
TL;DR: Amazon SageMaker ofrece una forma sencilla como nunca antes de implementar pipelines de machine learning y acorta de forma notable el time-to-market para científicos e ingenieros de datos.
"foto de despertador digital negro" por John Cobb en Unsplash
La NYC Taxi and Limousine Commission publica información detallada sobre los viajes en taxi del área metropolitana. Estos datos han sido objeto de muchos proyectos de data science y de varias competencias en Kaggle. En este tutorial voy a construir un servicio que predice la tarifa de un viaje a futuro a partir del origen, el destino y la hora de recogida. Lo más probable es que la mayoría de las empresas de ride-hailing ya tengan implementado un servicio con una funcionalidad similar, y la idea general también se aplica a otros problemas de predicción geoespacial.
Imagínate esto: trabajas como científico de datos en una de las grandes empresas de ride-hailing, como Uber o Lyft. Te piden desarrollar un servicio de predicción que estime el precio esperado del viaje (definido por un taxímetro) a partir de las siguientes features sin procesar: coordenadas de recogida y destino, fecha y hora de recogida, y número de pasajeros que se espera que aborden.
Con machine learning podrás construir un modelo de predicción preciso. Eso sí, vas a necesitar enormes cantidades de datos para el entrenamiento.
La estrategia para resolver el problema descrito incluye los siguientes 5 pasos:
- Explorar los datos
- Construir un dataset
- Entrenar un modelo
- Evaluar el modelo
- Desplegar a producción (monitorear y refinar)
Esta estrategia la pueden aplicar muchas empresas de software cuando se enfrentan a problemas similares al estilo Kaggle. Sin embargo, aunque estos problemas se resuelven con un pipeline de machine learning estándar listo para usar, la mayoría de las empresas con las que hablo invierten una cantidad considerable de tiempo construyendo su propia versión de este pipeline tan estándar, perdiendo así muchas horas de sus desarrolladores.
Si, por alguna razón, tu equipo está desarrollando este tipo de servicio en AWS, deberías detenerte y leer este artículo: te va a ahorrar semanas de programación e iteraciones. ¡Créeme, ya pasé por eso!
Con Amazon SageMaker resulta relativamente sencillo y rápido desarrollar un pipeline completo de ML, que incluye entrenamiento, despliegue y generación de predicciones. Anunciado en noviembre de 2017, Amazon SageMaker es un servicio de machine learning totalmente administrado, de extremo a extremo, que permite a científicos de datos, desarrolladores y expertos en machine learning construir, entrenar y hospedar modelos a escala de manera ágil [1].
El código completo de este tutorial lo encuentras aquí:
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
Para este ejercicio utilicé un dataset publicado aquí por Google, del cual extraje aproximadamente 50M de registros (viajes) entre 2011 y 2015.
Paso 1: Explora los datos
Como siempre, el primer paso para construir un pipeline de machine learning es explorar el dataset. Para esto, AWS ofrece la herramienta de notebooks de SageMaker, que es un servidor estándar de Jupyter Notebook con todos los paquetes de Python imprescindibles para científicos de datos preinstalados.
Una vez subido el dataset (archivo csv comprimido) al bucket de S3, vamos a leerlo con pandas. Como ya mencioné, el archivo contiene más de 50 millones de registros, lo cual lo convierte en una tarea complicada para una sola máquina. Además, cargar todos los datos en memoria requiere una instancia costosa con buena capacidad de disco y RAM. En mi opinión, para fines de exploración basta con ~100K registros. Trabajar con esa cantidad de datos genera estadísticas válidas y, al mismo tiempo, permite consultar los datos con rapidez en una máquina de bajo costo.
Una conclusión importante que saqué del EDA rápido que hice fue la relevancia de las features temporales. Como puedes ver, el precio por distancia varía muchísimo según la hora del día.
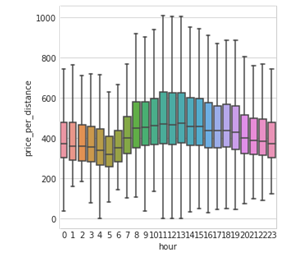 Tarifa por distancia según hora del día
Tarifa por distancia según hora del día
Otra observación tiene que ver con el peso de los aeropuertos en el negocio del taxi en NYC. Al generar un scatter plot de las coordenadas de recogida y destino, LaGuardia y JFK destacan con cifras muy altas.
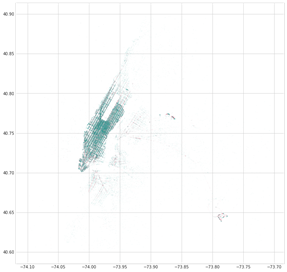 ubicaciones de recogida y destino
ubicaciones de recogida y destino
Estos hallazgos se mencionan con mucha frecuencia al analizar los datos del taxi de NYC. Encontrarás más información sobre el tema y otros insights en la competencia de Kaggle y en esta entrada de blog.
Paso 2: Construye un dataset
A partir de los hallazgos de la fase de exploración, decidí extraer las siguientes features:
- Tiempo secuencial/categórico: día, día de la semana, mes, año, día del mes, hora, minuto
- Tiempo cíclico: sin/cos de la frecuencia diaria y semanal
- Distancia: distancia geométrica
- Distancia a aeropuertos: distancia de recogida y destino respecto a JFK, LaGuardia y Manhattan
- Features sin procesar: coordenadas y número de pasajeros
Calcular estas features sobre el dataset completo requiere usar técnicas de cómputo y almacenamiento distribuidos.
Amazon AWS ofrece varias herramientas para manejar datasets csv grandes con las que es posible procesar, consultar y exportar datos con bastante facilidad. Usé AWS S3 para almacenar el CSV sin procesar, AWS Glue para particionar el archivo y AWS Athena para ejecutar consultas SQL en la extracción de features.
A la hora de dividir el dataset en train y test consideré dos opciones:
- Ejecutar dos consultas, usando una cláusula WHERE para crear distintos datasets sobre distintos periodos; o
- Ejecutar una sola consulta para crear un dataset particionado y usar el comando AWS-cli s3 para mover diferentes particiones a nuevas rutas.
En sistemas de producción seguramente preferirías la primera opción, pero para fines de este ejercicio la segunda funcionó bien.
Nota: En el código que transforma csv particionado a libsvm, quien implementó SageMaker olvidó usar las particiones como features. Así que cuando particioné por año y mes, en realidad perdí información. Para evitarlo, agrega de manera explícita las columnas de partición.
Paso 3: Entrena un modelo
¡Por fin! Esta es la mejor parte de Amazon SageMaker.
Después de explorar los datos y extraer features, puedo empezar a ajustar un algoritmo de aprendizaje. Para esta tarea, Amazon implementó su propia versión de diez algoritmos y librerías comunes, entre ellos Tensorflow, XGBoost y PyTorch. Y, por si fuera poco, siempre puedes implementar tu propio algoritmo y ejecutarlo en SageMaker mediante un contenedor.
Para este tipo de datos estructurados, con millones de registros, mi preferencia natural es empezar a modelar con XGBoost. Por su algoritmo de optimización y su estructura de datos subyacente, XGBoost converge rápido en CPUs mientras procesa varios GB de datos en RAM. Eso sí, ajustar los parámetros de XGBoost puede ser un poco complicado, pero con experiencia se logra un buen punto de partida, minimizando el tiempo de entrenamiento y evitando el overfitting. Para los resultados más precisos, conviene aplicar algún tipo de optimización de hiperparámetros, algo que también cubre SageMaker, pero que no abordaré en este post. :)
Para cerrar el argumento de por qué elegí XGBoost como librería, vale la pena mencionar que los experimentos en múltiples datasets muestran muy buenos resultados con XGBoost, cercanos a los de las redes neuronales. Por eso, frente a este tipo de datos siempre encontrarás alguna implementación de Gradient Boosting Machines en cada solución ganadora de Kaggle de los últimos años.
Aun así, en data science no hay otra verdad que los números. Así que siéntete libre de experimentar con la librería que prefieras y cuéntanos en los comentarios cómo te fue.
Para realizar el entrenamiento necesitarás 2 objetos principales:
- El objeto S3 input de SageMaker, que apunta al csv particionado de train/val que creamos en el paso 3. Ten en cuenta que usar distribution=’ShardedByS3Key’ permite repartir los datasets entre varias máquinas, lo que hace el entrenamiento mucho más rápido, aunque también reduce el número de muestras usadas para ajustar el modelo.
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- Un estimator de SageMaker, construido con un contenedor de XGBoost, una sesión de SageMaker y un rol IAM. Mediante parámetros defines el número de instancias de entrenamiento y el tipo de instancia, y al enviar el job, SageMaker asignará los recursos según tu solicitud.
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)Una vez creada la instancia del modelo, configúrala con un preset de hiperparámetros y envía un training job.
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})Ahora, aunque no lo creas, ya (casi) terminamos de programar por hoy. Entra a la consola de SageMaker para hacer seguimiento del proceso de entrenamiento. Puedes disfrutar viendo la carga de CPU en tus instancias asignadas mientras XGBoost lleva tu CPU a casi el 100% de su capacidad durante el entrenamiento.
En el resto del post usaremos la consola de SageMaker para desplegar el modelo y dejarlo disponible para predicciones.
Paso 4: Evalúa el modelo
El entrenamiento envía la salida del modelo a un bucket de S3 que ya definimos. Para generar predicciones sobre datos nuevos, incluido nuestro set de validación, hay que "crearlo" seleccionando el training job y haciendo clic en el botón "Create model" del dashboard. Siguiendo las instrucciones en pantalla, completar la tarea debería ser fácil.
A continuación, crea un batch transform job y úsalo para evaluar tus datos de validación cruzada. Estos datos no deben contener el campo objetivo (en serio, AWS…?), así que probablemente tendrás que transformar tus datos OTRA VEZ para eliminarlo.
Los resultados de la transformación batch mostraron un error bajo, que tras largas conversaciones con la gerencia (recuerda que trabajas para Uber/Lyft) se consideró lo suficientemente bajo como para pasar a producción. Con el regplot de seaborn mostramos la distribución del error sobre el set de validación cruzada.
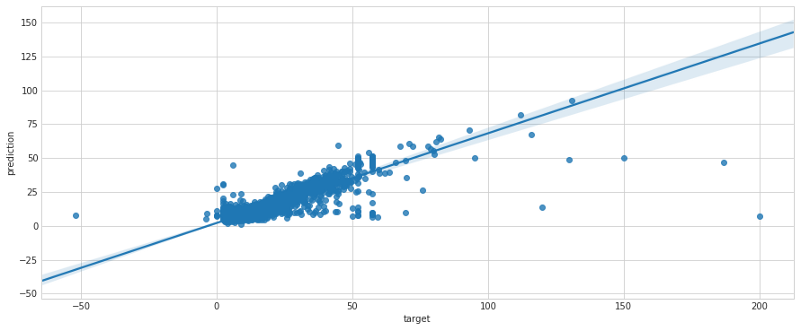
Paso 5: Despliega a producción
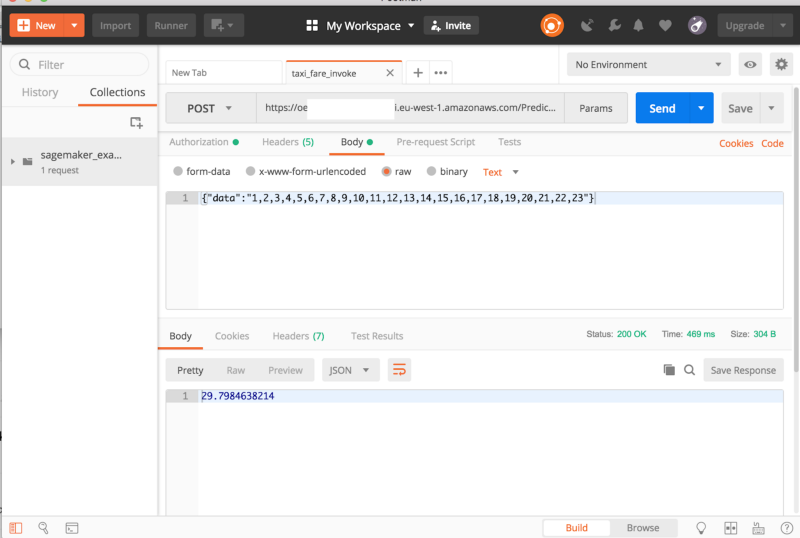
Después de evaluar el modelo y decidir que queremos exponerlo a nuestro sistema, necesitamos una forma de generar predicciones online. Con el modelo almacenado en SageMaker, construir un servicio de predicción es de lo más simple.
A continuación mostraré dos formas posibles de invocar el modelo:
- Usando un cliente boto3 de Python en una EC2
- Haciendo solicitudes POST a una API
Ambas opciones requieren crear una endpoint configuration y un endpoint. Es muy sencillo, y una vez listo podemos generar predicciones con el cliente boto3 de Python así:
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)La segunda opción sería usar una solicitud POST. Para exponerla a servicios externos, puedes crear un API Gateway que invoque una función Lambda. Lee más al respecto aquí.
En conclusión, AWS desarrolló una herramienta increíble para construir pipelines de machine learning. Usar SageMaker acortará tu time-to-market. Eso sí, sería genial que AWS mejorara las soluciones de manipulación de datos y resolviera el pequeño tema con las particiones.
[1] https://aws.amazon.com/blogs/aws/sagemaker/
¿Quieres más historias? Visita nuestro blog o sigue a Gad en Twitter.