
TL;DR: Amazon SageMaker macht den Aufbau von Machine-Learning-Pipelines so einfach wie nie – und verkürzt die Time-to-Market für Data Scientists und Engineers deutlich.
"photo of black digital alarm" von John Cobb auf Unsplash
Die NYC Taxi and Limousine Commission veröffentlicht ausführliche Daten zu Taxifahrten im Großraum New York. Diese Daten waren bereits Grundlage zahlreicher Data-Science-Projekte und mehrerer Kaggle-Wettbewerbe. In diesem Tutorial baue ich einen Service, der den Fahrpreis anhand von Start, Ziel und Abholzeit vorhersagt. Einen vergleichbaren Service dürften die meisten Mobilitätsanbieter im Einsatz haben, und die Grundidee lässt sich auf weitere geospatiale Vorhersageprobleme übertragen.
Stellen Sie sich Folgendes vor: Sie arbeiten als Data Scientist für einen der großen Ride-Hailing-Anbieter, etwa Uber oder Lyft. Ihre Aufgabe ist es, einen Vorhersage-Service zu entwickeln, der den erwarteten Fahrpreis (sonst per Taxameter ermittelt) aus folgenden Rohdaten schätzt: Abhol- und Zielkoordinaten, Datum und Uhrzeit der Abholung sowie Anzahl der Fahrgäste.
Mit Machine Learning lässt sich ein präzises Vorhersagemodell entwickeln. Dafür sind allerdings große Datenmengen für das Training nötig.
Die Strategie zur Lösung umfasst die folgenden 5 Schritte:
- Daten erkunden
- Datensatz aufbauen
- Modell trainieren
- Modell evaluieren
- In Produktion bringen (überwachen und verfeinern)
Diese Strategie eignet sich für viele Softwareunternehmen, sobald sie auf ähnliche Kaggle-artige Probleme stoßen. Auch wenn solche Aufgaben mit einer Standard-ML-Pipeline von der Stange lösbar wären, beobachte ich bei den meisten Unternehmen, mit denen ich spreche, dass sie viel Zeit darauf verwenden, ihre eigene Variante dieser Standard-Pipeline zu bauen – und so unzählige Entwicklerstunden verbrennen.
Falls Ihr Team aus irgendeinem Grund einen solchen Service auf AWS entwickelt, sollten Sie unbedingt kurz innehalten und diesen Artikel lesen. Er erspart Ihnen Wochen an Coding und mehrere Iterationsrunden. Glauben Sie mir, ich war selbst in dieser Situation!
Mit Amazon SageMaker lässt sich eine vollständige ML-Pipeline – inklusive Training, Deployment und Vorhersage – vergleichsweise einfach und schnell entwickeln. Amazon SageMaker wurde im November 2017 angekündigt und ist ein vollständig verwalteter End-to-End-Machine-Learning-Service, mit dem Data Scientists, Entwickler und Machine-Learning-Experten Modelle skalierbar erstellen, trainieren und hosten können [1].
Den vollständigen Code zu diesem Tutorial finden Sie hier:
https://github.com/doitintl/ML-on-Cloud-Examples/blob/master/SageMaker/taxi_fare_prediction.ipynb
Für diese Übung habe ich einen Datensatz verwendet, den Google hier veröffentlicht hat, und daraus rund 50 Mio. Datensätze (Fahrten) zwischen 2011 und 2015 extrahiert.
Schritt 1: Daten erkunden
Wie immer beginnt der Aufbau einer Machine-Learning-Pipeline mit der Erkundung des Datensatzes. Dafür bietet AWS das Notebook-Tool von SageMaker an – ein klassischer Jupyter-Notebook-Server, auf dem alle gängigen Python-Pakete für Data Scientists vorinstalliert sind.
Nachdem ich den Datensatz (gezippte CSV-Datei) in einen S3-Storage-Bucket hochgeladen habe, lese ich ihn mit pandas ein. Wie erwähnt enthält die Datei über 50 Millionen Datensätze – für eine einzelne Maschine eine herausfordernde Aufgabe. Außerdem braucht es zum Laden aller Daten in den Hauptspeicher eine teure Instanz mit großem Festplatten- und Arbeitsspeicher. Für die Datenexploration reichen meines Erachtens in diesem Fall ~100K Datensätze aus. So entsteht einerseits eine valide Statistik, andererseits lassen sich die Daten auf einer vergleichsweise günstigen Maschine schnell abfragen.
Eine wichtige Erkenntnis aus der schnellen EDA: Zeit-Features spielen eine zentrale Rolle. Wie Sie sehen, schwankt der Preis pro Distanz je nach Tageszeit erheblich.
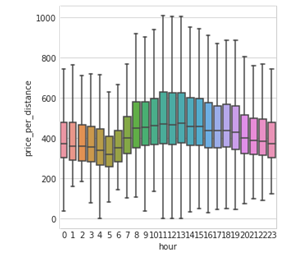 Fahrpreis pro Distanz nach Tageszeit
Fahrpreis pro Distanz nach Tageszeit
Eine zweite Erkenntnis betrifft den Anteil der Flughäfen am NYC-Taxigeschäft. Im Streudiagramm der Abhol- und Zielkoordinaten heben sich LaGuardia und JFK deutlich ab.
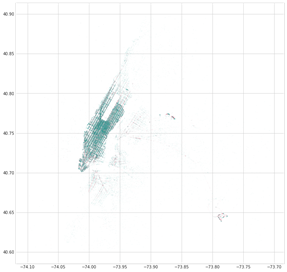 Abhol- und Zielorte
Abhol- und Zielorte
Diese Erkenntnisse tauchen bei Analysen der NYC-Taxidaten regelmäßig auf. Mehr dazu und weitere Insights finden Sie im Kaggle-Wettbewerb sowie in diesem Blogpost.
Schritt 2: Datensatz aufbauen
Auf Basis der Erkenntnisse aus der Datenexploration habe ich mich entschieden, folgende Features zu extrahieren:
- Sequenzielle/kategorische Zeit: Tag, Wochentag, Monat, Jahr, Tag des Monats, Stunde, Minute
- Zyklische Zeit: sin/cos der Tages- und Wochenfrequenz
- Distanz: geometrische Distanz
- Flughafendistanz: Distanz von Abhol- und Zielort zu JFK, LaGuardia und Manhattan
- Rohdaten – Koordinaten und Anzahl der Fahrgäste
Diese Features auf dem gesamten Datensatz zu berechnen, erfordert verteiltes Computing und Storage.
Amazon AWS bietet mehrere Tools für große CSV-Datensätze, mit denen sich Daten unkompliziert verarbeiten, abfragen und exportieren lassen. Ich habe AWS S3 zur Speicherung der Roh-CSV genutzt, AWS Glue zur Partitionierung der Datei und AWS Athena, um per SQL Features zu extrahieren.
Beim Aufteilen des Datensatzes in Trainings- und Testdaten hatte ich zwei Optionen im Kopf:
- Zwei Abfragen mit einer WHERE-Klausel, um Datensätze für unterschiedliche Zeiträume zu erzeugen, oder
- eine Abfrage, die einen partitionierten Datensatz erzeugt, kombiniert mit dem AWS-CLI-S3-Befehl, um einzelne Partitionen in neue Pfade zu verschieben.
In Produktivsystemen wäre Option 1 klar die bessere Wahl; für diese Übung hat Option 2 aber problemlos funktioniert.
Hinweis: Im Code, der partitioniertes CSV nach libsvm umwandelt, hat die SageMaker-Implementierung leider übersehen, die Partitionen als Features zu nutzen. Als ich nach Jahr und Monat partitioniert habe, gingen also Informationen verloren. Sie umgehen das, indem Sie die Partitionsspalten explizit ergänzen.
Schritt 3: Modell trainieren
Endlich! Jetzt kommt der beste Teil von Amazons SageMaker.
Nach Datenexploration und Feature-Extraktion kann ich beginnen, einen Lernalgorithmus an die Daten anzupassen. Dafür hat Amazon eigene Implementierungen von zehn gängigen Algorithmen und Bibliotheken bereitgestellt, darunter Tensorflow, XGBoost und PyTorch. UND falls das nicht reicht, lässt sich jederzeit ein eigener Algorithmus per Container in SageMaker einbinden.
Bei strukturierten Daten dieser Art mit Millionen von Datensätzen starte ich am liebsten mit XGBoost. Dank Optimierungsalgorithmus und zugrundeliegender Datenstruktur konvergiert XGBoost auf CPUs schnell und verarbeitet dabei mehrere GB Daten im RAM. Das Parameter-Tuning ist allerdings nicht trivial – mit etwas Erfahrung findet man aber einen guten Startpunkt, der die Trainingszeit minimiert und Overfitting vermeidet. Für maximale Genauigkeit empfiehlt sich eine Hyperparameter-Optimierung; SageMaker bietet das ebenfalls, ist aber nicht Thema dieses Beitrags. :)
Um die Wahl von XGBoost abzurunden: Experimente auf zahlreichen Datensätzen zeigen mit XGBoost sehr gute Ergebnisse, oft auf Augenhöhe mit neuronalen Netzen. Entsprechend findet sich bei dieser Art von Daten in nahezu jeder Kaggle-Siegerlösung der vergangenen Jahre irgendeine Implementierung von Gradient Boosting Machines.
Trotzdem: In Data Science zählen am Ende nur Zahlen. Probieren Sie also gern jede Bibliothek aus, die Ihnen zusagt, und teilen Sie uns in den Kommentaren mit, wie es lief.
Für das Training brauchen Sie 2 zentrale Objekte:
- Das S3-Input-Objekt von SageMaker – es zeigt auf das partitionierte CSV-Train/Val aus Schritt 3. Wichtig: Mit distribution='ShardedByS3Key' lassen sich die Datensätze über mehrere Maschinen verteilen, was das Training deutlich beschleunigt – allerdings auf Kosten der Anzahl der Samples, die zum Modell-Fitting genutzt werden.
s3_input_trains3_inpu = sagemaker.s3_input(s3_data='s3://{}/{}'.format(bucket, path_train), content_type='csv',distribution='ShardedByS3Key')- Einen SageMaker-Estimator – aufgebaut mit XGBoost-Container, SageMaker-Session und IAM-Rolle. Über Parameter legen Sie die Anzahl der Trainings-Instanzen und den Instanztyp fest; sobald Sie den Job einreichen, weist SageMaker die Ressourcen entsprechend zu.
container = get_image_uri(boto3.Session().region_name, 'xgboost') sess = sagemaker.Session() role = get_execution_role()xgb = sagemaker.estimator.Estimator(container, role, train_instance_count=4, train_instance_type= 'ml.m4.xlarge', output_path=output_path, sagemaker_session=sess)Sobald die Modellinstanz steht, konfigurieren Sie sie mit einem Set an Hyperparametern und reichen einen Trainingsjob ein.
xgb.set_hyperparameters(max_depth=9, eta=0.2, gamma=4, min_child_weight=300, subsample=0.8, silent=0, objective='reg:linear', early_stopping_rounds=10, num_round=10000)xgb.fit({'train': s3_input_trains3_inpu, 'validation': s3_input_validation})Und – ob Sie es glauben oder nicht – damit ist das Coden für heute (fast) erledigt. Wechseln Sie in die SageMaker-Konsole, um den Trainingsverlauf zu verfolgen. Sie können dabei zusehen, wie XGBoost Ihre CPUs während des Trainings auf nahezu 100 % auslastet.
Im weiteren Verlauf nutzen wir die SageMaker-Konsole, um das Modell zu deployen und für Vorhersagen verfügbar zu machen.
Schritt 4: Modell evaluieren
Das Training schreibt das Modell in den S3-Bucket, den wir definiert haben. Um Vorhersagen für neue Daten – inklusive unseres Validierungssets – zu erzeugen, müssen wir das Modell zunächst "erstellen": Trainingsjob auswählen und im Dashboard auf "Create model" klicken. Mit den Anweisungen auf dem Bildschirm ist das schnell erledigt.
Legen Sie als Nächstes einen Batch-Transform-Job an und werten Sie damit Ihre Cross-Validation-Daten aus. Diese Daten dürfen das Zielfeld nicht enthalten (im Ernst, AWS …?), Sie müssen Ihre Daten also vermutlich ERNEUT transformieren, um es zu entfernen.
Das Ergebnis der Batch-Transformation wies einen niedrigen Fehler aus, der nach längeren Diskussionen mit dem Management (denken Sie daran: Sie arbeiten für Uber/Lyft) als gering genug eingestuft wurde, um in Produktion zu gehen. Mit seaborns regplot zeigen wir die Fehlerverteilung auf dem Cross-Validation-Set.
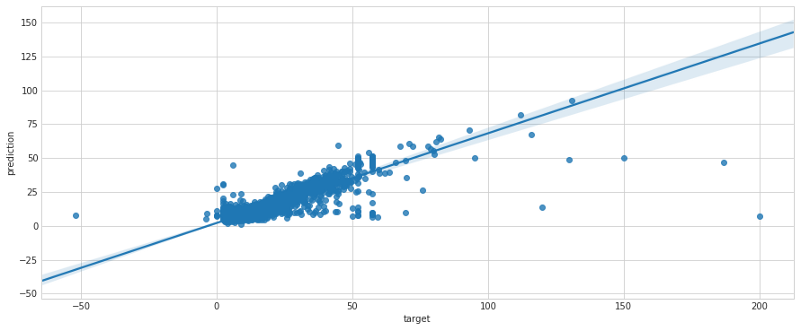
Schritt 5: In Produktion bringen
Nachdem wir das Modell evaluiert und beschlossen haben, es in unserem System bereitzustellen, brauchen wir einen Weg, Online-Vorhersagen zu erzeugen. Da das Modell bereits in SageMaker liegt, ist der Aufbau eines Vorhersage-Service denkbar einfach.
Im Folgenden zeige ich zwei Möglichkeiten, das Modell aufzurufen:
- Über einen Python-boto3-Client auf einer EC2-Instanz
- Über POST-Requests an eine API
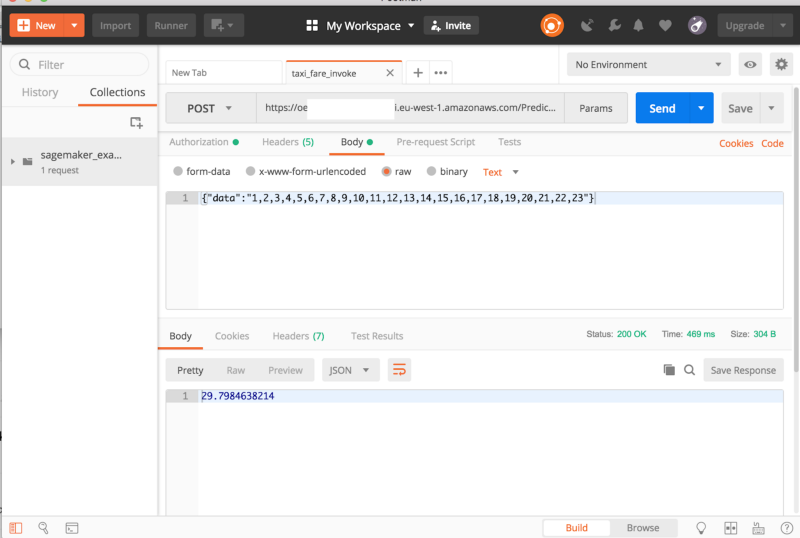
Beide Wege setzen eine Endpoint-Konfiguration und einen Endpoint voraus. Das ist schnell erledigt – danach lassen sich mit dem boto3-Python-Client wie folgt Vorhersagen abrufen:
endpoint_name = 'taxi-fare-prediction'content_type = 'text/csv'
runtime = boto3.Session().client('sagemaker-runtime')response = runtime.invoke_endpoint(EndpointName=endpoint_name,\ ContentType='text/csv',\ Body=data)results = list(ast.literal_eval(response['Body'].read().decode()))print(results)Die zweite Option wäre ein POST-Request. Um den Service externen Diensten zugänglich zu machen, können Sie ein API Gateway aufsetzen, das eine Lambda-Funktion aufruft. Mehr dazu lesen Sie hier.
Fazit: AWS hat ein hervorragendes Tool für den Aufbau von Machine-Learning-Pipelines geschaffen. SageMaker verkürzt Ihre Time-to-Market spürbar. Wünschenswert wäre allerdings, dass AWS bei der Datenmanipulation nachlegt und das kleine Partitionen-Thema behebt.
[1] https://aws.amazon.com/blogs/aws/sagemaker/
Lust auf mehr Beiträge? Schauen Sie in unseren Blog oder folgen Sie Gad auf Twitter.