In meinem vorherigen Artikel habe ich gezeigt, wie sich Container mit Cloud Composer (dem managed Apache Airflow für alle, die es noch nicht kennen) ausführen lassen. Seither hat Google einen Preview-Build von Composer veröffentlicht, der auf Airflow 2.0 setzt – ein großes Upgrade. Es behebt zahlreiche Probleme und macht die Entwicklung gleichzeitig deutlich näher an klassischem Python.

Composer unterstützt aktuell Airflow 2.0.1. Bitte beachten Sie daher, dass dieser Artikel genau auf diese Version zugeschnitten ist.
In dem Code aus der Airflow-2.0-Reihe, den ich hier verwende, gab es bislang keine bahnbrechenden Änderungen. Doch wie wir bei Airflow 1.0 gelernt haben, kann sich das mit künftigen Versionen sehr schnell ändern. Behalten Sie das also im Hinterkopf, falls Sie diesen Code in einem Jahr oder später mit der dann aktuellen Version verwenden.
Der Artikel besteht aus zwei Abschnitten. Im ersten gehe ich aus Code-Sicht auf einige grundlegende Unterschiede zwischen Airflow 1.0 und 2.0 ein – konkret auf das, was ich für den zweiten Teil im Code nutze. Im zweiten Abschnitt zeige ich, wie sich Container auf einem neu erstellten GKE-Cluster ausführen lassen, und werfe anschließend einen frischen Blick auf die Codebasis aus meinem vorherigen Artikel, die ich für Airflow 2.0 aktualisiert habe.
Python-Dateien schreiben vs. "in Airflow schreiben"
Zu den größten Neuerungen in Airflow 2.0 zählt, dass sich DAGs deutlich einfacher schreiben lassen, was den Code lesbarer macht. Vor allem Engineers, die keine Airflow-Profis sind, wissen das zu schätzen.
So definieren Sie zum Beispiel einen DAG in Airflow 2.0:
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
Zum Vergleich die Definition in Airflow 1.0:
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Python-Entwickler können diesen Code nun problemlos lesen. Der DAG wird zu einer Funktion, die sich leicht in Test-Frameworks einbinden lässt. Hinzu kommt die einfache Datenübergabe zwischen Tasks. In Airflow 1.0 mussten Sie XComs nutzen und einige umständliche Workarounds bauen, um den Output eines Bash-Skript-Tasks an einen anderen weiterzureichen. Sehen Sie sich diesen Code an:
# Operator, der eine Nachricht ausgibt und an xcom pusht
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# innerhalb eines weiteren PythonOperator mit provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
Mit Airflow 2.0 ist derselbe Code deutlich übersichtlicher:
# weist den Output der Variable `output` zu, die später im DAG genutzt werden kann
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
Klar erkennbar: Der neue Code ist deutlich sauberer und macht es Entwicklern leichter, an den Output dieses Bash-Befehls zu kommen.
GKE-Operationen in Airflow 1.0 vs. 2.0
In meinem vorherigen Artikel habe ich KubernetesPodOperator verwendet, um einen Container in einem GKE-Cluster auszuführen. Das funktionierte einwandfrei, doch Airflow 2.0 bietet inzwischen einen anderen Weg, der bessere Ergebnisse liefert. Google hat eine Reihe von Operatoren bereitgestellt, die speziell mit GKE-Clustern interagieren – im Gegensatz zu den allgemeineren Kubernetes-Operatoren in Airflow 1.0.
Die drei Operatoren, die ich nun verwende, sind GKECreateClusterOperator, GKEStartPodOperator und GKEDeleteClusterOperator. Die Namen sind selbsterklärend: Sie erstellen einen GKE-Cluster, starten einen Pod bzw. löschen einen GKE-Cluster. Schauen wir sie uns nun anhand eines sehr einfachen Airflow-2.0-DAGs in Aktion an, um das Zusammenspiel zu verstehen.
Beispiel: Airflow-2.0-GKE-DAG
Das GitHub-Repository, auf das ich mich im weiteren Verlauf beziehe, finden Sie hier. In diesem Abschnitt beziehe ich mich auf die Datei new_cluster_gke_pod.py.
Es handelt sich um einen sehr einfachen DAG mit drei Operationen: Er erstellt einen GKE-Cluster, lässt einen Dummy-Prozess als Pod auf dem GKE-Cluster laufen und löscht den GKE-Cluster anschließend wieder. So lässt sich der Aufbau eines Airflow-2.0-DAGs gegenüber dem alten Stil sehr gut veranschaulichen. Sie werden schnell merken, dass der Code wie ein Python-Skript aufgebaut ist und nicht wie die domänenspezifische Sprache von Airflow 1.0.
Das ist besonders praktisch für Prozesse auf einem transienten GKE-Cluster – also einem Cluster, der nur so lange "lebt", wie er gebraucht wird. Auch für Ad-hoc-Prozesse, die zwar die Power eines Kubernetes-Clusters benötigen, danach aber keine Ressourcen mehr brauchen, eignet sich dieser Ansatz hervorragend.
Ein kurzer Hinweis zu den Kosten: Wenn Sie diese Methode produktiv einsetzen, empfehle ich einen Compute-Instanztyp, der bereits rabattiert ist und für den ohnehin keine Sustained-Use-Discounts greifen, etwa die n2d-Instanztypen. Der Grund: Es handelt sich um kurzlebige Instanzen, die keinen Sustained-Use-Discount erhalten. Wenn Sie also einen Instanztyp mit bereits angewendetem Rabatt verwenden, sparen Sie auf lange Sicht Geld.
Der alte DAG, neu gedacht für Airflow 2.0
In meinem vorherigen Artikel habe ich gezeigt, wie sich auf einem GKE-Cluster in Composer ein neuer Node Pool anlegen und ein Pod innerhalb eines DAGs einplanen lässt. Das war relativ einfach umzusetzen und erforderte nur wenige Schritte. Eine Schattenseite neuer Technologie ist allerdings, dass bestehender Code mitunter angepasst werden muss, um weiterhin zuverlässig zu funktionieren – ohne Performance-Einbußen.
Genau das war hier der Fall. Ich musste den Code an Airflow 2.0 anpassen – und das erwies sich als Glücksfall. Es zwang mich nämlich auch dazu, das KISS-Prinzip (Keep It Simple Stupid) auf den bestehenden DAG anzuwenden und die Operationen in einfachere Einzelschritte zu zerlegen. Dadurch ist er deutlich leichter zu lesen und nachzuvollziehen, weil jeder Schritt einzeln aufgeschlüsselt ist und sein Kernzweck klar wird.
Sie werden außerdem feststellen, dass ich aktualisierten Cleanup-Code eingebaut habe, der genutzte Airflow-Variablen wieder entfernt.
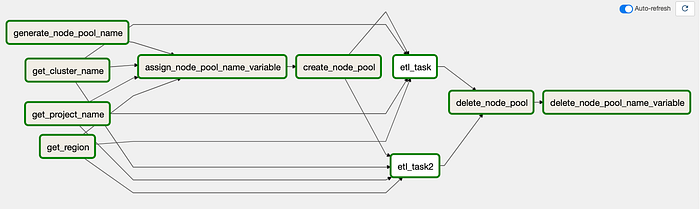
DAG-Visualisierung des alten DAGs in Airflow 2.0
Auf den ersten Blick fällt auf, dass dieser DAG deutlich mehr Tasks und Pfeile enthält. Da er eher Python-Code als klassischem Airflow ähnelt, sind einige Tasks nötig, um Werte aus der Umgebung zu holen und als Python-Variablen abzulegen.
Ein kleiner Kritikpunkt vorab: Die Visualisierung in Airflow 2.0 kann anfangs verwirren, weil sie Elemente so gruppiert, dass der Ablauf in der Oberfläche zur Laufzeit visuell schwer zu verfolgen ist. Wie der Screenshot oben zeigt, wirkt mit den vielen Pfeilen alles etwas unübersichtlich.
Zur Klarstellung hier der Task aus meinem Python-Code, der den Ausführungsablauf definiert (Einträge in Klammern werden parallel ausgeführt):
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
Die ersten Tasks holen lediglich Werte aus der Composer-Umgebung, die für die Ausführung benötigt werden, und weisen anschließend den Node-Pool-Namen einer Airflow-Variable zu. Im vorherigen Artikel waren all diese Schritte in einem einzigen BashOperator gebündelt – ich habe sie hier zur Vereinfachung aufgeteilt.
Anschließend wird der Node Pool erstellt, die beiden Dummy-ETL-Tasks laufen parallel, danach wird der Node Pool gelöscht und zuletzt die Airflow-Variable mit dem Node-Pool-Namen entfernt – ein neuer Schritt zur Bereinigung. Den hätte ich eigentlich schon im vorherigen Artikel ergänzen sollen. Es ist derselbe Workflow wie zuvor, nur etwas granularer.
Vergleich der Ansätze
Beide Ansätze führen dieselbe Operation aus – das Einplanen von Containern auf einem GKE-Cluster – und unterscheiden sich preislich nur minimal. Die GKE-Preise finden Sie hier.
Welche Variante besser ist, lässt sich nicht pauschal beantworten – das hängt von Ihrem Anwendungsfall und Ihrer Umgebung ab. Generell gilt: Wenn Sie noch keinen GKE-Cluster mit laufenden workloads haben, kann ein Node Pool auf dem Airflow-Cluster die richtige Wahl sein. Falls Sie bereits andere workloads auf einem GKE-Cluster betreiben, der die zusätzliche Last verkraftet, planen Sie die Tasks besser auf diesem Cluster ein.
Bitte beachten Sie, dass ETL-Tasks generell sehr ressourcenintensiv sind. Wenn Sie sie auf einem bestehenden GKE-Cluster ausführen, stellen Sie sicher, dass die Node-Instanztypen groß genug sind, um die zusätzliche Ressourcenlast zu stemmen. Es kann außerdem sinnvoll sein, Autoscaling zu aktivieren, um auf der sicheren Seite zu sein.
Ein hybrider Ansatz – also das Anlegen eines separaten Node Pools auf einem bestehenden GKE-Cluster und das Einplanen darauf – kann hier der Königsweg sein.
Mit Airflow 2.0 in die Zukunft
Da Airflow 2.0 inzwischen weltweit im Einsatz ist, gehe ich fest davon aus, dass Google damit beginnen wird, den Großteil der bestehenden Dokumentation umzustellen und Airflow 2.0 als Standardoption für alle Airflow-workloads zu empfehlen. Ich rate dringend dazu, bestehende Airflow-1.0-workloads zu migrieren und alle neuen workloads direkt auf Airflow 2.0 aufzubauen.
Das Schreiben von DAGs ist in Airflow 2.0 schlanker und lesbarer. Das macht die Wartung langfristig einfacher. Glauben Sie mir, Ihre Entwickler werden es zu schätzen wissen – das sage ich als ehemaliger Entwickler!
Da sich die Welt für die meisten Anwendungsfälle in Richtung containerisierter workloads bewegt, empfehle ich dringend, einen der beiden oben beschriebenen Ansätze für die Planung von workloads auf GKE zu nutzen. Das erspart Ihnen viele Probleme, wie ich in meinem letzten Artikel zur Planung und zum Ausbalancieren der Anforderungen Ihrer workloads gezeigt habe.
Kubernetes ist der De-facto-Standard für Container-workloads. Da Google es erfunden hat und seinen GKE-Service zum Glück als De-facto-Managed-Kubernetes-Service pflegt, ist es nur logisch, das zu nutzen, was es besonders gut kann. Halten Sie Ihre workloads so effizient wie möglich – das bringt die besten Ergebnisse.
Vielen Dank fürs Lesen! Bleiben Sie mit uns in Kontakt – über den DoiT Engineering Blog, den DoiT LinkedIn-Kanal und den DoiT Twitter-Kanal. Karrieremöglichkeiten finden Sie unter https://careers.doit-intl.com.