
TL;DR: Amazon SageMaker offre un modo semplice e senza precedenti per implementare pipeline di machine learning, riducendo nettamente il time to market per data scientist ed engineer.
"foto di una sveglia digitale nera" di John Cobb su Unsplash
La NYC Taxi and Limousine Commission pubblica informazioni dettagliate sulle corse in taxi nell'area metropolitana. Questi dati sono stati al centro di numerosi progetti di data science e di diverse competizioni Kaggle. In questo tutorial costruirò un servizio capace di prevedere la tariffa di una corsa in base al punto di partenza, alla destinazione e all'orario di pickup. Un servizio con funzionalità simili è ormai presente nella maggior parte delle aziende di ride-hailing e l'idea di fondo si presta anche ad altri problemi di previsione geospaziale.
Immagina di lavorare come data scientist per una delle principali aziende di ride-hailing, ad esempio Uber o Lyft. Ti viene chiesto di sviluppare un servizio di previsione che stimi il prezzo atteso della corsa (quello del tassametro) a partire dalle seguenti feature grezze: coordinate di pickup e drop-off, data e ora del pickup e numero di passeggeri previsti a bordo.
Con il machine learning potrai costruire un modello di previsione accurato. Servono però enormi quantità di dati per il training.
La strategia per affrontare il problema si articola in 5 step:
- Esplorare i dati
- Costruire un dataset
- Addestrare un modello
- Valutare il modello
- Andare in produzione (monitorare e affinare)
È un approccio applicabile da molte software company che si trovano davanti a problemi simili a quelli di Kaggle. Eppure, anche se questi casi possono essere risolti con una pipeline di machine learning standard e pronta all'uso, gran parte delle aziende con cui parlo dedica moltissimo tempo a reimplementare la propria versione di questa pipeline standard, bruciando ore preziose dei propri sviluppatori.
Se, per qualche motivo, il tuo team sta sviluppando un servizio di questo tipo su AWS, fermati e leggi questo articolo: ti farà risparmiare settimane di codice e svariate iterazioni. Credimi, ci sono passato anch'io!
Con Amazon SageMaker sviluppare una pipeline ML completa — training, deployment e generazione di predizioni — è relativamente semplice e veloce. Annunciato a novembre 2017, Amazon SageMaker è un servizio di machine learning end-to-end completamente gestito che permette a data scientist, sviluppatori ed esperti di machine learning di costruire, addestrare e ospitare modelli ML su larga scala in tempi rapidi [1].
Il codice completo di questo tutorial è disponibile qui:
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
Per questo esercizio ho usato un dataset pubblicato qui da Google, dal quale ho estratto circa 50 milioni di record (corse) tra il 2011 e il 2015.
Step 1: esplorare i dati
Come sempre, il primo passo per costruire una pipeline di machine learning è esplorare il dataset. A questo scopo AWS mette a disposizione il notebook tool di SageMaker, un server Jupyter Notebook standard, già preinstallato con tutti i pacchetti Python "coltellino svizzero" del data scientist.
Dopo aver caricato il dataset (file csv compresso) nel bucket S3, leggiamolo con pandas. Come anticipato, il file contiene oltre 50 milioni di record, una mole difficile da gestire per una singola macchina. In più, caricare tutti i dati in memoria richiede un'istanza costosa, con grande capacità di disco e RAM. A mio avviso, ai fini dell'esplorazione, in questo caso bastano ~100K record. Lavorare con questa quantità di dati produce statistiche valide e, allo stesso tempo, permette di interrogare i dati rapidamente su una macchina dal costo contenuto.
Tra gli spunti più importanti emersi dalla rapida EDA che ho condotto, spicca il peso delle feature temporali. Come puoi vedere, il prezzo per distanza varia in modo netto a seconda dell'ora del giorno.
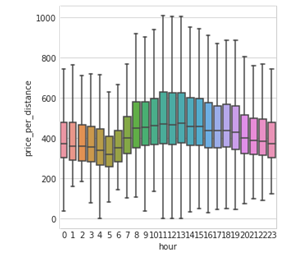 Tariffa per distanza in base all'ora del giorno
Tariffa per distanza in base all'ora del giorno
Un altro spunto riguarda il peso degli aeroporti sul business dei taxi di NYC. Generando uno scatter plot delle coordinate di pickup e drop-off, LaGuardia e JFK fanno registrare numeri molto rilevanti.
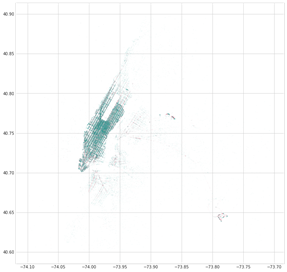 posizioni di pickup e drop-off
posizioni di pickup e drop-off
Sono osservazioni che ricorrono spesso nelle analisi dei dati dei taxi di NYC. Per approfondire l'argomento e scoprire ulteriori spunti, dai un'occhiata alla competizione Kaggle e a questo blog post.
Step 2: costruire un dataset
Sulla base degli spunti emersi dall'esplorazione dei dati, ho scelto di estrarre le seguenti feature:
- Tempo sequenziale/categorico: giorno, giorno della settimana, mese, anno, giorno del mese, ora, minuto
- Tempo ciclico: sin/cos della frequenza giornaliera e settimanale
- Distanza: distanza geometrica
- Distanza dagli aeroporti: distanza dei punti di pickup e drop-off da JFK, LaGuardia e Manhattan
- Feature grezze: coordinate e numero di passeggeri
Calcolare queste feature sull'intero dataset richiede tecniche di calcolo e storage distribuiti.
Amazon AWS offre diversi strumenti per gestire grandi dataset csv, con cui è possibile elaborare, interrogare ed esportare i dati con relativa facilità. Ho usato AWS S3 per memorizzare il CSV grezzo, AWS Glue per partizionare il file e AWS Athena per eseguire le query SQL utili all'estrazione delle feature.
Per la suddivisione del dataset tra train e test, ho valutato due opzioni:
- Eseguire due query, sfruttando una clausola WHERE per creare dataset diversi su periodi diversi; oppure,
- Eseguire un'unica query che produca un dataset partizionato e usare il comando AWS-cli s3 per spostare le diverse partizioni in nuovi path.
In un sistema di produzione opteresti senz'altro per la prima soluzione; ai fini di questo esercizio, però, la seconda ha funzionato benissimo.
Nota: nel codice che trasforma il csv partizionato in libsvm, chi ha implementato SageMaker si è dimenticato di usare le partizioni come feature. Quindi, partizionando per anno e mese, di fatto ho perso informazioni. Per evitarlo, basta aggiungere esplicitamente le colonne di partizionamento.
Step 3: addestrare un modello
Finalmente! Ecco la parte migliore di Amazon SageMaker.
Dopo aver esplorato i dati ed estratto le feature, posso iniziare ad addestrare un algoritmo di apprendimento sui dati. Per questo scopo Amazon ha implementato la propria versione di dieci algoritmi e librerie diffuse, tra cui Tensorflow, XGBoost e PyTorch. E, se non bastasse, è sempre possibile implementare un proprio algoritmo da eseguire con SageMaker tramite container.
Per dati strutturati di questo tipo, con milioni di record, la mia preferenza naturale è iniziare il modeling con XGBoost. Grazie al suo algoritmo di ottimizzazione e alla struttura dati sottostante, XGBoost converge rapidamente sulle CPU pur elaborando diversi GB di dati in RAM. Il tuning dei parametri di XGBoost può essere un po' delicato, ma con un po' di esperienza si parte già con il piede giusto, riducendo i tempi di training ed evitando l'overfitting. Per ottenere i risultati più accurati conviene effettuare una qualche forma di ottimizzazione degli iperparametri, anch'essa coperta da SageMaker, ma non in questo post. :)
Per chiudere il discorso sul perché abbia scelto XGBoost, ricordo che gli esperimenti su molteplici dataset mostrano risultati molto buoni con XGBoost, vicini a quelli delle reti neurali. Per questo, davanti a dati di questo tipo, troverai sempre qualche implementazione di Gradient Boosting Machines in tutte le soluzioni vincenti su Kaggle degli ultimi anni.
Detto ciò, in data science l'unica verità sono i numeri. Sentiti libero di sperimentare con la libreria che preferisci e facci sapere com'è andata nei commenti qui sotto.
Per eseguire il training avrai bisogno di 2 oggetti principali:
- L'oggetto S3 input di SageMaker, che punta al csv partizionato train/val creato nello step 3. Nota che usando distribution='ShardedByS3Key' è possibile distribuire (shardare) il dataset su più macchine, accelerando notevolmente il training, ma riducendo anche il numero di campioni utilizzati per addestrare il modello.
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- Un estimator di SageMaker, costruito con un container XGBoost, una sessione SageMaker e un ruolo IAM. Tramite i parametri imposti il numero di istanze di training e il tipo di istanza; al momento dell'invio del job, SageMaker allocherà le risorse in base alla richiesta che hai effettuato.
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)Una volta creata l'istanza del modello, configurala con un set predefinito di iperparametri e invia un job di training.
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})Ora, ci credi o no, abbiamo (quasi) finito di scrivere codice per oggi. Vai sulla console di SageMaker per seguire il processo di training. Potrai goderti il carico CPU sulle istanze allocate mentre XGBoost le spinge a quasi il 100% della loro capacità durante il training.
Per il resto del post useremo la console di SageMaker per fare il deployment del modello e renderlo disponibile per le predizioni.
Step 4: valutare il modello
Il training salva il modello in un bucket S3 da noi definito. Per generare predizioni su nuovi dati, incluso il nostro validation set, dobbiamo "creare" il modello selezionando il job di training e cliccando sul pulsante "Create model" nella dashboard. Seguendo le istruzioni a schermo è facile portare a termine l'operazione.
A questo punto, crea un job di batch transform e usalo per valutare i tuoi dati di cross-validation. Questi dati non devono contenere il campo target (sul serio, AWS…?), quindi probabilmente dovrai trasformare di nuovo i tuoi dati per rimuoverlo.
I risultati della batch transformation hanno mostrato un errore basso che, dopo lunghe discussioni con il management (ricorda che lavori per Uber/Lyft), è stato giudicato sufficientemente contenuto per andare in produzione. Con il regplot di seaborn mostriamo la distribuzione dell'errore sul set di cross-validation.
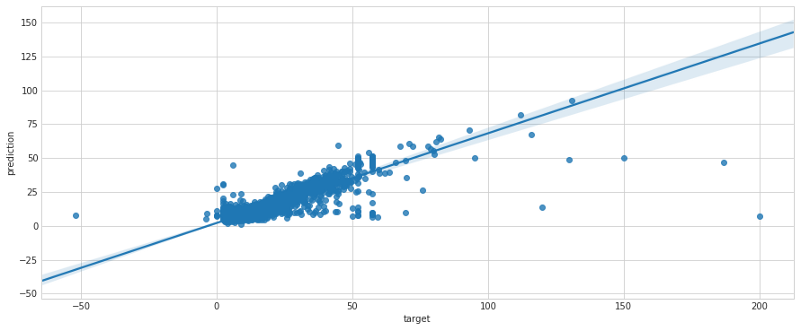
Step 5: andare in produzione
Dopo aver valutato il modello e deciso di esporlo al nostro sistema, ci serve un modo per generare predizioni online. Con il modello salvato in SageMaker, costruire un servizio di predizione è semplicissimo.
Mostrerò qui di seguito due possibili modi per invocare il modello:
- Tramite un client Python boto3 su un'istanza EC2
- Tramite richieste POST a un'API
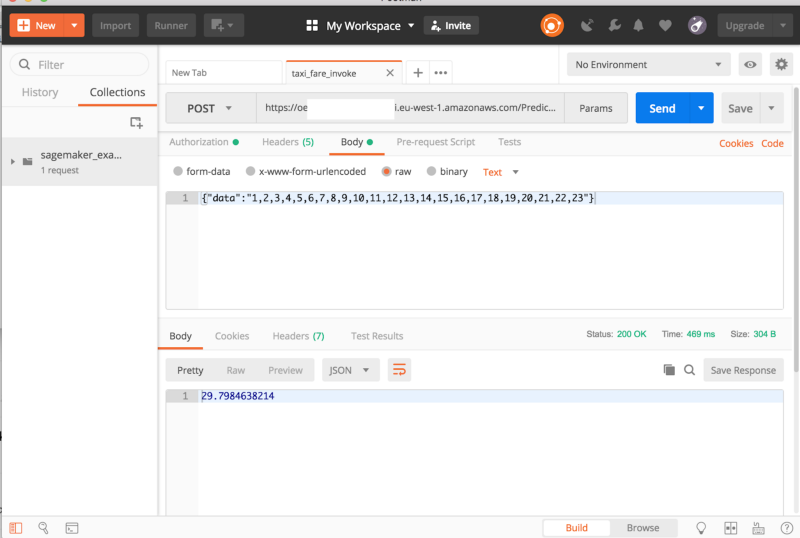
Entrambi richiedono la creazione di una endpoint configuration e di un endpoint. È un'operazione molto semplice e, una volta completata, possiamo generare predizioni con il client boto3 di Python in questo modo:
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)La seconda opzione consiste nell'usare una richiesta POST. Per esporlo a servizi esterni, puoi creare un API Gateway che invochi una funzione Lambda. Approfondisci l'argomento qui.
In conclusione, il team AWS ha messo a punto uno strumento eccezionale per costruire pipeline di machine learning. Usare SageMaker ti permetterà di accorciare il time-to-market. Detto ciò, sarebbe utile se AWS migliorasse le soluzioni di data manipulation e risolvesse il piccolo problema con le partizioni.
[1] https://aws.amazon.com/blogs/aws/sagemaker/
Vuoi altri contenuti? Dai un'occhiata al nostro blog, oppure segui Gad su Twitter.