以前の 記事 では、Cloud Composer(マネージドのApache Airflow)でコンテナを実行する方法を紹介しました。その後Googleは、大幅にアップグレードされたAirflow 2.0を採用したComposerのプレビュー版を公開しました。多くの不具合が解消され、開発体験もよりPythonらしい書き方に近づいています。

現在のComposerはAirflow 2.0.1に対応しています。本記事はこのバージョンを前提に書かれている点にご留意ください。
本記事で扱うAirflow 2.0系のコードについては、これまで大きな破壊的変更はありません。ただしAirflow 1.0で経験したように、今後の新バージョンで状況が一変する可能性は十分にあります。1年後などに最新バージョンで本コードを参照される場合は、この点を念頭に置いてください。
本記事は2部構成です。前半ではコードの観点からAirflow 1.0と2.0の基本的な違い、特に後半のコードで使う部分を取り上げます。後半では、新しく作成したGKEクラスタでコンテナを実行する方法を示し、前回記事のコードベースをAirflow 2.0向けに更新したものを改めて見ていきます。
Pythonらしく書くか、「Airflow流に書く」か
Airflow 2.0の最大の変化のひとつが、DAGをよりシンプルに記述できるようになり、コードの可読性が大きく向上した点です。この変更は、Airflowに精通していない開発者からも好評を得ています。
たとえばAirflow 2.0でDAGを定義するには、次のように書きます。
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
これをAirflow 1.0の定義と比べてみましょう。
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Python開発者なら、このコードがすんなり読めるはずです。DAGが関数として表現されるため、テストフレームワークでも簡単にラップできます。さらに、タスク間でのデータの受け渡しもシンプルになりました。Airflow 1.0では、bashスクリプトタスクの出力を別のタスクで利用するために、XComsを使った込み入った回避策が必要でした。次のコードをご覧ください。
# メッセージをechoしてxcomにpushするオペレータ
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# provide_context=Trueを指定した別のPythonOperator内
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
一方、Airflow 2.0では同じ処理がぐっと素直になります。
# 出力を `output` 変数に代入し、DAG内で後ほど利用できる
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
新しいコードのほうが格段にすっきりしており、bashコマンドの出力を取り出しやすくなっているのは一目瞭然です。
Airflow 1.0と2.0でのGKE操作
前回の記事では、 KubernetesPodOperator を使ってGKEクラスタ内でコンテナを実行しました。これでも問題なく動作しましたが、Airflow 2.0ではより良い結果を得るための新しいやり方が用意されています。Airflow 1.0の汎用的なKubernetesオペレータとは別に、Googleが新たにGKEクラスタ専用のオペレータ群を提供したのです。
今回使うのは、 GKECreateClusterOperator 、 GKEStartPodOperator 、 GKEDeleteClusterOperator の3つです。名前のとおり、それぞれGKEクラスタの作成、Podの起動、GKEクラスタの削除を担当します。それでは、シンプルなAirflow 2.0のDAGを通じて、これらの動きを実際に見ていきましょう。
Airflow 2.0のGKE DAGサンプル
本記事の以降で参照するGitHubリポジトリは こちら です。 本セクションでは new_cluster_gke_pod.py ファイルを取り上げます。
このDAGはとてもシンプルで、3つの操作を実行します。GKEクラスタの作成、GKEクラスタ上でのダミー処理のPod実行、そしてGKEクラスタの削除です。Airflow 2.0のDAG構造を旧スタイルと比較するうえで分かりやすい例になっています。Airflow 1.0のドメイン固有言語的な書き方とは違い、コードがPythonスクリプトに近い構造になっていることがすぐに見て取れるはずです。
この方式は、必要な間だけ「生きている」一時的なGKEクラスタで処理を実行したい場合に非常に有用です。Kubernetesクラスタのパワーは必要だが、完了後にリソースを残す必要がないアドホックな処理にも適しています。
料金面でのワンポイントです。本番環境でこの方式を採用するなら、n2dインスタンスタイプのように、すでに割引が適用済みで継続利用割引の対象外となるコンピュートインスタンスタイプの利用をおすすめします。これらは短時間で終了するため、 継続利用割引 を受けられないからです。最初から割引が適用されたインスタンスタイプを選んでおけば、長期的にコストを抑えられます。
旧DAGをAirflow 2.0向けに作り直す
前回の記事では、Composer内のGKEクラスタに新しいノードプールを作成し、DAGの中でPodをスケジュールする方法を紹介しました。この処理は比較的容易で、わずかな手順で完了するものでした。新しい技術が登場すると、既存のコードをパフォーマンスを落とさず動かすために、変更や修正が必要になることがあります。
今回がまさにそのケースでした。Airflow 2.0で動かすためにコードを修正する必要がありましたが、結果的にこれは怪我の功名でした。既存のDAGに KISS(Keep It Simple Stupid)原則 を適用し、各処理をよりシンプルな個別ステップに分解する良い機会になったのです。これにより、各ステップの目的が明確になり、コードの読みやすさと追いやすさが大幅に向上しました。
使用済みのAirflow変数を削除する、新しいクリーンアップ処理を追加した点にもご注目ください。
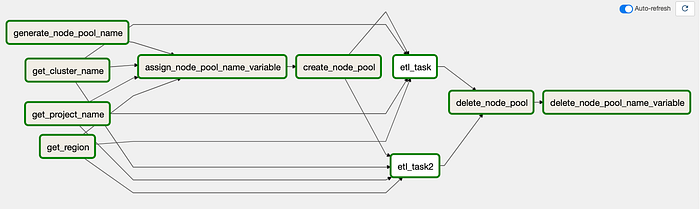
Airflow 2.0で可視化した旧DAG
一見すると、このDAGには以前よりかなり多くのタスクと矢印があることに気づくはずです。Airflow的というよりPythonコードに近い書き方になっているため、環境から値を取得してPython変数として保持するためのタスクがいくつか必要になっています。
続ける前にひとつだけ愚痴を言わせてください。Airflow 2.0の可視化は最初は分かりにくく感じるかもしれません。実行時にUI上でフローを視覚的に追いづらくなるようなグループ化が行われがちだからです。先ほどのスクリーンショットを見ても、矢印が入り組んでいて少々ごちゃついて見えます。
これを整理して混乱を解消するため、実行フローを定義しているPythonコード部分を以下に示します(角括弧内の項目は並列実行されます)。
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
最初のタスク群は、実行に必要な値をComposer環境から取り出し、続いてノードプール名をAirflow変数に割り当てます。前回の記事ではこれらをすべて1つのBashOperatorにまとめていましたが、分かりやすさのために分割しました。
次に、ノードプールを作成し、2つのダミーETLタスクを並列で実行し、完了後にノードプールを削除します。最後に、ノードプール名を保持していたAirflow変数を削除します。これがクリーンアップとして新たに追加したステップです。本来、前回の記事でも行っておくべき手順でした。ワークフロー自体は以前と同じで、ステップがより細かく分かれているだけです。
2つのアプローチの比較
これら2つのアプローチは、いずれもGKEクラスタ上でコンテナをスケジュール実行するという同じ目的を果たし、料金面の差もごくわずかです。 GKEの料金体系は こちら でご確認いただけます。
どちらが優れているかに明確な答えはなく、ユースケースや環境次第です。一般的には、workloadsを動かしている既存のGKEクラスタがないなら、Airflowクラスタ上のノードプールを使うのがよいでしょう。一方、追加負荷を受け止められるGKEクラスタですでに他のworkloadsを動かしているなら、そのクラスタ上でスケジュールするのがベストです。
ETLタスクは一般にリソース消費が大きい点にご注意ください。既存のGKEクラスタで実行する場合は、ノードのインスタンスタイプが追加のリソース使用量に十分対応できるかを確認してください。念のためオートスケーリングを有効にしておくのも良い選択です。
既存のGKEクラスタに別のノードプールを作成し、その上でスケジュールするというハイブリッド方式も有力な選択肢となります。
Airflow 2.0でこれから進めていく
Airflow 2.0が世界中で使われ始めた今、Googleは既存ドキュメントの多くを順次移行し、すべてのAirflow workloadsのデフォルト選択肢として2.0を推奨するようになると見ています。既存のAirflow 1.0 workloadsの移行を始めること、そして新規workloadsはすべてAirflow 2.0で構築することを強くおすすめします。
Airflow 2.0ならDAGをシンプルに書けるため、コードはよりクリーンで読みやすくなります。長期的なメンテナンス性も向上するはずです。元開発者として太鼓判を押します。あなたの開発チームもきっと喜ぶはずです。
多くの用途でworkloadsのコンテナ化が進んでいる現状を踏まえれば、GKEでworkloadsをスケジュールするには、ここで紹介した2つのアプローチのいずれかを強くおすすめします。前回の記事で取り上げた、workloadsのスケジューリングと要件のバランスをめぐる多くの悩みを回避できるはずです。
Kubernetesはコンテナworkloadsのデファクトスタンダードです。Google自身が生み出し、ありがたいことにGKEをデファクトのマネージドKubernetesサービスとして提供し続けてくれているのですから、これを最大限に活用するのが最も理にかなった選択です。最良の成果を得るためにも、workloadsはできる限り効率的に保ちましょう。
お読みいただきありがとうございました。 今後も DoiT Engineering Blog 、 DoiT LinkedInチャンネル 、 DoiT Twitterチャンネル でぜひつながってください。採用情報については https://careers.doit-intl.com をご覧ください。