En mi artículo anterior te mostré cómo ejecutar contenedores con Cloud Composer (Apache Airflow gestionado, para quienes recién empiezan). Desde su publicación, Google lanzó una versión preview de Composer que usa Airflow 2.0, una mejora considerable. Resuelve muchos problemas y, además, hace que el desarrollo se sienta más cercano a programar en Python.

Actualmente Composer es compatible con Airflow 2.0.1. Por eso, ten en cuenta que este artículo se escribió pensando específicamente en esa versión.
No ha habido cambios revolucionarios en la serie Airflow 2.0 dentro del código que utilicé en este artículo. Pero, como aprendimos con Airflow 1.0, esto puede cambiar muy rápido con las nuevas versiones que se vienen. Así que ten presente este detalle si retomas este código dentro de un año o más usando la versión más reciente.
El artículo se divide en dos secciones. La primera repasa algunas diferencias básicas entre Airflow 1.0 y 2.0 desde el código, puntualmente sobre lo que uso en la segunda parte. La segunda sección muestra cómo ejecutar contenedores en un cluster de GKE recién creado y, después, retomamos el código del artículo anterior actualizado para Airflow 2.0.
Escribir archivos en Python vs. "escribir en Airflow"
Uno de los cambios más importantes de Airflow 2.0 es que ahora puedes escribir un DAG de forma más sencilla, lo que hace el código más legible. Estos cambios son muy bien recibidos por desarrolladores que no son expertos en Airflow.
Por ejemplo, en Airflow 2.0 un DAG se define así:
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
Compáralo con la definición en Airflow 1.0:
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Los desarrolladores de Python ahora leen este código con facilidad, ya que el DAG se convierte en una función que se envuelve sin problemas con frameworks de pruebas. También se simplifica el paso de datos entre tareas. Con el viejo Airflow 1.0 había que recurrir a XComs y a varios rodeos complejos para llevar el output de una tarea de bash a otra. Mira este código:
# operator that echoes out a message and pushes it to xcom
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# inside another PythonOperator where provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
Con Airflow 2.0, ese mismo código es mucho más directo:
# assigns output to the `output` variable for use later in the DAG
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
Queda claro que el código nuevo es mucho más limpio y le facilita al desarrollador obtener el output de ese comando de bash.
Operaciones de GKE en Airflow 1.0 vs. 2.0
En mi artículo anterior usé el KubernetesPodOperator para ejecutar un contenedor dentro de un cluster de GKE. Funcionaba bien, pero Airflow 2.0 ahora ofrece otra forma de hacerlo con mejores resultados. Google creó un conjunto de operadores para interactuar específicamente con clusters de GKE, en vez de los más generales de Kubernetes que había en Airflow 1.0.
Los tres operadores que voy a usar son GKECreateClusterOperator, GKEStartPodOperator y GKEDeleteClusterOperator. Los nombres hablan por sí solos: crean un cluster de GKE, inician un pod y eliminan un cluster de GKE, respectivamente. Veámoslos en acción mediante un DAG muy simple en Airflow 2.0 para entender la dinámica.
Ejemplo de DAG de GKE en Airflow 2.0
El repositorio de GitHub que utilizo como referencia en el resto del artículo está aquí . En esta sección hago referencia al archivo new_cluster_gke_pod.py.
Es un DAG muy simple que realiza 3 operaciones: crea un cluster de GKE, ejecuta un proceso ficticio como un pod en ese cluster y elimina el cluster. Resulta ideal para mostrar la estructura de un DAG en Airflow 2.0 frente al estilo antiguo. Pronto notarás que el código se estructura como un script de Python, a diferencia del lenguaje específico de dominio de Airflow 1.0.
Esto resulta muy útil para correr procesos en un cluster de GKE transitorio, es decir, que "vive" solo el tiempo necesario. También es una excelente forma de ejecutar procesos ad hoc que requieren la potencia de un cluster de Kubernetes, pero no necesitan recursos al terminar.
Un consejo rápido sobre Precios. Si vas a usar este método en producción, te recomiendo elegir un tipo de instancia de cómputo que ya tenga descuento aplicado y que no califique para descuentos por uso sostenido, como las instancias n2d. La razón es que son instancias de corta duración y no recibirán ningún descuento por uso sostenido . Así que, si usas un tipo de instancia con el descuento ya aplicado, vas a ahorrar dinero a la larga.
El DAG anterior reimaginado para Airflow 2.0
En mi artículo anterior mostré cómo crear un nuevo node pool en un cluster de GKE dentro de Composer y programar un pod dentro de un DAG. Era un proceso relativamente sencillo, con solo unos pocos pasos. Uno de los problemas con la tecnología nueva es que, a veces, hay que modificar el código existente para que funcione bien sin afectar el rendimiento.
Este es uno de esos casos. Tuve que adaptar el código para que funcionara en Airflow 2.0, pero terminó siendo una bendición disfrazada. También me obligó a aplicar el principio KISS (Keep It Simple Stupid) al DAG existente y descomponer las operaciones en pasos individuales más simples. Así, el código es mucho más fácil de leer y seguir, ya que cada paso queda separado y deja claro su propósito.
También notarás que agregué algo de código de limpieza actualizado que elimina las variables de Airflow utilizadas.
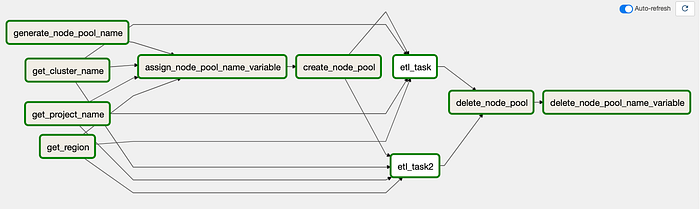
Visualización del DAG anterior en Airflow 2.0
A primera vista verás que hay muchas más tareas y flechas dentro de este DAG. Como se parece más a código Python y menos a Airflow, hacen falta algunas tareas para obtener valores del entorno y guardarlos como variables de Python.
Permíteme un pequeño desahogo antes de seguir. La visualización en Airflow 2.0 puede ser confusa al principio, ya que tiende a agrupar las cosas de formas que dificultan seguir el flujo en la interfaz durante la ejecución. Como ves en la captura de arriba, todo se ve un poco enredado con las flechas.
Para simplificarlo y aclarar la confusión, esta es la tarea de mi código Python que define el flujo de ejecución (los elementos entre corchetes se ejecutan en paralelo):
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
El primer grupo de tareas simplemente extrae del entorno de Composer los valores que se necesitan para la ejecución, y luego asigna el nombre del node pool a una variable de Airflow. En el artículo anterior todo esto estaba contenido en un único BashOperator, pero lo dividí para simplificar las cosas.
Después se crea el node pool, se ejecutan en paralelo las dos tareas ETL ficticias, se elimina el node pool al terminar y, por último, se elimina la variable de Airflow que contiene el nombre del node pool, un paso nuevo que agregué como limpieza. Este paso también debería haberse hecho en el artículo anterior. Es el mismo flujo de antes, solo que un poco más granular.
Comparación de los enfoques
Ambos enfoques realizan la misma operación de programar contenedores en un cluster de GKE para su ejecución, con una diferencia mínima en Precios. Los Precios de GKE se pueden consultar aquí .
No hay una respuesta clara sobre cuál es la mejor opción, ya que dependerá de tu caso de uso y de tu entorno. En general, si no tienes un cluster de GKE existente corriendo workloads, te conviene usar un node pool en el cluster de Airflow. Si ya corres otros workloads en un cluster de GKE que puede manejar la carga adicional, lo mejor es programar la ejecución en ese cluster.
Ten en cuenta que las tareas ETL suelen ser muy demandantes en recursos. Por eso, si decides ejecutarlas en un cluster de GKE existente, asegúrate de que los tipos de instancia de los nodos sean lo suficientemente grandes para manejar el uso adicional. También puede ser buena idea habilitar el autoscaling, por si acaso.
Un enfoque híbrido, que consiste en crear un node pool independiente en un cluster de GKE existente y programar ahí, puede ser la salida.
Avanzando con Airflow 2.0
Con Airflow 2.0 ya en uso a nivel global, espero que Google empiece a migrar la mayor parte de la documentación existente y lo recomiende como la opción por defecto para todos los workloads de Airflow. Recomiendo encarecidamente empezar a migrar los workloads de Airflow 1.0 y construir todos los nuevos sobre Airflow 2.0.
La forma más simple de escribir DAGs en Airflow 2.0 los hace más limpios y legibles. Eso facilita su mantenimiento a largo plazo. Créeme, tus desarrolladores te lo van a agradecer. ¡Te lo dice un ex desarrollador!
Como el mundo se mueve hacia workloads en contenedores para la mayoría de los casos, recomiendo usar uno de los dos enfoques anteriores para programar workloads en GKE. Te ahorrará muchos dolores de cabeza, como mostré en mi artículo anterior sobre cómo programar y balancear las necesidades de tus workloads.
Kubernetes es el enfoque de facto para los workloads en contenedores. Como Google lo inventó y, afortunadamente, mantiene a GKE como el servicio gestionado de Kubernetes de facto, lo más lógico es aprovecharlo para lo que hace muy bien. Mantén tus workloads lo más eficientes posible para obtener los mejores resultados.
¡Gracias por leer! Para mantenerte al tanto, síguenos en el DoiT Engineering Blog , en el canal de LinkedIn de DoiT y en el canal de Twitter de DoiT . Para explorar oportunidades laborales, visita https://careers.doit-intl.com .