
TL;DR : Amazon SageMaker simplifie radicalement la mise en place de pipelines de machine learning et raccourcit considérablement le time to market des data scientists et des ingénieurs.
photo of black digital alarm par John Cobb sur Unsplash
La NYC Taxi and Limousine Commission publie des informations détaillées sur les courses de taxi de la zone métropolitaine. Ces données ont alimenté de nombreux projets de data science et plusieurs compétitions Kaggle. Dans ce tutoriel, je vais construire un service qui prédit le prix d'une future course à partir du point de départ, de la destination et de l'heure de prise en charge. Un service aux fonctionnalités similaires existe sans doute déjà chez la plupart des acteurs du VTC, et la même logique s'applique à bien d'autres problèmes de prédiction géospatiale.
Imaginez la situation suivante : vous travaillez comme data scientist pour l'une des grandes plateformes de VTC, type Uber ou Lyft. On vous demande de développer un service de prédiction qui estime le prix attendu d'une course (fixé par un compteur) à partir des caractéristiques brutes suivantes : coordonnées de prise en charge et de dépose, date et heure de prise en charge, et nombre de passagers attendus à bord.
Le machine learning vous permettra de bâtir un modèle de prédiction précis. Cela exigera toutefois d'énormes volumes de données pour l'entraînement.
La stratégie pour résoudre ce problème se décline en 5 étapes :
- Explorer les données
- Construire un dataset
- Entraîner un modèle
- Évaluer le modèle
- Déployer en production (surveiller et affiner)
Cette stratégie peut être adoptée par de nombreuses entreprises logicielles confrontées à des problèmes de type Kaggle. Pourtant, alors qu'un pipeline de machine learning standard, prêt à l'emploi, suffirait à les résoudre, la majorité des entreprises avec lesquelles je discute consacrent un temps considérable à réimplémenter leur propre version de ce pipeline pourtant très standard, gaspillant ainsi de précieuses heures de développement.
Si, pour une raison ou une autre, votre équipe développe ce type de service sur AWS, posez tout et lisez cet article : il vous fera économiser des semaines de code et d'itérations. Croyez-moi, je suis passé par là !
Avec Amazon SageMaker, développer un pipeline ML complet — entraînement, déploiement et inférence — est relativement simple et rapide. Annoncé en novembre 2017, Amazon SageMaker est un service de machine learning entièrement managé et de bout en bout, qui permet aux data scientists, développeurs et experts ML de construire, entraîner et héberger rapidement des modèles à grande échelle [1].
Le code complet de ce tutoriel est disponible ici :
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
Pour cet exercice, j'ai utilisé un dataset publié ici par Google, dont j'ai extrait environ 50 millions d'enregistrements (courses) entre 2011 et 2015.
Étape 1 : explorer les données
Comme toujours, la première étape de la construction d'un pipeline de machine learning consiste à explorer le dataset. Pour cela, AWS propose l'outil notebook de SageMaker : un serveur Jupyter Notebook standard, préinstallé avec tous les packages Python indispensables aux data scientists.
Après avoir téléversé le dataset (fichier csv compressé) dans le bucket S3, lisons-le avec pandas. Comme évoqué plus haut, le fichier dépasse les 50 millions d'enregistrements, ce qui représente une tâche complexe pour une seule machine. Charger l'ensemble des données en mémoire impose en outre une instance coûteuse, dotée d'une grande capacité de disque et de RAM. À mon avis, environ 100 000 enregistrements suffisent pour explorer les données : on obtient des statistiques fiables tout en pouvant interroger les données rapidement sur une machine relativement bon marché.
L'EDA rapide que j'ai menée a livré un enseignement clé : l'importance des caractéristiques temporelles. Comme vous pouvez le constater, le prix par distance varie considérablement selon l'heure de la journée.
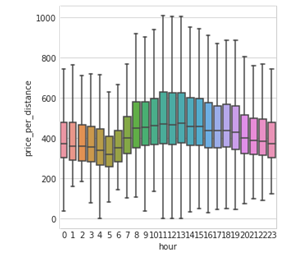 Prix de la course par distance selon l'heure de la journée
Prix de la course par distance selon l'heure de la journée
Autre constat : le poids des aéroports dans l'activité des taxis new-yorkais. Sur un nuage de points des coordonnées de prise en charge et de dépose, LaGuardia et JFK ressortent nettement.
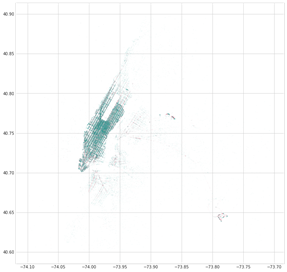 lieux de prise en charge et de dépose
lieux de prise en charge et de dépose
Ces observations reviennent très souvent dans les analyses des données des taxis new-yorkais. Pour aller plus loin, consultez la compétition Kaggle et cet article de blog.
Étape 2 : construire un dataset
À la lumière de l'exploration des données, j'ai retenu les caractéristiques suivantes :
- Temps séquentiel/catégoriel : jour, jour de la semaine, mois, année, jour du mois, heure, minute
- Temps cyclique : sin/cos des fréquences journalières et hebdomadaires
- Distance : distance géométrique
- Distance aux aéroports : distance des points de prise en charge et de dépose par rapport à JFK, LaGuardia et Manhattan
- Caractéristiques brutes — coordonnées et nombre de passagers
Calculer ces caractéristiques sur l'ensemble du dataset suppose de recourir à des techniques de calcul et de stockage distribués.
Amazon AWS propose plusieurs outils pour manipuler de gros datasets csv et ainsi traiter, interroger et exporter les données assez facilement. J'ai utilisé AWS S3 pour stocker le CSV brut, AWS Glue pour partitionner le fichier, et AWS Athena pour exécuter les requêtes SQL d'extraction des caractéristiques.
Pour séparer le dataset entre entraînement et test, j'ai envisagé deux options :
- Exécuter deux requêtes avec une clause WHERE pour créer des datasets distincts sur des périodes différentes ; ou,
- Exécuter une seule requête pour produire un dataset partitionné, puis utiliser la commande AWS-cli s3 pour déplacer les différentes partitions vers de nouveaux chemins.
En production, vous opteriez clairement pour la première option ; pour cet exercice, la seconde a parfaitement fait l'affaire.
Note : dans le code qui transforme un csv partitionné en libsvm, l'auteur de l'implémentation SageMaker a oublié d'utiliser les partitions comme caractéristiques. Résultat : en partitionnant par année et par mois, j'ai en réalité perdu de l'information. Pour contourner le problème, ajoutez explicitement les colonnes de partition.
Étape 3 : entraîner un modèle
Enfin ! On arrive à la meilleure partie d'Amazon SageMaker.
Une fois les données explorées et les caractéristiques extraites, je peux ajuster un algorithme d'apprentissage aux données. Pour cette tâche, Amazon a implémenté sa propre version d'une dizaine d'algorithmes et de bibliothèques courants, dont Tensorflow, XGBoost et PyTorch. ET, si cela ne suffit pas, libre à vous d'implémenter votre propre algorithme et de l'exécuter dans SageMaker en le conteneurisant.
Pour ce type de données structurées comportant des millions d'enregistrements, ma préférence va naturellement à XGBoost. Grâce à son algorithme d'optimisation et à sa structure de données sous-jacente, XGBoost converge rapidement sur CPU tout en traitant plusieurs Go de données en RAM. Le réglage de ses paramètres peut s'avérer délicat, mais avec un peu d'expérience, on prend rapidement le bon départ : temps d'entraînement minimisé et surapprentissage évité. Pour des résultats optimaux, mieux vaut procéder à une optimisation des hyperparamètres — également couverte par SageMaker, mais pas dans cet article. :)
Pour terminer sur les raisons de mon choix, je rappellerai que les expériences menées sur de multiples datasets donnent d'excellents résultats avec XGBoost, proches de ceux des réseaux de neurones. C'est d'ailleurs pourquoi, sur ce type de données, on retrouve une implémentation de Gradient Boosting Machines dans toutes les solutions Kaggle gagnantes des dernières années.
Cela dit, en data science, la seule vérité, ce sont les chiffres. N'hésitez donc pas à expérimenter avec la bibliothèque de votre choix et partagez vos résultats dans les commentaires.
Pour lancer l'entraînement, deux objets principaux sont nécessaires :
- L'objet d'entrée S3 de SageMaker — qui pointe vers le csv partitionné train/val créé à l'étape 3. Notez que distribution='ShardedByS3Key' permet de répartir les datasets sur plusieurs machines, ce qui accélère considérablement l'entraînement, mais réduit aussi le nombre d'échantillons utilisés pour ajuster le modèle.
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- Un estimateur SageMaker, construit avec un conteneur XGBoost, une session SageMaker et un rôle IAM. Les paramètres permettent de définir le nombre et le type d'instances d'entraînement ; lorsque vous soumettez le job, SageMaker alloue les ressources conformément à votre demande.
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)Une fois l'instance du modèle créée, configurez-la avec un préréglage d'hyperparamètres, puis soumettez un job d'entraînement.
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})Croyez-le ou non, on en a (presque) terminé avec le code pour aujourd'hui. Direction la console SageMaker pour suivre le déroulement de l'entraînement. Vous pourrez admirer la charge CPU sur les instances allouées : XGBoost fait tourner votre processeur à près de 100 % de sa capacité pendant toute la phase d'entraînement.
Pour le reste de cet article, nous utiliserons la console SageMaker pour déployer le modèle et le rendre disponible pour l'inférence.
Étape 4 : évaluer le modèle
L'entraînement écrit le modèle dans le bucket S3 que nous avons défini. Pour générer des prédictions sur de nouvelles données, y compris notre ensemble de validation, il faut le " créer " en sélectionnant le job d'entraînement et en cliquant sur le bouton Create model dans le dashboard. En suivant les instructions à l'écran, l'opération est rapide.
Créez ensuite un job de batch transform et utilisez-le pour évaluer vos données de validation croisée. Ces données ne doivent pas contenir le champ cible (sérieusement, AWS… ?) : il vous faudra donc probablement transformer vos données À NOUVEAU pour le retirer.
Les résultats de la transformation par lot ont affiché une faible erreur, jugée — après de longues discussions avec la direction (rappelez-vous que vous travaillez pour Uber/Lyft) — suffisamment basse pour passer en production. À l'aide du regplot de seaborn, voici la distribution de l'erreur sur l'ensemble de validation croisée.
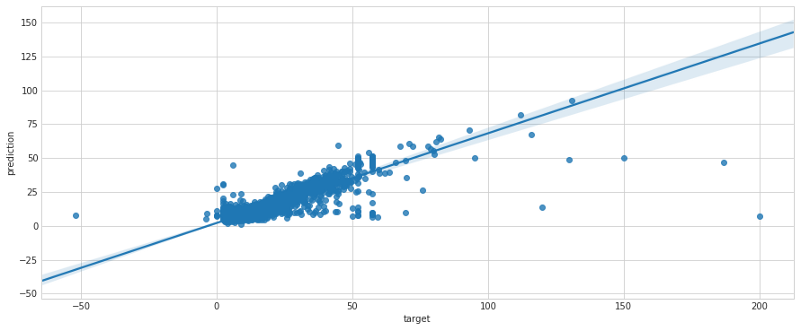
Étape 5 : déployer en production
Une fois le modèle évalué et la décision prise de l'exposer à notre système, il nous faut un moyen de générer des prédictions en ligne. Avec le modèle stocké dans SageMaker, construire un service de prédiction est on ne peut plus simple.
Voici deux façons d'invoquer le modèle :
- Via un client Python boto3 sur une EC2
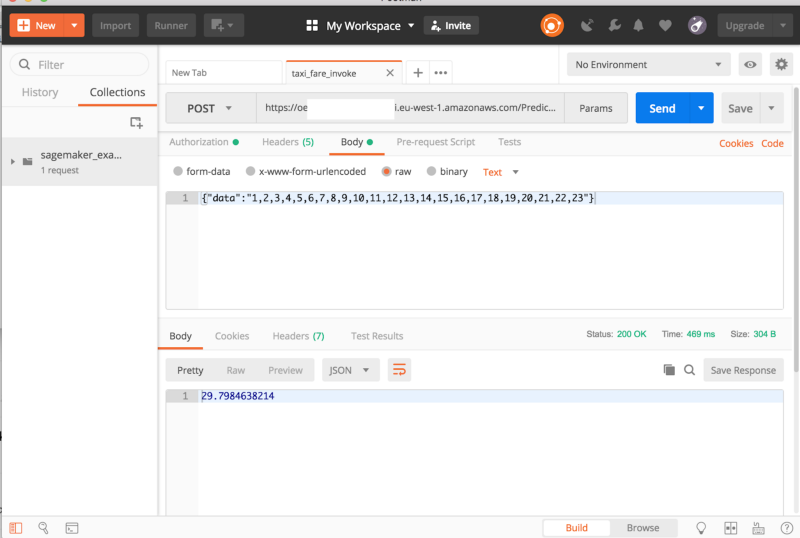
- Via des requêtes POST envoyées à une API
Les deux approches nécessitent de créer une configuration d'endpoint et un endpoint. C'est très simple, et une fois l'opération réalisée, on peut générer des prédictions avec le client Python boto3 comme ceci :
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)La seconde option consiste à passer par une requête POST. Pour exposer le modèle à des services externes, vous pouvez créer une API Gateway qui invoque une fonction Lambda. Pour en savoir plus, c'est ici.
En conclusion, AWS a développé un outil remarquable pour bâtir des pipelines de machine learning. SageMaker raccourcira votre time-to-market. Cela dit, AWS gagnerait à étoffer ses solutions de manipulation de données et à régler ce petit souci de partitions.
[1] https://aws.amazon.com/blogs/aws/sagemaker/
Envie d'en lire plus ? Découvrez notre blog, ou suivez Gad sur Twitter.