Dans mon précédent article, je vous ai montré comment exécuter des conteneurs avec Cloud Composer (la version managée d'Apache Airflow, pour les non-initiés). Depuis la publication de cet article, Google a mis à disposition une preview de Composer qui s'appuie sur Airflow 2.0, une mise à jour majeure. Elle corrige de nombreux problèmes et rapproche le développement de l'écriture classique en Python.

Composer prend actuellement en charge Airflow 2.0.1. Cet article a donc été rédigé en tenant compte de cette version précise.
Il n'y a pas eu de bouleversements dans le code de la série Airflow 2.0 que j'ai utilisé pour cet article. Mais comme nous l'avons constaté avec Airflow 1.0, les choses peuvent évoluer très vite avec les nouvelles versions à venir. Gardez-le à l'esprit si vous reprenez ce code dans un an ou deux avec la dernière version en date.
Cet article se compose de deux parties. La première aborde quelques différences fondamentales entre Airflow 1.0 et 2.0 du point de vue du code, en particulier celles qui interviennent dans mon code de la seconde partie. La seconde montre comment exécuter des conteneurs sur un cluster GKE nouvellement créé, puis revient sur le code de mon précédent article, mis à jour pour Airflow 2.0.
Écrire des fichiers Python plutôt qu'" écrire en Airflow "
Parmi les changements les plus marquants d'Airflow 2.0 figure la possibilité d'écrire un DAG plus simplement, ce qui rend le code plus lisible. Ces évolutions sont particulièrement appréciées des développeurs qui ne sont pas des experts d'Airflow.
Par exemple, voici ce qu'il faut écrire pour définir un DAG dans Airflow 2.0 :
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
À comparer avec la définition en Airflow 1.0 :
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Les développeurs Python peuvent désormais lire ce code sans difficulté : le DAG devient une fonction qui s'encapsule facilement dans des frameworks de test. Le passage de données entre tâches est lui aussi simplifié. Avec l'ancien Airflow 1.0, il fallait recourir aux XComs et bricoler des contournements complexes pour récupérer la sortie d'une tâche bash dans une autre. Voyez plutôt :
# operator that echoes out a message and pushes it to xcom
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# inside another PythonOperator where provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
Avec Airflow 2.0, le même code devient bien plus direct :
# assigns output to the `output` variable for use later in the DAG
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
Le nouveau code est nettement plus propre, et le développeur récupère bien plus simplement la sortie de cette commande bash.
Opérations GKE : Airflow 1.0 vs 2.0
Dans mon précédent article, j'utilisais KubernetesPodOperator pour exécuter un conteneur au sein d'un cluster GKE. Cela fonctionnait très bien, mais Airflow 2.0 propose désormais une autre façon de procéder, avec de meilleurs résultats à la clé. Google a créé un ensemble d'opérateurs dédiés à l'interaction avec les clusters GKE, là où Airflow 1.0 ne proposait que des opérateurs Kubernetes plus génériques.
Les trois opérateurs que je vais utiliser sont GKECreateClusterOperator, GKEStartPodOperator et GKEDeleteClusterOperator. Leur nom est assez explicite : ils créent un cluster GKE, démarrent un pod et suppriment un cluster GKE, respectivement. Voyons-les à l'œuvre dans un DAG Airflow 2.0 très simple pour en comprendre la mécanique.
Exemple de DAG GKE en Airflow 2.0
Le dépôt GitHub que je référence dans la suite de cet article se trouve ici. Je m'appuie sur le fichier new_cluster_gke_pod.py dans cette section.
Ce DAG très simple effectue 3 opérations : il crée un cluster GKE, exécute un processus factice sous forme de pod sur ce cluster, puis supprime le cluster GKE. Une bonne occasion d'illustrer la structure d'un DAG Airflow 2.0 face à l'ancien style. Vous remarquerez vite que le code est structuré comme un script Python, à l'opposé du langage spécifique au domaine d'Airflow 1.0.
Cette approche se révèle très utile pour exécuter des processus sur un cluster GKE éphémère, c'est-à-dire qui ne " vit " que le temps nécessaire. C'est aussi un excellent moyen de lancer des traitements ad hoc qui exigent la puissance d'un cluster Kubernetes, mais n'ont besoin d'aucune ressource une fois terminés.
Petit conseil tarifaire au passage. Si vous utilisez cette méthode en production, je recommande d'opter pour un type d'instance de calcul déjà remisé et non éligible à la remise pour utilisation prolongée, comme les instances n2d. Comme il s'agit d'instances de courte durée, elles ne bénéficieront d'aucune remise pour utilisation prolongée. En choisissant un type d'instance déjà remisé, vous économiserez sur la durée.
L'ancien DAG repensé pour Airflow 2.0
Dans mon précédent article, je montrais comment créer un nouveau pool de nœuds sur un cluster GKE dans Composer et planifier un pod au sein d'un DAG. Le processus était relativement simple et ne demandait que quelques étapes. L'inconvénient d'une nouvelle technologie, c'est qu'il faut parfois revoir et adapter le code existant pour qu'il fonctionne correctement sans nuire aux performances.
C'est précisément le cas ici. J'ai dû modifier le code pour le rendre compatible avec Airflow 2.0, mais ce fut un mal pour un bien. Cela m'a aussi poussé à appliquer le principe KISS (Keep It Simple Stupid) au DAG existant et à découper les opérations en étapes individuelles plus simples. Le résultat est bien plus facile à lire et à suivre, chaque étape étant isolée et son rôle clairement identifiable.
Vous remarquerez aussi que j'ai ajouté du code de nettoyage pour supprimer les variables Airflow utilisées.
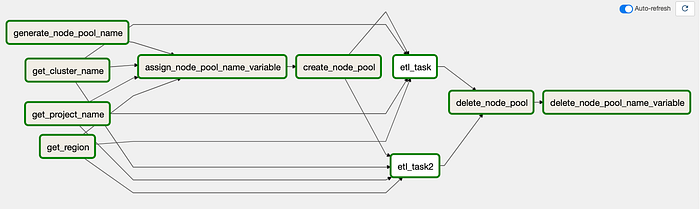
Visualisation de l'ancien DAG dans Airflow 2.0
Au premier coup d'œil, on remarque qu'il y a beaucoup plus de tâches et de flèches dans ce DAG. Comme le code se rapproche davantage de Python que d'Airflow, certaines tâches sont nécessaires pour récupérer des valeurs depuis l'environnement et les stocker dans des variables Python.
Avant d'aller plus loin, un petit grief à évacuer. La visualisation dans Airflow 2.0 peut prêter à confusion au début : elle a tendance à regrouper les éléments d'une manière qui complique le suivi visuel du flux d'exécution dans l'interface. Comme on le voit sur la capture ci-dessus, l'ensemble paraît un peu emmêlé avec toutes ces flèches.
Pour clarifier les choses, voici la portion de mon code Python qui définit le flux d'exécution (les éléments entre crochets s'exécutent en parallèle) :
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
Le premier groupe de tâches se contente de récupérer les valeurs de l'environnement Composer nécessaires à l'exécution, avant d'affecter le nom du pool de nœuds à une variable Airflow. Dans l'article précédent, tout cela tenait dans un seul BashOperator, mais je l'ai découpé pour gagner en lisibilité.
Vient ensuite la création du pool de nœuds, l'exécution en parallèle des deux tâches ETL factices, la suppression du pool une fois le travail terminé, puis enfin la suppression de la variable Airflow contenant le nom du pool de nœuds — une nouvelle étape de nettoyage que j'ai ajoutée. Elle aurait d'ailleurs dû figurer dans le précédent article. Le workflow reste le même, en un peu plus granulaire.
Comparaison des approches
Ces deux approches réalisent la même opération — planifier des conteneurs sur un cluster GKE pour exécution — avec une différence de coût très faible. La tarification GKE est disponible ici.
Il n'y a pas de réponse tranchée quant au meilleur choix : tout dépend de votre cas d'usage et de votre environnement. En règle générale, si vous n'avez pas de cluster GKE existant exécutant des workloads, mieux vaut utiliser un pool de nœuds sur le cluster Airflow. À l'inverse, si vous faites déjà tourner d'autres workloads sur un cluster GKE capable d'absorber la charge supplémentaire, autant planifier l'exécution sur ce cluster.
Notez que les tâches ETL sont en général très gourmandes en ressources. Si vous choisissez de les exécuter sur un cluster GKE existant, assurez-vous que les types d'instances des nœuds sont suffisamment dimensionnés pour absorber la consommation supplémentaire. Activer l'autoscaling par précaution peut aussi être une bonne idée.
Une approche hybride, consistant à créer un pool de nœuds dédié sur un cluster GKE existant puis à y planifier les exécutions, peut être la solution.
L'avenir avec Airflow 2.0
Maintenant qu'Airflow 2.0 est utilisé partout dans le monde, je m'attends à ce que Google bascule progressivement la majeure partie de la documentation existante et le recommande comme option par défaut pour tous les workloads Airflow. Je conseille vivement de commencer à migrer les workloads Airflow 1.0 existants et de bâtir tout nouveau workload sur Airflow 2.0.
La simplicité d'écriture des DAGs en Airflow 2.0 rend le code plus propre et plus lisible. La maintenance à long terme s'en trouve facilitée. Croyez-moi, vos développeurs vous en remercieront. Et je le dis en tant qu'ancien dev !
Comme le monde s'oriente vers des workloads conteneurisés pour la plupart des usages, je recommande vivement l'une des deux approches ci-dessus pour planifier les workloads sur GKE. Cela vous évitera bien des soucis, comme le montrait mon précédent article sur la planification et l'équilibrage des besoins de vos workloads.
Kubernetes s'est imposé comme l'approche de référence pour les workloads conteneurisés. Et puisque Google en est l'inventeur et a la bonne idée de maintenir GKE comme le service Kubernetes managé de référence, le plus logique est de l'exploiter là où il excelle. Gardez vos workloads aussi efficaces que possible pour de meilleurs résultats.
Merci de votre lecture ! Pour rester connecté, suivez-nous sur le blog DoiT Engineering, la page LinkedIn DoiT et le compte Twitter DoiT. Pour découvrir les opportunités de carrière, rendez-vous sur https://careers.doit-intl.com.