Nel mio articolo precedente vi ho mostrato come eseguire container con Cloud Composer (Apache Airflow gestito, per chi non lo conoscesse). Da quando quell'articolo è stato pubblicato, Google ha rilasciato una preview di Composer basata su Airflow 2.0, un upgrade importante che risolve numerosi problemi e rende lo sviluppo molto più simile alla scrittura di codice Python.

Composer al momento supporta Airflow 2.0.1: tenete quindi presente che questo articolo è stato scritto pensando a questa specifica versione.
Nel codice della serie Airflow 2.0 che ho usato in questo articolo non ci sono stati cambiamenti rivoluzionari. Ma come abbiamo imparato con Airflow 1.0, le cose possono cambiare molto in fretta con le nuove versioni che verranno rilasciate a breve. Tenete quindi presente questo aspetto se userete questo codice fra un anno o giù di lì con la versione più recente.
L'articolo è diviso in due sezioni. La prima affronta alcune differenze di base tra Airflow 1.0 e 2.0 dal punto di vista del codice, in particolare riguardo a ciò che utilizzo nella seconda parte. La seconda mostra come eseguire container su un cluster GKE appena creato; al termine rivedremo la base di codice del mio articolo precedente, aggiornata per Airflow 2.0.
Scrivere file Python vs "scrivere in Airflow"
Tra i cambiamenti più rilevanti di Airflow 2.0 c'è la possibilità di scrivere un DAG in modo più semplice, rendendo il codice più leggibile. Sono novità apprezzate dagli sviluppatori che non sono esperti di Airflow.
Per esempio, in Airflow 2.0 per definire un DAG si scrive qualcosa di simile:
@dag(schedule_interval=None, default_args=default_args, catchup=False)
def composer_cluster_gke_pod_dag():
...
Confrontatelo con la definizione in Airflow 1.0:
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag:
...
Gli sviluppatori Python ora riescono a leggere agevolmente questo codice: il DAG diventa una funzione, facilmente incapsulabile dai framework di test. C'è poi la semplicità del passaggio dei dati tra task. Con il vecchio Airflow 1.0 era necessario ricorrere agli XCom e a workaround piuttosto complessi per portare l'output di un task bash dentro un altro. Date un'occhiata a questo codice:
# operator that echoes out a message and pushes it to xcom
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)# inside another PythonOperator where provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
Con Airflow 2.0, invece, lo stesso codice è molto più diretto:
# assigns output to the `output` variable for use later in the DAG
output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
È evidente che il nuovo codice è molto più pulito e rende più immediato per lo sviluppatore recuperare l'output di quel comando bash.
Operazioni GKE: Airflow 1.0 vs 2.0
Nell'articolo precedente avevo usato KubernetesPodOperator per eseguire un container all'interno di un cluster GKE. Funzionava bene, ma Airflow 2.0 propone ora un modo diverso di svolgere questa operazione, con risultati migliori. Google ha creato un set di operatori pensati specificamente per interagire con i cluster GKE, a differenza di quelli più generici per Kubernetes presenti in Airflow 1.0.
I tre operatori che userò ora sono GKECreateClusterOperator, GKEStartPodOperator e GKEDeleteClusterOperator. I nomi parlano da soli: rispettivamente creano un cluster GKE, avviano un pod ed eliminano un cluster GKE. Vediamoli all'opera attraverso un DAG Airflow 2.0 molto semplice, per coglierne le dinamiche.
Esempio di DAG Airflow 2.0 per GKE
Il repository GitHub a cui faccio riferimento per il resto dell'articolo si trova qui . In questa sezione faccio riferimento al file new_cluster_gke_pod.py.
Si tratta di un DAG molto semplice che esegue 3 operazioni: crea un cluster GKE, lancia un processo dummy come pod sul cluster GKE ed elimina il cluster GKE. È un buon modo per illustrare la struttura di un DAG Airflow 2.0 rispetto al vecchio stile. Noterete subito che il codice è strutturato come uno script Python, a differenza del linguaggio domain-specific di Airflow 1.0.
Questo approccio può rivelarsi molto utile per eseguire processi su un cluster GKE transitorio, ovvero che "vive" solo per il tempo necessario. Può inoltre essere un'ottima soluzione per eseguire processi ad hoc che richiedono la potenza di un cluster Kubernetes ma non hanno bisogno di alcuna risorsa al termine.
Un rapido suggerimento sui costi. Se utilizzate questo metodo in produzione, consiglio di scegliere un tipo di compute instance già scontato e non idoneo allo sustained use discount, come le istanze n2d. Il motivo è che si tratta di istanze di breve durata che non riceveranno alcuno sustained usage discount . Quindi, se utilizzate un tipo di istanza con lo sconto già applicato, risparmierete sul lungo periodo.
Il vecchio DAG ripensato per Airflow 2.0
Nell'articolo precedente avevo mostrato come creare un nuovo node pool su un cluster GKE in Composer e schedulare un pod all'interno di un DAG. Era un processo relativamente semplice, che richiedeva pochi passaggi. Uno dei problemi delle nuove tecnologie è che a volte il codice esistente va modificato per funzionare correttamente senza compromettere le prestazioni.
Questo è uno di quei casi. Ho dovuto modificare il codice perché funzionasse in Airflow 2.0, ma alla fine si è rivelato un male per bene. Mi ha anche costretto ad applicare il principio KISS (Keep It Simple Stupid) al DAG esistente e a scomporre le operazioni in singoli passaggi più semplici. Il risultato è molto più facile da leggere e seguire, perché ogni singolo passaggio è isolato in modo da renderne chiaro lo scopo.
Noterete inoltre che ho aggiunto del codice di pulizia aggiornato che rimuove le variabili Airflow utilizzate.
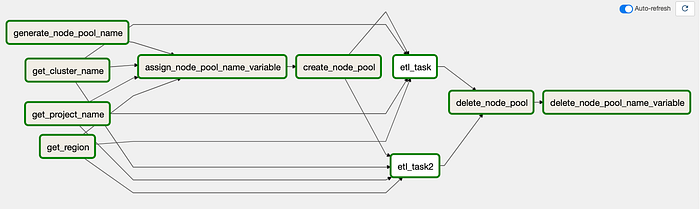
Visualizzazione del vecchio DAG in Airflow 2.0
A prima vista noterete che in questo DAG ci sono molti più task e frecce. Dato che assomiglia di più a codice Python e meno ad Airflow, alcuni task devono recuperare valori dall'ambiente e memorizzarli come variabili Python.
Tolgo subito un sassolino dalla scarpa, prima di proseguire. La visualizzazione in Airflow 2.0 inizialmente può confondere, perché tende a raggruppare gli elementi in modi che rendono difficile seguire visivamente il flusso durante l'esecuzione nell'interfaccia utente. Come si vede nello screenshot qui sopra, tutto appare un po' contorto a causa delle frecce.
Per semplificare e fare chiarezza, ecco il task del mio codice Python che definisce il flusso di esecuzione (gli elementi tra parentesi vengono eseguiti in parallelo):
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
Il primo gruppo di task si limita a recuperare dall'ambiente Composer i valori necessari all'esecuzione, dopodiché assegna il nome del node pool a una variabile Airflow. Nell'articolo precedente questi passaggi erano tutti racchiusi in un unico BashOperator, ma li ho scomposti per semplificare le cose.
A questo punto viene creato il node pool, eseguiti in parallelo i due task ETL dummy, eliminato il node pool al termine e infine cancellata la variabile Airflow che conteneva il nome del node pool: un nuovo passaggio che ho aggiunto per la pulizia. Andava fatto anche nell'articolo precedente. È lo stesso workflow di prima, solo un po' più granulare.
Confronto tra i due approcci
Entrambi gli approcci svolgono la stessa operazione di schedulare container su un cluster GKE, con una differenza di prezzo davvero minima. I prezzi di GKE sono disponibili qui .
Non esiste una risposta univoca su quale sia la scelta migliore: dipende dal vostro caso d'uso e dall'ambiente. In generale, se non avete un cluster GKE già attivo che esegue workloads, potreste optare per un node pool sul cluster Airflow. Se invece eseguite altri workloads su un cluster GKE in grado di sostenere il carico aggiuntivo, conviene schedulare le operazioni su quel cluster.
Tenete presente che i task ETL sono in generale molto onerosi in termini di risorse. Questo significa che, se scegliete di eseguirli su un cluster GKE esistente, dovete assicurarvi che i tipi di istanza dei nodi siano abbastanza capienti da gestire il consumo aggiuntivo. Potrebbe anche essere una buona idea abilitare l'autoscaling, giusto per andare sul sicuro.
Un approccio ibrido, che prevede la creazione di un node pool separato su un cluster GKE esistente e la successiva schedulazione su quest'ultimo, può essere la soluzione.
Guardare avanti con Airflow 2.0
Ora che Airflow 2.0 è utilizzato a livello globale, mi aspetto che Google inizi a spostare gran parte della documentazione esistente e a raccomandarlo come opzione predefinita per tutti i workloads Airflow. Consiglio caldamente di iniziare a migrare i workloads Airflow 1.0 esistenti e di costruire tutti i nuovi workloads su Airflow 2.0.
La maggiore semplicità nello scrivere DAG in Airflow 2.0 li rende più puliti e leggibili. Questo agevolerà la manutenzione nel lungo periodo. Fidatevi: i vostri sviluppatori lo apprezzeranno. Parola di ex sviluppatore!
Visto che il mondo si sta orientando verso workloads containerizzati per la maggior parte degli scopi, raccomando vivamente di adottare uno dei due approcci sopra descritti per schedulare i workloads su GKE. Vi risparmierà molti grattacapi, come illustrato nel mio ultimo articolo sulla schedulazione e sul bilanciamento delle esigenze dei vostri workloads.
Kubernetes è ormai lo standard de facto per i workloads in container. Dato che è stato Google a inventarlo e che, per fortuna, mantiene il proprio servizio GKE come servizio gestito Kubernetes di riferimento, la cosa più logica è sfruttarlo al meglio per ciò in cui eccelle. Mantenete i vostri workloads il più efficienti possibile per ottenere risultati ottimali.
Grazie per la lettura! Per restare in contatto, seguiteci sul DoiT Engineering Blog , sul canale LinkedIn di DoiT e sul canale Twitter di DoiT . Per scoprire le opportunità di carriera, visitate https://careers.doit-intl.com .