No meu artigo anterior, mostrei como rodar containers no Cloud Composer (o Apache Airflow gerenciado, para quem ainda não conhece). De lá pra cá, o Google lançou uma versão preview do Composer que usa o Airflow 2.0, uma baita atualização. Ela resolve vários problemas e ainda deixa o desenvolvimento mais parecido com programar em Python puro.

O Composer hoje suporta o Airflow 2.0.1. Por isso, vale destacar que este artigo foi escrito tendo essa versão específica em mente.
Não houve mudanças revolucionárias na linha do Airflow 2.0 no código que usei neste artigo. Mas, como aprendemos com o Airflow 1.0, isso pode mudar muito rápido com as novas versões que devem sair em breve. Então, leve isso em conta caso esteja consultando este código daqui a um ano ou mais usando a versão mais recente.
O artigo está dividido em duas partes. A primeira aborda algumas diferenças básicas entre o Airflow 1.0 e o 2.0 do ponto de vista do código, em especial no que uso na segunda parte. Já a segunda mostra como rodar containers em um cluster GKE recém-criado, e em seguida revisitamos o código do meu artigo anterior, agora atualizado para o Airflow 2.0.
Escrever arquivos Python vs. "escrever em Airflow"
Uma das maiores mudanças do Airflow 2.0 é permitir que você escreva uma DAG de um jeito mais simples, deixando o código mais legível. Essas mudanças têm sido muito bem recebidas pelos desenvolvedores que não são especialistas em Airflow.
Por exemplo, é assim que você define uma DAG no Airflow 2.0:
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
Compare com a definição no Airflow 1.0:
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Quem programa em Python agora consegue ler esse código sem dificuldade, e a DAG vira uma função que pode ser facilmente encapsulada por frameworks de teste. Outro ponto é a simplicidade na hora de passar dados entre tarefas. No antigo Airflow 1.0, era preciso usar XComs e fazer alguns malabarismos complexos para enviar a saída de um script bash para outra tarefa. Olha só este código:
# operador que exibe uma mensagem e a envia para o xcom
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# dentro de outro PythonOperator com provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
Já no Airflow 2.0, o mesmo código fica muito mais direto:
# atribui a saída à variável `output` para uso posterior na DAG
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
Fica nítido que o novo código é bem mais limpo e facilita para o desenvolvedor capturar a saída desse comando bash.
Operações no GKE: Airflow 1.0 vs. 2.0
No artigo anterior, usei o KubernetesPodOperator para rodar um container dentro de um cluster GKE. Funcionava bem, mas o Airflow 2.0 traz agora uma forma diferente de fazer isso, com resultados melhores. O Google criou um conjunto de operadores específicos para interagir com clusters GKE, em vez dos operadores Kubernetes mais genéricos do Airflow 1.0.
Os três operadores que vou usar agora são GKECreateClusterOperator, GKEStartPodOperator e GKEDeleteClusterOperator. Os nomes são bem autoexplicativos: criam um cluster GKE, iniciam um pod e excluem um cluster GKE, respectivamente. Vamos vê-los em ação em uma DAG bem simples no Airflow 2.0 para entender a dinâmica.
Exemplo de DAG GKE no Airflow 2.0
O repositório no GitHub que uso como referência no restante deste artigo está aqui. Nesta seção, faço referência ao arquivo new_cluster_gke_pod.py.
É uma DAG bem simples, que executa 3 operações: cria um cluster GKE, roda um processo dummy como pod nesse cluster e, por fim, exclui o cluster GKE. Isso facilita demonstrar a estrutura de uma DAG no Airflow 2.0 em comparação com o estilo antigo. Você vai notar logo de cara que o código é estruturado como um script Python, ao contrário da linguagem específica de domínio do Airflow 1.0.
Essa abordagem pode ser muito útil para rodar processos em um cluster GKE transitório, ou seja, que "vive" só pelo tempo necessário. Também é uma ótima forma de executar processos ad hoc que precisam do poder de um cluster Kubernetes, mas não exigem nenhum recurso após a conclusão.
Uma dica rápida sobre custos. Se for usar este método em produção, recomendo escolher um tipo de instância de computação que já tenha desconto e não seja elegível ao desconto por uso sustentado, como os tipos n2d. O motivo é que essas instâncias são de vida curta e não recebem nenhum desconto por uso sustentado. Então, ao usar um tipo de instância com desconto já aplicado, você economiza no longo prazo.
A DAG antiga reimaginada para o Airflow 2.0
No artigo anterior, mostrei como criar um novo node pool em um cluster GKE no Composer e agendar um pod dentro de uma DAG. O processo era relativamente simples e envolvia poucos passos. Um dos problemas com tecnologia nova é que, às vezes, o código existente precisa ser ajustado para continuar funcionando direito sem prejudicar a performance.
É um desses casos. Tive que adaptar o código para funcionar no Airflow 2.0, mas isso acabou sendo uma bênção disfarçada. Também me obrigou a aplicar o princípio KISS (Keep It Simple Stupid) à DAG existente e quebrar as operações em passos individuais mais simples. Resultado: ficou muito mais fácil de ler e acompanhar, já que cada passo foi separado para deixar seu propósito bem claro.
Você também vai notar que incluí um código de limpeza atualizado, que remove as variáveis do Airflow utilizadas.
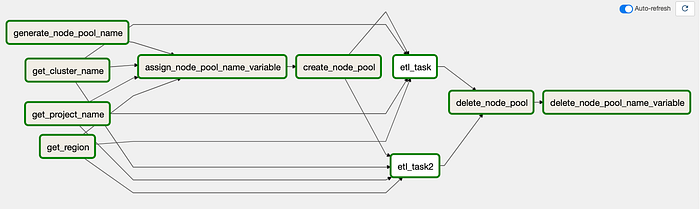
Visualização da DAG antiga no Airflow 2.0
De cara, dá pra ver que há bem mais tarefas e setas dentro desta DAG. Como o código ficou mais parecido com Python e menos com Airflow, é preciso ter algumas tarefas para extrair valores do ambiente e armazená-los como variáveis Python.
Antes de seguir, deixa eu desabafar uma coisa. A visualização no Airflow 2.0 pode confundir no começo, porque ela tende a agrupar elementos de um jeito que dificulta acompanhar o fluxo visualmente durante a execução na interface. Como dá pra ver na captura de tela acima, fica tudo meio embaralhado com as setas.
Pra simplificar e tirar a confusão, aqui está o trecho do meu código Python que define o fluxo de execução (itens entre colchetes rodam em paralelo):
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
O primeiro conjunto de tarefas simplesmente extrai os valores do ambiente Composer necessários para a execução, seguido da atribuição do nome do node pool a uma variável do Airflow. No artigo anterior, tudo isso estava num único BashOperator, mas separei pra simplificar.
Em seguida, cria-se o node pool, rodam-se as duas tarefas dummy de ETL em paralelo, exclui-se o node pool ao concluir e, por fim, apaga-se a variável que guarda o nome do node pool no Airflow — um novo passo que adicionei para limpeza. Esse passo deveria ter sido feito no artigo anterior também. É o mesmo workflow de antes, só que um pouco mais granular.
Comparando as abordagens
Ambas as abordagens fazem a mesma coisa: agendar containers em um cluster GKE para execução, com uma diferença mínima de preço. Os preços do GKE podem ser consultados aqui.
Não existe uma resposta definitiva sobre qual é a melhor escolha — vai depender do seu caso de uso e do seu ambiente. Em geral, se você não tem um cluster GKE rodando workloads, pode ser interessante usar um node pool no cluster do Airflow. Mas se já roda outros workloads em um cluster GKE que dá conta da carga adicional, o ideal é agendar nesse cluster.
Vale lembrar que tarefas de ETL costumam consumir muitos recursos. Ou seja, se optar por rodar em um cluster GKE existente, garanta que os tipos de instância dos nós sejam grandes o suficiente para suportar o uso extra. Também pode ser uma boa ideia habilitar o autoscaling, só pra garantir.
Uma abordagem híbrida — criar um node pool separado em um cluster GKE existente e agendar nele — pode ser a saída.
Seguindo em frente com o Airflow 2.0
Com o Airflow 2.0 já em uso no mundo todo, é bem provável que o Google comece a migrar boa parte da documentação existente e a recomendá-lo como opção padrão para todos os workloads do Airflow. Recomendo fortemente começar a migrar os workloads existentes do Airflow 1.0 e desenvolver todos os novos no Airflow 2.0.
A forma mais simples de escrever DAGs no Airflow 2.0 deixa o código mais limpo e legível, e isso facilita a manutenção no longo prazo. Pode acreditar: seus desenvolvedores vão agradecer. Quem está falando é um ex-dev!
Como o mundo caminha cada vez mais para workloads em containers na maioria dos casos, recomendo fortemente usar uma das duas abordagens acima para agendar workloads no GKE. Isso evita muita dor de cabeça, como mostrei no meu último artigo sobre como agendar e balancear as necessidades dos seus workloads.
O Kubernetes é a abordagem de facto para workloads em containers. Já que o Google o inventou e, felizmente, mantém o GKE como o serviço gerenciado de Kubernetes de facto, o mais lógico é aproveitá-lo naquilo que ele faz muito bem. Mantenha seus workloads o mais eficientes possível para obter os melhores resultados.
Obrigado pela leitura! Para ficar por dentro, siga-nos no DoiT Engineering Blog, no LinkedIn da DoiT e no Twitter da DoiT. Para conhecer oportunidades de carreira, acesse https://careers.doit-intl.com.