帯別の距離あたり乗車料金
もう一つの気付きは、空港がNYCのタクシー需要に大きく寄与している点です。乗車・降車地点の座標を散布図にすると、ラガーディア空港とJFK空港が際立って高い値を示します。
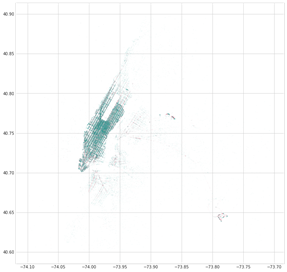 乗車・降車地点
乗車・降車地点
これらの傾向はNYCタクシーデータの分析でしばしば言及されるものです。さらに踏み込んだ知見はKaggleコンペやこちらのブログ記事を参照してください。
ステップ2:データセットを構築する
データ探索で得られた知見を踏まえ、次の特徴量を抽出することにしました。
- 連続値・カテゴリ値としての時間:日、曜日、月、年、月内の日付、時、分
- 周期的な時間:日次・週次の周期に対するsin/cos
- 距離:幾何学的距離
- 空港距離:JFK、ラガーディア、マンハッタンと乗車・降車地点との距離
- 生の特徴量:座標と乗客数
これらの特徴量をデータセット全体に対して計算するには、分散コンピューティングおよびストレージ技術の活用が欠かせません。
AWSには大規模なcsvデータセットを扱うためのツールが揃っており、データセットの加工・クエリ・エクスポートを比較的簡単に行えます。私は生のCSVの保存にAWS S3、ファイルのパーティション分割にAWS Glue、特徴量抽出のためのSQL実行にAWS Athenaを使いました。
データセットを学習用とテスト用に分割するにあたっては、2つの選択肢を検討しました。
- WHERE句を使った2本のクエリを実行し、期間ごとに別々のデータセットを作成する
- 1本のクエリでパーティション化されたデータセットを作成し、AWS-cliのs3コマンドでパーティションを別パスに移動する
本番システムなら断然1つ目を選ぶべきですが、本演習では2つ目でも十分機能しました。
注:パーティション化されたcsvをlibsvmへ変換するコードでは、SageMakerの実装担当者がパーティションを特徴量として扱い忘れているようです。そのため、年月でパーティション分割すると実際には情報が欠落してしまいます。これを防ぐには、パーティション列を明示的に追加すれば回避できます。
ステップ3:モデルを学習する
いよいよ本題です。Amazon SageMakerの真骨頂と言えるパートに入ります。
データ探索と特徴量抽出が終わったら、いよいよ学習アルゴリズムをデータにフィットさせていきます。AmazonはこのためにTensorflow、XGBoost、PyTorchを含む10種類の主要アルゴリズム・ライブラリを独自に実装しています。それでも足りなければ、自作アルゴリズムをコンテナ化してSageMaker上で動かすこともできます。
このような数百万件規模の構造化データに対して、私が真っ先に選ぶのはXGBoostです。最適化アルゴリズムと内部のデータ構造のおかげで、XGBoostはCPUでも高速に収束し、数GBのデータをRAM上で処理できます。XGBoostのパラメータチューニングは少々クセがありますが、経験を積めば良いスタート地点を掴めるようになり、学習時間を抑えつつ過学習も防げます。最高精度を狙うなら何らかのハイパーパラメータ最適化を行うのがおすすめで、これもSageMakerでカバーされています(本記事では扱いません)。:)
XGBoostを選んだ理由を補足すると、複数のデータセットでの実験で、ニューラルネットワークに迫る非常に良好な成績を示しているからです。実際、ここ数年のKaggle優勝ソリューションには、ほぼ必ず何らかのGradient Boosting Machinesの実装が含まれています。
とはいえ、データサイエンスにおける真実は数字だけです。お好みのライブラリで気軽に試して、結果を下のコメント欄で教えてください。
学習を実行するには、主に2つのオブジェクトが必要です。
- SageMakerのS3入力オブジェクト。ステップ3で作成したパーティション化済みcsvのtrain/valを指定します。distribution='ShardedByS3Key'を指定すれば、データセットを複数マシンにシャーディングできるため学習が大幅に速くなりますが、同時にモデル学習に使われるサンプル数も減ります。
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- XGBoostコンテナ、SageMakerセッション、IAMロールから構築するSageMakerのestimator。パラメータで学習インスタンスの数とインスタンスタイプを指定し、ジョブを送信すると、SageMakerがリクエストに応じてリソースを割り当てます。
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)モデルインスタンスを作ったら、ハイパーパラメータのプリセットを設定して学習ジョブを投入します。
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})驚くかもしれませんが、本日のコーディングはこれで(ほぼ)完了です。あとはSageMakerのコンソールに移動して学習プロセスを追跡しましょう。学習中、XGBoostが割り当てインスタンスのCPUを100%近くまで使い切る様子を眺めるのも一興です。
本記事の残りでは、SageMakerのコンソールを使ってモデルをデプロイし、推論を呼び出せる状態にしていきます。
ステップ4:モデルを評価する
学習が完了すると、モデルはあらかじめ指定したS3バケットに出力されます。検証セットを含む新しいデータに対して推論を行うには、学習ジョブを選択し、ダッシュボード上の「Create model」ボタンをクリックしてモデルを「作成」する必要があります。画面の指示に従えばすぐに完了するはずです。
次にバッチ変換ジョブを作成し、これを使って交差検証データを評価します。このデータには目的変数列を含めてはならないため(AWSさん、本気ですか…?)、おそらくデータをもう一度変換して目的変数を取り除く作業が必要になります。
バッチ変換の結果、誤差は十分に小さく、経営陣との長い議論(あなたはUber/Lyftで働いている設定でしたね)の末、本番投入に値すると判断されました。seabornのregplotを使って、交差検証セットでの誤差分布を示したのが下図です。
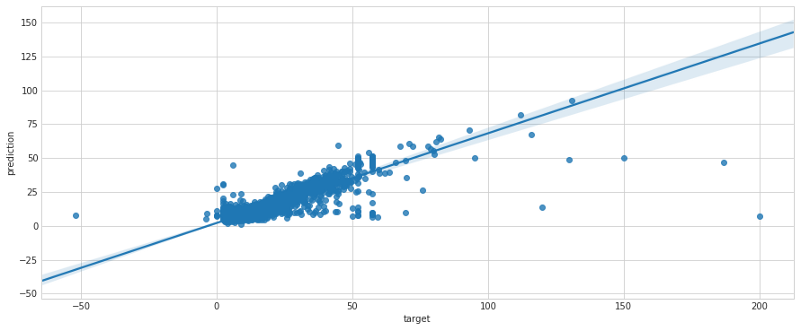
ステップ5:本番環境にデプロイする
モデルを評価し、自社システムに組み込むと決めたら、オンライン推論を行う仕組みが必要になります。モデルがSageMakerに保存されていれば、推論サービスの構築はこれ以上ないほど簡単です。
ここではモデルを呼び出す方法を2通り紹介します。
- EC2上でPythonのboto3クライアントを使う方法
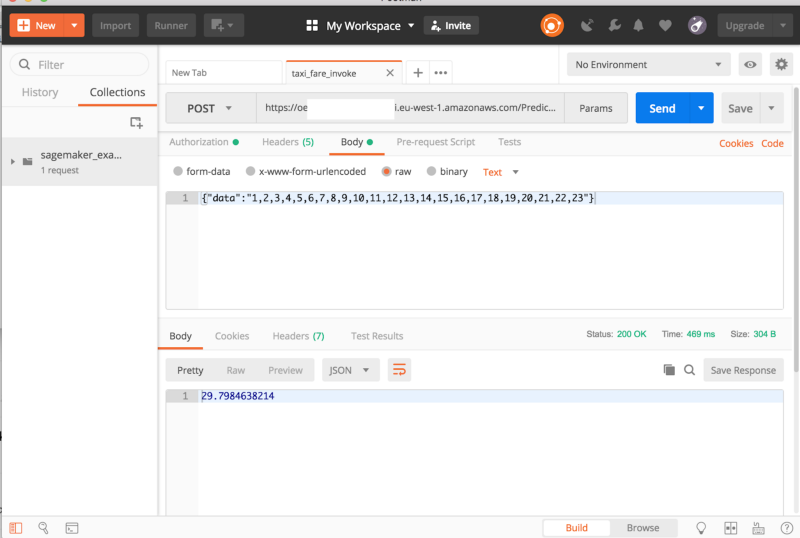
- APIにPOSTリクエストを送る方法
どちらの方法でも、エンドポイント設定とエンドポイントの作成が必要です。手順自体は非常に簡単で、設定が済めば、次のようにboto3 Pythonクライアントから推論を呼び出せます。
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)2つ目の方法は、POSTリクエストを利用するやり方です。外部サービスに公開する場合は、Lambda関数を呼び出すAPI Gatewayを作成します。詳しくはこちらを参照してください。
まとめると、AWSは機械学習パイプライン構築のための優れたツールを提供しています。SageMakerを使えば、市場投入までの時間を確実に短縮できます。ただ欲を言えば、データ加工まわりのソリューションがもう少し充実し、パーティション周りの細かな課題が解消されると、なお嬉しいところです。
[1] https://aws.amazon.com/blogs/aws/sagemaker/
もっと記事を読みたい方は、ぜひブログをチェックするか、GadのTwitterをフォローしてください。