本記事は、BigQueryから複製したデータをClickHouseで活用してクエリコストを削減する方法を扱った前回のシリーズ(パート1、パート2)の続編です。今回ご紹介する仕組みは前シリーズの執筆時点ではまだ発表されていなかったもので、今年初めにGAとして提供開始されて以降、データ複製の手段として有力な選択肢になりました。
本記事の主役は、Continuous Queriesという機能です。ひと言でいえば、BigQueryのテーブルにデータがロード・更新されるたびに結果を返し続ける「終わらないクエリ」を実現する仕組みです。リレーショナルデータベースに馴染みのある方であれば、従来のRDBが備えるチェンジデータキャプチャ(CDC)を簡略化したものとイメージしていただくとわかりやすいでしょう。
前置きはこのくらいにして、本題に入りましょう。まずは、今回構築する全体像をざっくり示します。
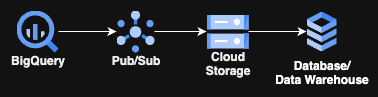
ご覧のとおり、Cloud RunやGKEといった派手なコンピュート系サービスは登場しません。GCPのマネージドサービス3つと、最終段のストレージ先を選ぶだけです。しかも、書く必要があるコードはわずか数行のSQLだけ。
それでは、さっそく見ていきましょう。
はじめる前に
唯一の前提条件は、対象プロジェクトでリザベーションの作成とクエリ実行に必要なIAM権限を持っていることです。OwnerやEditorがあれば申し分ありませんが、BigQuery Adminでも必要なものはすべて揃います。なお、メインのBigQuery Admin以外の「BigQuery * Admin」系ロールでは、本作業に必要な権限が不足します。
ワークフロー
処理の流れは、上図とほぼ同じで、それほど複雑ではありません。BigQuery上で継続実行されるクエリ(その名のとおりContinuous Query)がPub/Subトピックにデータを送り、紐づいたPub/SubサブスクリプションがそれをGCSバケットへ流し込みます。あとはETL/ELTプロセスがそのデータを取り込み、最終的な保存先や変換先へ配置するだけです。
料金
実装の詳細に入る前に、料金面の見通しを共有しておきます。新しいおもちゃは誰しも気になるものですが、値札を見るまでは、というのが世の常ですから。
コストが発生する要素は次のとおり複数あります。
- BigQueryのコスト
- Pub/Subのコスト
- GCSのコスト
- 下り(Egress)のコスト(場合による)
それぞれの内訳を順に整理し、執筆時点の料金も併記します。試される方が予想外の請求に驚かないようにするためです。
- BigQueryのコスト
BigQueryには課金要素が多数ありますが、今回のプロセスで気にすべきコストは1つだけ。BigQuery Editionsのリザベーションを介してContinuous Queryに発生するコンピュートコストです。
Continuous Queryを使うには、EnterpriseまたはEnterprise Plusのリザベーションが必要で、これはキャパシティベースの課金モデルに含まれます。注意点として、Continuous Queryではオンデマンド課金モデル(いわゆる「スキャン1 TiBあたり5ドルまたは6.25ドル」のモデル)は利用できません。そのため、現在オンデマンドモデルのみを使っている場合は、Continuous Query実行用に別プロジェクトを作成し、リザベーションを割り当てる必要があるかもしれません。組織全体でEditionsを有効化する前に、BigQuery Editionsについて以前書いたこちらの記事に必ず目を通すことを強くおすすめします。よく検討せずにEditionsをオンにすると、思わぬ高額出費につながりかねません。
Googleによれば、Continuous Queryは常に最低1スロットを消費します。これは、クエリ実行中は常時最小値(ベースライン)として50スロットが割り当てられることを意味します。したがって、リザベーションを作成してベースラインを50に設定し、最大スロット数はクエリに必要な値へ調整するのが定石です。基本的な検証であれば、ベースラインも最大値も50スロットあれば十分すぎるほどです。クエリを実行していないときは、コスト削減のためにアサインメントを削除するか、ベースラインを0に設定するのを忘れないでください。
スロット/時間あたりの料金はリージョンとEditionによって異なるため、公式の料金表はこちらでご確認ください。
- Pub/Subのコスト
今回の例におけるPub/Subのコストは1点だけ、こちらに記載されているCloud Storageサブスクリプションのスループット料金です。
執筆時点では、Pub/Subを通じてGCSへ流れるデータ1 TiBあたり50米ドルです(TBではなくTiBである点にご注意ください)。なお、「basic以外」のサブスクリプションを利用する場合、10 GiBの無料枠は適用されません。
このコストを見積もるには、対象テーブルのストレージが30日間でどれだけ増えるかを確認します(Googleが提供するサンプルクエリを使ってTABLE_STORAGE_USAGE_TIMELINEビューで調べられます)。その量に50ドル/TiBを掛ければ、月額のPub/Subコストが算出できます。
ここでは、保持期間やフィルタを設定せず、メッセージが24時間以上未確認のまま残ることもないデフォルト設定を前提にしています。これらにはいずれも追加料金が発生しますが、本例では使用しません。
- GCSのコスト
GCS関連のコストは、関与する要素が多いため少々複雑で、簡単には算出しづらい部分です。ここではざっくりとした計算で進めます。
最初のコストはストレージ、つまり「どれだけのデータをどのくらいの期間保管するか」です。これまで見てきた多くの事例では、データをいったんGCSに投入し、すぐに新しいデータベースまたはデータウェアハウスへロードして、保持期間を7日程度に設定し自動削除するという運用が一般的でした。
この場合の計算はシンプルです。保管されるGB数(ここではGiBではなくGB)×ストレージ単価(料金表はこちら)×(保持期間7日 / 月の30日)で求められます。
次のコストはGCSのオペレーション料金で、Class AとClass Bの2種類に分かれます。公式ドキュメントはこちらです。今回の文脈では、Class Aは単一ファイルの書き込み(storage.objects.insert)、Class Bは単一ファイルの読み込み(storage.objects.get)に該当します。
ここからが厄介で、求める「リアルタイム性」のレベルによって、これらのオペレーション発生回数が大きく変わります。Pub/Subはファイルを1回読み取り、最終出力先へのロードでそのファイルがもう1回読み取られます。つまり、Pub/SubがGCSへ書き込む各ファイルにつき、書き込み1回と少なくとも読み取り1回(出力先が複数あればその分追加)が発生します。
Pub/Subサブスクリプションを設定する際には、配信時のファイル最大サイズと時間の閾値を指定でき、いずれかの条件を満たした時点でファイルがGCSへ書き込まれます。これらの値を上下させたり、データ量が変動したりすると、実行されるオペレーション数は劇的に変わります。結果としてコストの方程式に複数の変数が加わり、大学で多変数微分方程式を学んだエンジニアや研究者なら誰もが知っているとおり、多変数方程式を簡単にモデル化する方法は存在しません。
そこで、まずは時間軸に注目するのがおすすめです。アメリカでよく言われるように「Time is money(時は金なり)」だからです。計算をシンプルにするため、最大5分間の継続時間を設定し、データが常に一定量で流れ続け、単一の出力先が同じく5分ごとに読み取るという、現実にはあり得ない理想的な状況を想定しましょう。
この場合、5分ごとにClass A操作1回とClass B操作1回が発生し、月間ではそれぞれ8,640回となります(30日間の43,200分 ÷ 5分)。
月あたりのコストは次のとおりです(料金表はこちら)。
Class A: (8640/1000) × $0.0050 = $0.0432
Class B: (8640/1000) × $0.0004 = $0.003456
合計: $0.047/月
低く見えるかもしれませんが、これはデータが常時流れ続ける、ごく低負荷のworkloadsを想定した数字である点にご注意ください。現実にはこのようなことは起こりませんし、データの鮮度も5分遅れになります。それでも、多くのユーザーにとって「概ね妥当な」金額を見積もる方法としては有用です。
- 下り(Egress)コスト
こちらは多くのお客様にとって「あくまで可能性」の話ですが、出力先が同じリージョンにない場合や、GCSバケットからクラウドの境界をまたぐ場合は、データロードに伴って下りの料金が発生する可能性がある点は押さえておきましょう。
料金については参考までにこちらに記載されています。
GCSのセットアップ
最初の(そしておそらく最も簡単な)ステップは、GCSバケットの用意です。最も手軽なのは公式ドキュメント(こちら)の手順に従うことで、ロケーション設定にはご注意ください。下りの料金を避けるため、出力先(できればBigQueryデータセットの入力元も)と同じリージョンに配置することを強くおすすめします。
Pub/Subのセットアップ
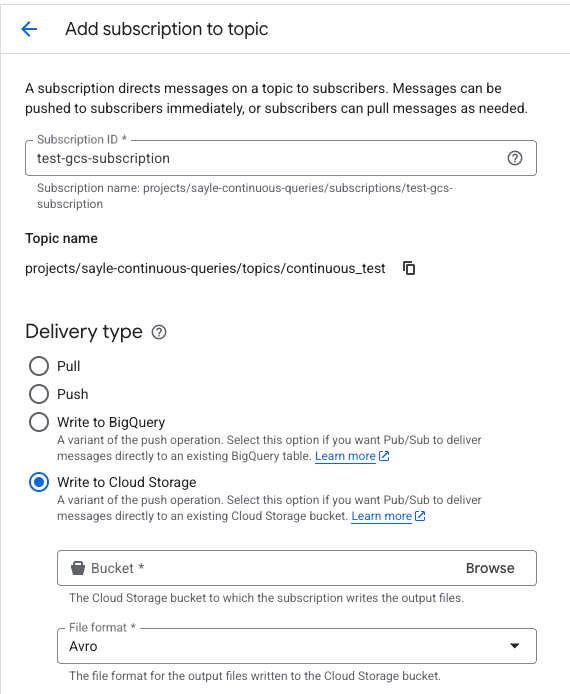
サービスアカウント(IAM)のセットアップ
執筆時点では、Continuous Queryをユーザーアカウントで実行する場合、こちらに記載のとおり2日ごとにクエリを再起動する必要があるという制約があります。サービスアカウントを使うのが最善で、その場合は制限が150日まで延びます。
そこで、このステップでは以下の権限を持つサービスアカウントを作成してください。
pubsub.topics.publish
pubsub.topics.get
加えて、BigQuery Data Viewerロール(roles/bigquery.dataViewer)も必要です。検証では、このロールに含まれる権限がすべて揃わないと動作しませんでした。BigQueryが内部で何らかの処理を行っており、これらの権限がすべて必要になるようです。
最小権限の原則に従うため、必要な権限をまとめたカスタムロールを作成することをおすすめします。
なお、Continuous Queryを初めて実行すると、このサービスアカウントにはBigQuery Continuous Query Service Agentというロールが自動的に付与されます。
BigQueryのセットアップ
このパズルの2つ目のピースは、BigQueryとContinuous Queryのセットアップです。
本格的に取り掛かる前に、Googleの紹介ページ(こちら)でContinuous Queriesについて一読しておくとよいでしょう。概要を把握でき、機能と制限の理解にも役立ちます。SQLとリージョン周りの制限が支障にならないか、目を通しておくことをおすすめします。本記事の執筆中に判明した大きな制約の1つは、ドキュメントで「CDC upsertデータ」と呼ばれる、Datastreamによって書き込まれたテーブルがサポートされていない点です。Datastreamを利用している場合は、修正を待つか、Continuous Queryで参照可能になるよう新しいテーブルにデータを移すのがよいでしょう。
準備ができたら、ジョブの作成とデータのエクスポートに必要な権限を整えるため、ドキュメントのこちらのページにも軽く目を通しておくことをおすすめします。これに加えて、Pub/Subの読み書きを可能にするロール(通常はPub/Sub ViewerおよびPublisherロール)も必要です。
次に、新しいレコードをエクスポートしたいテーブルを用意します(執筆時点ではJOINが許可されていないため、対象は1テーブルのみです)。以下の例ではこのテーブルをticketsとし、完全修飾名はmyproject.test_dataset.tickets、列はticket_id、assigned_to、assignment_timeの3つとします。
テーブルのDDLは次のとおりです。
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
このテーブルへデータをロードするために、ランダムなサンプルデータを生成するシンプルなPythonスクリプトをこちらのgistに用意しています。このスクリプトを実行し、生成されたファイルをGCSバケットに置く形で、以降のステップに進みます。
ワークフローの実行
クエリを書き始める前に、Pub/Subトピックを別タブで開いておくと、次のステップでパスを簡単にコピー&ペーストできて便利です。
続いて、BigQuery Studioのエディタを開き、以下のクエリを貼り付けます(プロジェクト名とPub/Subトピックは適宜書き換えてください)。
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
このクエリの動きを分解すると、次のとおりです。
まず、結果をPub/Subトピックへエクスポートすることを宣言し(取得方法は次の段落を参照)、テーブルの3列からなるstructを作成し、最後にそれをmessage列としてJSON文字列にカプセル化しています。これはPub/Subへのエクスポートサービスで必須の形式です。assigned_toがNULLでないものに絞り込んでいるのは単なる例示で、先ほどの生成コードを使う限りNULLになることはありません。
上記のURIオプションについては、Pub/Subトピックページからトピック名をコピーする方法をおすすめします(ページ上部に「projects/<project_name>/topics/<topic_name>」のような文字列とコピーボタンが表示されています)。これを「https://pubsub.googleapis.com」の文字列の後ろに貼り付ければ、タイプミスを防げます。
APPENDS関数は、プレビュー段階の終盤にGoogleが追加したもので、指定した時間範囲内の新規レコードをまとめて取得します。今回はテストなので1分に設定しています。さかのぼって古いデータを取得したい場合は、この間隔を長くすればOKです。
実行ボタンを押す前に、もう2つ小さなステップが残っています。
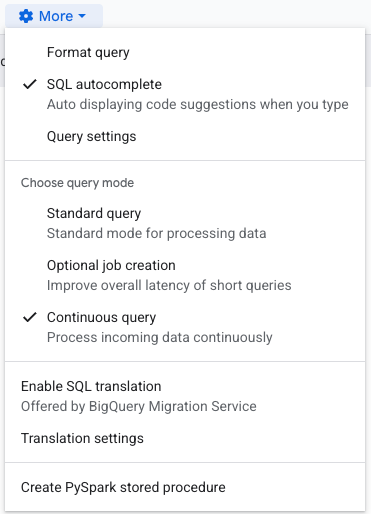
まず、Pub/Subエクスポートはcontinuous queryのみサポートというエラーが赤字で表示されるはずです。つまり、これをcontinuous queryとして設定する必要があります。クエリ上部の「More(歯車アイコン)」をクリックし、以下のように「Continuous query」を選択してください。
実行に使うサービスアカウントを指定する必要があるので、再度「More(歯車アイコン)」をクリックし、「Query settings」を選びます。「Continuous query IAM permissions」の下で、先ほど作成したサービスアカウントを選択してください。
あとは実行ボタンを押せば、プロセスがスタートします。
注意:リザベーションを設定し、現在のプロジェクトに対してcontinuousジョブタイプのアサインメントを作成していない場合、次のような赤いエラーメッセージが表示されます。「Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US.」これを解消するには、本記事の前半で説明したとおり、リザベーションを作成し、このプロジェクトをcontinuousジョブタイプとして割り当てる必要があります。
この時点でクエリは実行中となり、UI上では長時間実行されるクエリのように見えます。
注意:アサインメントを削除したり、リザベーションを削除したりすると、ジョブは停止します。
Pub/Subへのエクスポートが正しく動作しているか確認するには、先ほどリンクしたPythonスクリプト(こちら)を実行してGCSバケットにアップロードします。続いて、次のような簡単なロード文を実行します。
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
数分待ってからPub/Subサブスクリプションを確認すると、次のような表示が見られるはずです。
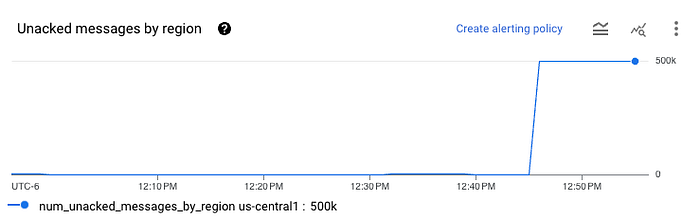
これは、サブスクリプションへのデータロードが成功したことを示しています。次にバケットを確認すると、Avroファイルがいくつか出力されているはずです。GCSからダウンロードして、オンラインのAvroファイルビューアにアップロードすれば中身を確認できます。dataという1列だけがあり、Pub/SubからのJSONエンコード済みデータがbase64形式で格納されています。
Pub/Subを介さずにGCS上のAvroへ直接書き出せる、もう少しすっきりした方法があればよかったのですが、Continuous QueriesはPub/Subへの出力のみをサポートしており、GCSへの直接出力はできません。直接出力できれば、BigQueryのSQLに合わせて列単位で書き出すことも可能になりますが、残念ながらGoogleはまだこれを実装していません。
データは届いた、次は何を?
ここまで来れば、データはAvro形式でGCSバケットに保存されており、ちょっとした工夫を加えればほぼあらゆるデータウェアハウスやデータベースにロードできる状態になっています。
本記事は前回シリーズの続編なので、その流れに沿ってClickHouseへロードしてみましょう。なお、以下のSQLコードを参考にすれば、同じ手法でDatabricks、Snowflake、DuckDBなどへも同じくらい手軽にロードできます。
それでは、ロードを実行するClickHouseのSQLを以下に示します。バケット名とGCPの情報は必ずご自身のものに書き換えてください。HMACキーの作成手順についてはこちらのリンクを参照してください。
SELECT
-- JSONデータから 'ticket_id' フィールドを整数として抽出します。
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- JSONデータから 'assigned_to' フィールドを文字列として抽出します。
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- JSONデータから 'assignment_time' フィールドを文字列として抽出し、
-- 適切なタイムスタンプ処理のためDateTime64型にキャストします。
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- `s3` テーブル関数は、S3またはS3互換サービスからファイルをクエリする際に使用します。
-- 関数のシグネチャは `s3(url, [access_key_id], [secret_access_key], format, structure)` です。
-- URLはHTTPSプロトコルでGCSバケットのエンドポイントを指す必要があります。
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
コードへのコメント追加とDateTime周りのコード生成については、Geminiに感謝です。その部分はどうしてもうまく動かせなかったので。
BigQueryをもっと「DoiT」しませんか?
本記事がお役に立ち、こうした特殊な課題の解決を支援する分野の専門家をオンデマンドで活用したい、あるいはクラウド支出のレビューを受けたいとお考えでしたら、ぜひDoiTのサービスをご覧ください。
これらのサービスやその他の提供内容について詳しくは、こちらをご確認ください。