
TL;DR: o Amazon SageMaker oferece um jeito surpreendentemente simples de implementar pipelines de machine learning, encurtando bastante o time to market para cientistas e engenheiros de dados.
"foto de despertador digital preto" por John Cobb no Unsplash
A NYC Taxi and Limousine Commission publica informações detalhadas sobre as corridas de táxi na região metropolitana. Esses dados já foram tema de muitos projetos de data science e de várias competições no Kaggle. Neste tutorial, vou criar um serviço que prevê a tarifa de uma corrida com base na origem, no destino e no horário do embarque. Um serviço com função parecida provavelmente já existe na maioria das empresas de transporte por aplicativo, e a ideia geral pode ser aplicada a outros problemas de previsão geoespacial.
Imagine o seguinte: você trabalha como cientista de dados em uma das grandes empresas de transporte por aplicativo, como Uber ou Lyft. Sua missão é desenvolver um serviço de previsão que estime o preço esperado da corrida (definido por um taxímetro) a partir das seguintes features brutas: coordenadas de embarque e desembarque, data e hora do embarque e número de passageiros previstos a bordo.
Com machine learning, dá para construir um modelo de previsão preciso. Mas isso vai exigir grandes volumes de dados para o treinamento.
A estratégia para resolver esse problema envolve os 5 passos a seguir:
- Explorar os dados
- Construir um dataset
- Treinar um modelo
- Avaliar o modelo
- Colocar em produção (monitorar e refinar)
Essa estratégia pode ser usada por muitas empresas de software diante de problemas parecidos com os do Kaggle. Acontece que, embora dê para resolvê-los com um pipeline de machine learning padrão, pronto para uso, a maior parte das empresas com as quais converso gasta um tempão implementando sua própria versão desse pipeline tão padrão, jogando fora horas de desenvolvimento.
Se, por algum motivo, sua equipe está desenvolvendo esse tipo de serviço na AWS, pare tudo e leia este artigo, porque ele vai poupar semanas de código e várias iterações. Pode acreditar, eu já passei por isso!
Com o Amazon SageMaker, é relativamente simples e rápido desenvolver um pipeline completo de ML, com treinamento, deploy e geração de previsões. Anunciado em novembro de 2017, o Amazon SageMaker é um serviço totalmente gerenciado de machine learning de ponta a ponta que permite a cientistas de dados, desenvolvedores e especialistas em machine learning criar, treinar e hospedar modelos em escala com agilidade [1].
O código completo deste tutorial está disponível aqui:
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
Para este exercício, usei um dataset publicado aqui pelo Google, do qual extraí cerca de 50 milhões de registros (corridas) entre 2011 e 2015.
Passo 1: explore os dados
Como sempre, o primeiro passo na construção de um pipeline de machine learning é explorar o dataset. Para isso, a AWS oferece a ferramenta de notebooks do SageMaker, um servidor Jupyter Notebook padrão, já com todos os pacotes Python "canivete suíço" pré-instalados para cientistas de dados.
Depois de subir o dataset (arquivo csv compactado) para o bucket do S3, vamos lê-lo com o pandas. Como mencionei, o arquivo tem mais de 50 milhões de registros, o que torna o processamento em uma única máquina uma tarefa complicada. Além disso, carregar todos os dados na memória da máquina exige uma instância cara, com bastante disco e memória. Na minha opinião, para fins de exploração, usar uns 100 mil registros já basta neste caso. Trabalhar com esse volume gera estatísticas válidas e, ao mesmo tempo, permite consultar os dados com agilidade em uma máquina de custo relativamente baixo.
Um dos insights importantes que tirei da EDA rápida que fiz foi a importância das features de tempo. Como dá para ver, o preço por distância varia bastante conforme a hora do dia.
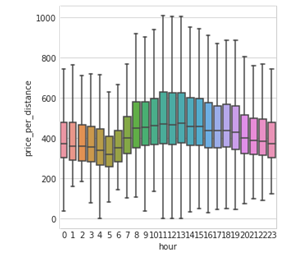 Tarifa por distância em função da hora do dia
Tarifa por distância em função da hora do dia
Outro insight teve a ver com o peso dos aeroportos no negócio dos táxis em Nova York. Ao gerar um scatter plot das coordenadas de embarque e desembarque, LaGuardia e JFK saltam aos olhos.
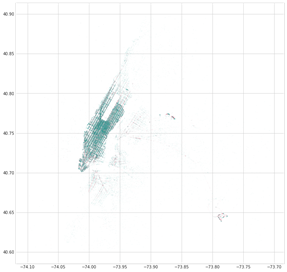 locais de embarque e desembarque
locais de embarque e desembarque
Esses insights aparecem com muita frequência nas análises dos dados de táxi de Nova York. Você encontra mais sobre o tema, com outros insights, na competição do Kaggle e neste post.
Passo 2: construa um dataset
A partir dos insights da etapa de exploração de dados, decidi extrair as seguintes features:
- Tempo sequencial/categórico: dia, dia da semana, mês, ano, dia do mês, hora, minuto
- Tempo cíclico: sin/cos das frequências diária e semanal
- Distância: distância geométrica
- Distância dos aeroportos: distância entre os pontos de embarque/desembarque e JFK, LaGuardia e Manhattan
- Features brutas — coordenadas e número de passageiros
Calcular essas features no dataset inteiro exige técnicas de computação e armazenamento distribuídos.
A AWS oferece várias ferramentas para lidar com grandes datasets em csv, com as quais dá para processar, consultar e exportar dados de forma bem prática. Usei o AWS S3 para armazenar o CSV bruto, o AWS Glue para particionar o arquivo e o AWS Athena para rodar consultas SQL na extração de features.
Para dividir o dataset entre treino e teste, considerei duas opções:
- Rodar duas consultas, usando uma cláusula WHERE para criar datasets diferentes para períodos diferentes; ou
- Rodar uma consulta para criar um dataset particionado e usar o comando s3 do AWS-cli para mover as partições para novos caminhos.
Em sistemas de produção, você certamente preferiria a primeira opção, mas, para este exercício, a segunda funcionou muito bem.
Observação: no código que transforma o csv particionado em libsvm, quem implementou o SageMaker esqueceu de usar as partições como features. Resultado: quando particionei por ano e mês, acabei perdendo informação. Para evitar isso, dá para contornar adicionando explicitamente as colunas de partição.
Passo 3: treine um modelo
Finalmente! Aqui vem a melhor parte do SageMaker da Amazon.
Depois de explorar os dados e extrair as features, posso começar a ajustar um algoritmo de aprendizado aos dados. Para essa tarefa, a Amazon implementou sua própria versão de dez algoritmos e bibliotecas comuns, incluindo Tensorflow, XGBoost e PyTorch. E, se isso não bastar, sempre dá para implementar seu próprio algoritmo no SageMaker via container.
Para esse tipo de dado estruturado, com milhões de registros, minha preferência natural é começar a modelagem com o XGBoost. Por causa do seu algoritmo de otimização e da estrutura de dados subjacente, o XGBoost converge rápido em CPUs, processando vários GBs de dados em RAM. O ajuste de parâmetros do XGBoost pode ser meio capcioso, mas, com experiência, você consegue um bom ponto de partida, reduzindo o tempo de treinamento e evitando overfitting. Para resultados mais precisos, recomenda-se algum tipo de otimização de hiperparâmetros, algo que o SageMaker também cobre, mas que não será abordado neste post. :)
Para fechar o argumento de por que escolhi o XGBoost, vale lembrar que experimentos em vários datasets mostram resultados muito bons com ele, próximos aos das redes neurais. Por isso, com esse tipo de dado, você sempre encontra alguma implementação de Gradient Boosting Machines em praticamente toda solução vencedora do Kaggle nos últimos anos.
Ainda assim, em data science não existe outra verdade além dos números. Então, fique à vontade para experimentar a biblioteca que preferir e nos conte como foi nos comentários abaixo.
Para realizar o treinamento, você vai precisar de 2 objetos principais:
- O objeto S3 input do SageMaker — apontando para o csv particionado de treino/validação que criamos no passo 3. Repare que usar distribution=’ShardedByS3Key’ permite distribuir os datasets entre várias máquinas, deixando o treinamento bem mais rápido, mas também reduzindo o número de amostras usadas para ajustar o modelo.
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- Um estimator do SageMaker, criado com um container do XGBoost, uma sessão do SageMaker e um IAM role. Por meio dos parâmetros, você define o número de instâncias de treinamento e o tipo de instância e, ao submeter o job, o SageMaker aloca os recursos conforme a sua solicitação.
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)Depois de criar a instância do modelo, configure-a com um conjunto pré-definido de hiperparâmetros e dispare um job de treinamento.
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})Agora, acredite se quiser, (quase) terminamos de programar por hoje. Vá até o console do SageMaker para acompanhar o processo de treinamento. Você pode aproveitar para ver a carga de CPU nas instâncias alocadas, já que o XGBoost coloca a CPU para trabalhar perto de 100% da capacidade durante o treinamento.
No restante deste post, vamos usar o console do SageMaker para fazer o deploy do modelo e disponibilizá-lo para previsões.
Passo 4: avalie o modelo
O treinamento gera o modelo em um bucket do S3 que definimos. Para gerar previsões em novos dados, incluindo nosso conjunto de validação, precisamos "criá-lo" selecionando o job de treinamento e clicando no botão "Create model" no dashboard. Seguindo as instruções na tela, é fácil concluir a tarefa.
Em seguida, crie um batch transform job e use-o para avaliar seus dados de cross-validation. Esses dados não devem conter o campo alvo (sério, AWS…?), então provavelmente você vai precisar transformar os dados DE NOVO para removê-lo.
Os resultados da batch transformation mostraram baixo erro que, depois de várias discussões com a gestão (lembre-se de que você trabalha na Uber/Lyft), foi considerado baixo o suficiente para ir para produção. Usando o regplot do seaborn, mostramos a distribuição do erro no conjunto de cross-validation.
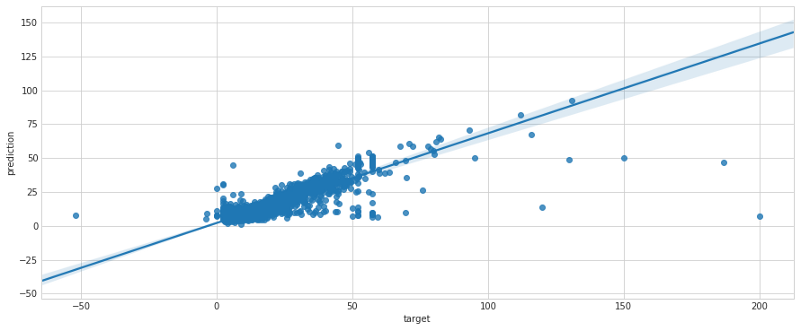
Passo 5: faça o deploy em produção
Depois de avaliar o modelo e decidir expô-lo ao nosso sistema, precisamos de um jeito de gerar previsões em tempo real. Com o modelo armazenado no SageMaker, criar um serviço de previsão é o mais simples possível.
Vou mostrar duas formas possíveis de invocar o modelo:
- Usando um cliente Python boto3 em uma EC2
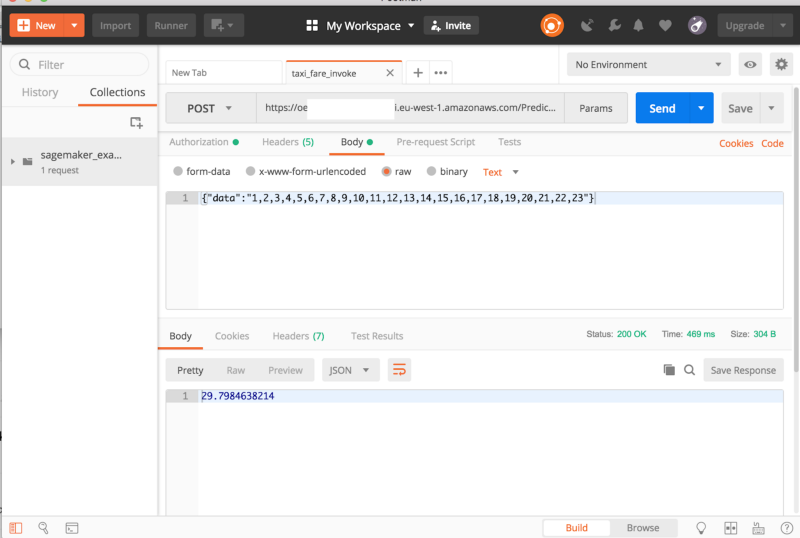
- Fazendo requisições POST para uma API
Os dois caminhos exigem a criação de uma configuração de endpoint e de um endpoint. É bem simples e, depois de pronto, dá para fazer previsões usando o cliente Python boto3 desta forma:
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)A segunda opção citada seria usar uma requisição POST. Para expor o modelo a serviços externos, você pode criar um API Gateway, que invoca uma função Lambda. Saiba mais aqui.
Para fechar, o time da AWS desenvolveu uma ferramenta incrível para construir pipelines de machine learning. Usar o SageMaker vai encurtar seu time-to-market. Ainda assim, seria ótimo se a AWS aprimorasse as soluções de manipulação de dados e resolvesse o pequeno problema com partições.
[1] https://aws.amazon.com/blogs/aws/sagemaker/
Quer mais conteúdos? Confira nosso blog ou siga o Gad no Twitter.