Questo articolo è il seguito ideale della mia serie precedente (parti 1 e 2) sull'uso di ClickHouse con dati replicati da BigQuery per ridurre i costi delle query. Il meccanismo principale di cui parlo qui non era ancora stato annunciato all'epoca della serie; da quando è stato rilasciato in GA all'inizio di quest'anno, è diventato il metodo preferibile per replicare i dati.
Il fulcro di questo articolo è una funzionalità chiamata Continuous Queries: in pratica, una query senza fine che restituisce risultati man mano che i dati vengono caricati o aggiornati nelle tabelle BigQuery. Per chi proviene dal mondo dei database relazionali, è sostanzialmente una versione semplificata del change-data-capture (CDC) presente nella maggior parte dei database relazionali tradizionali.
Detto questo, entriamo nel vivo. Prima di tutto, ecco una panoramica veloce di come si presenterà la configurazione:
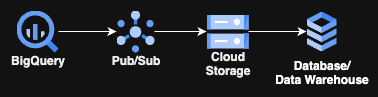
No, non servono Cloud Run, GKE o altri servizi di compute esotici: bastano 3 servizi gestiti GCP e poi lo storage che preferite per l'ultimo passaggio. La cosa migliore? L'unico codice da scrivere sono poche righe di SQL!
Ora vediamo i dettagli!
Prima di iniziare
L'unico vero prerequisito è disporre dei permessi IAM corretti per creare reservation ed eseguire query nel proprio progetto. Se avete il ruolo Owner o Editor, ottimo; in alternativa, BigQuery Admin offre tutto il necessario. Nessuno degli altri ruoli "BigQuery * Admin", a parte quello principale, concede permessi sufficienti per portare a termine l'operazione.
Il workflow
Il funzionamento non è molto più complesso del diagramma riportato sopra. Prevede una query in esecuzione continua (chiamata, non a caso, Continuous Query) su BigQuery che alimenta un topic Pub/Sub, il quale a sua volta inoltra i dati, tramite una o più subscription Pub/Sub, a un bucket GCS. Da lì, un processo ETL/ELT preleva i dati e li deposita nella destinazione finale, di archiviazione o di trasformazione.
Prezzi
Preferisco sempre ridimensionare le aspettative prima di entrare nel dettaglio implementativo dei prezzi: i giocattoli nuovi piacciono a tutti, finché non si guarda il cartellino.
I costi derivano da diverse componenti:
- Costi BigQuery
- Costi Pub/Sub
- Costi GCS
- Costi di egress (eventualmente)
Vedremo cosa aspettarsi da ciascuna di esse, indicando i prezzi in vigore al momento della stesura, così chi sperimenterà questo approccio non si troverà davanti a una bolletta inattesa.
- Costi BigQuery
BigQuery prevede molte componenti che incidono sui costi, ma in questo processo dobbiamo preoccuparci di una sola voce: i costi di compute associati alla continuous query tramite una reservation BigQuery Editions.
Il continuous querying richiede l'uso di una reservation Enterprise o Enterprise Plus, che fa parte del modello di fatturazione capacity-based. Attenzione: NON è possibile usare il modello di fatturazione on-demand (cioè il modello "$5 o $6,25 per TiB scansionato") con le continuous queries. Per questo limite, se attualmente usate solo il modello on-demand, potreste dover creare un progetto separato e assegnarlo a una reservation per eseguirvi la continuous query. Vi consiglio VIVAMENTE di leggere il mio articolo originale su BigQuery Editions qui prima di attivarlo per l'intera organizzazione: farlo alla cieca può rivelarsi un'impresa molto costosa.
Le continuous queries consumano sempre almeno uno slot, secondo Google, il che si traduce in un minimo, o "baseline", di 50 slot allocati ogni volta che la query è in esecuzione. Conviene quindi creare una reservation con baseline a 50 e regolare il numero massimo di slot in base alle esigenze della propria query. Per i test di base, una baseline e un massimo di 50 slot sono più che sufficienti. Ricordatevi solo di rimuovere l'assegnazione o di portare la baseline a zero quando la query non è in esecuzione, per contenere i costi.
Le tariffe per slot/ora variano in base alla regione e all'Edition, quindi conviene consultare la tabella ufficiale dei prezzi qui.
- Costi Pub/Sub
Pub/Sub, in questo esempio, ha un'unica voce di costo: il prezzo del throughput delle subscription Cloud Storage, documentato qui.
Al momento della stesura, è di 50 USD per TiB (attenzione: TiB, non TB) che transita da Pub/Sub a GCS. Tenete presente che, con una subscription "non-basic", il free tier di 10 GiB non si applica.
Per stimare questo costo, osservate la crescita dello storage della vostra tabella nell'arco di 30 giorni (la trovate nella vista TABLE_STORAGE_USAGE_TIMELINE, usando le query di esempio fornite da Google) e moltiplicatela per 50 $/TiB per ottenere il costo mensile di Pub/Sub.
Il calcolo presuppone l'uso delle impostazioni predefinite, senza periodi di retention o filtri, e che i messaggi non restino non riconosciuti per più di 24 ore. Tutti questi aspetti comportano costi aggiuntivi, ma in questo esempio non li utilizzeremo.
- Costi GCS
I costi GCS associati sono il punto in cui le cose si fanno più complicate e difficili da calcolare con precisione, vista la quantità di fattori in gioco. Faremo quindi qualche stima approssimativa.
La prima voce è lo storage, ovvero la quantità di dati archiviati e per quanto tempo. Nella maggior parte dei casi che ho visto, i clienti caricano i dati su GCS e li trasferiscono subito in un nuovo database o data warehouse, con una retention di circa 7 giorni prima dell'eliminazione automatica.
In questo caso il calcolo è semplice: GB (in questo caso GB, non GiB) archiviati * tariffa di storage (la tabella è qui) * (7 giorni di retention/30 giorni del mese)
La voce successiva sono le operazioni GCS, suddivise in due categorie: operazioni di Classe A e di Classe B. La documentazione ufficiale è qui. In questo contesto, le operazioni di Classe A saranno scritture di singoli file (storage.objects.insert) e quelle di Classe B saranno letture di singoli file (storage.objects.get).
Qui le cose si complicano: il livello di "realtime" richiesto per i vostri dati determina quante di queste operazioni verranno effettuate. Pub/Sub esegue una singola lettura di un file e il successivo caricamento di quei dati verso l'output finale costituisce un'altra lettura dello stesso file. Avrete quindi una scrittura singola e almeno una lettura singola (di più se il caricamento avviene su più destinazioni) per ogni file che Pub/Sub scrive su GCS.
In fase di configurazione della subscription Pub/Sub potete specificare le soglie di dimensione massima del file e di durata; al verificarsi di una delle due, il file viene scritto su GCS. Modificare questi valori, in combinazione con quantità di dati diverse, cambia drasticamente il numero di operazioni eseguite. Si aggiungono così molteplici variabili all'equazione dei costi e, come può confermare qualunque ingegnere o scienziato che abbia seguito un corso universitario di equazioni differenziali multivariate, non esiste un modo semplice per modellare un'equazione multivariata.
In genere consiglio quindi di concentrarsi sull'aspetto temporale perché, come direbbero molti americani, "time is money". Per rendere i conti gestibili, immaginiamo una durata massima di 5 minuti, con un flusso di dati costante (e impossibile nella realtà) e un'unica destinazione che li legge a sua volta ogni 5 minuti.
Significa che ogni 5 minuti ci sarà una singola operazione di Classe A e una singola di Classe B, per un totale di 8.640 operazioni di ciascun tipo al mese (43.200 minuti su 30 giorni / 5 minuti).
Il costo mensile sarà quindi (la tabella dei prezzi è qui):
Classe A: (8640/1000) * $0,0050 = $0,0432
Classe B: (8640/1000) * $0,0004 = $0,003456
Totale: $0,047/mese
Può sembrare poco, ma considerate che si tratta di un workload costantemente basso con un flusso di dati continuo. Nella realtà non accadrebbe mai e produrrebbe dati con 5 minuti di latenza, ma è comunque un buon modo per stimare un prezzo "sufficientemente accurato" per la maggior parte degli utenti.
- Costi di egress
Per la maggior parte dei clienti si tratta di un grande "forse", ma tenete presente che, se la destinazione non è nella stessa regione o se si attraversano i confini di un altro cloud rispetto al bucket GCS, è probabile che vengano applicati addebiti di egress sul caricamento dei dati.
I prezzi sono indicati qui per riferimento.
Configurazione di GCS
Il primo passaggio (e probabilmente il più semplice) è creare un bucket GCS. Il modo più immediato è seguire la documentazione ufficiale qui, prestando attenzione alle impostazioni di location. Consiglio vivamente di posizionarlo nella stessa regione dell'output (e preferibilmente del dataset BigQuery di input) per azzerare gli addebiti di egress.
Configurazione di Pub/Sub
Il passaggio successivo è creare un topic Pub/Sub. È un argomento già trattato moltissime volte, quindi mi limito a rimandare alla documentazione ufficiale qui. Verificate solo di poter creare il topic e di disporre dei permessi/ruoli corretti.
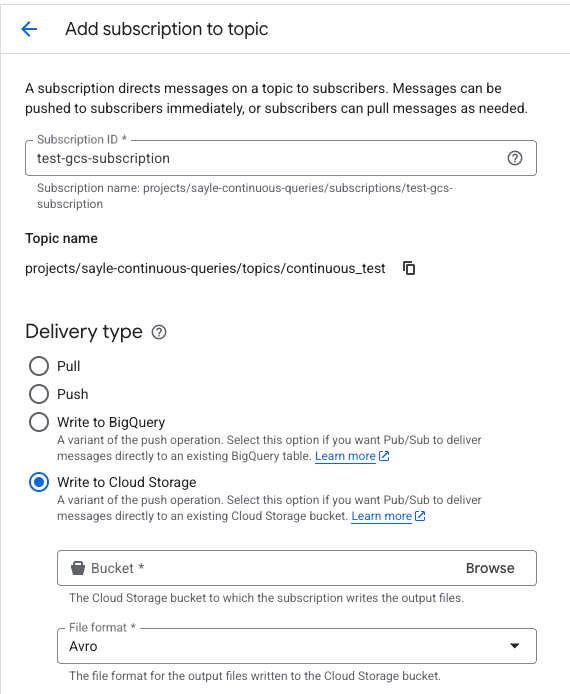
Prima di proseguire, dovete creare una subscription per questo topic con le opzioni "Write to Cloud Storage" e formato Avro impostate, come mostrato qui:
Nota: se non avete mai configurato una subscription GCS nel progetto, potreste vedere il messaggio sotto. In tal caso, fate clic sul pulsante "Set permission" e poi sui link di concessione del ruolo che compaiono nella sidebar.
Configurazione del Service Account (IAM)
Al momento della stesura, le continuous queries hanno una limitazione sugli account utente: la query va riavviata ogni due giorni, come riportato qui. La scelta migliore è usare un service account, che estende questo limite a 150 giorni.
Detto questo, per questo passaggio create un service account con i seguenti permessi:
pubsub.topics.publish
pubsub.topics.get
Servirà inoltre il ruolo BigQuery Data Viewer (roles/bigquery.dataViewer). Non sono riuscito a farlo funzionare con un sottoinsieme inferiore di permessi rispetto a quelli completi del ruolo, quindi pare che BigQuery faccia qualcosa dietro le quinte che li richiede tutti.
Consiglio di creare un ruolo personalizzato con tutti i permessi necessari, in linea con il Principio del Minimo Privilegio.
Tenete presente che, dopo la prima esecuzione di una continuous query, a questo service account verrà aggiunto automaticamente un ruolo chiamato BigQuery Continuous Query Service Agent.
Configurazione di BigQuery
Il secondo tassello di questo piccolo puzzle è BigQuery e la configurazione della continuous query.
Prima di addentrarsi, può essere utile leggere qualcosa sulle continuous queries qui, nella pagina introduttiva di Google: una buona panoramica per familiarizzare con potenzialità e limiti delle continuous queries. Consiglio di esaminare i limiti relativi a SQL e alle regioni per assicurarsi che non rappresentino un ostacolo. Un punto bloccante emerso durante la stesura di questo articolo è che non sono supportate le tabelle scritte da Datastream, indicate nella documentazione come dati CDC upsert; se quindi usate Datastream, conviene attendere la risoluzione del problema oppure spostare i dati in una nuova tabella, in modo che la continuous query possa interrogarla.
Quando siete pronti a partire, consiglio una breve lettura di questa pagina della documentazione per impostare i permessi corretti per la creazione dei job e l'esportazione dei dati. A questi si aggiunge un ruolo che consenta la lettura e la scrittura su Pub/Sub: di solito i ruoli Pub/Sub Viewer e Publisher.
Individuate poi la tabella, singola al momento della stesura visto che le join non sono ancora consentite, da cui volete esportare i nuovi record. Nell'esempio qui sotto la chiameremo tickets, con nome completo myproject.test_dataset.tickets, e avrà 3 colonne: ticket_id, assigned_to e assignment_time.
Ecco il DDL della tabella:
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
Per popolarla uso un semplice script Python disponibile qui in un gist, che genera dati di esempio casuali. Eseguo lo script e deposito i file in un bucket GCS per i passaggi successivi.
Esecuzione del workflow
Prima di scrivere la query, aprite una scheda aggiuntiva sul vostro topic Pub/Sub, così da poter copiare e incollare facilmente il path nel passaggio successivo.
Aprite poi l'editor di BigQuery Studio e incollate questa query (sostituendo il nome del progetto e il topic Pub/Sub):
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
Vediamo cosa fa questa query:
per prima cosa indica che esporterà i risultati in un topic Pub/Sub (vedi il paragrafo successivo per ottenerlo rapidamente), poi crea uno struct con le 3 colonne della tabella e infine le incapsula in una stringa JSON in una colonna chiamata message, come richiesto dal servizio di esportazione su Pub/Sub. Filtro su assigned_to non null solo a titolo di esempio; se si usa il codice di generazione, questa condizione non si verificherà mai.
Per l'opzione URI sopra, consiglio di copiare il nome del topic dalla pagina del topic Pub/Sub (in alto trovate qualcosa come "projects/<project_name>/topics/<topic_name>" con un pulsante di copia accanto) e di incollarlo nell'URI dopo la stringa "https://pubsub.googleapis.com", per evitare errori di battitura.
La chiamata APPENDS è una funzionalità che Google ha introdotto verso la fine della fase di preview; preleva semplicemente tutti i nuovi record nell'intervallo di tempo specificato. Trattandosi di un test, lo imposto a 1 minuto. Se serve recuperare dati più vecchi, basta aumentare l'intervallo.
Prima di premere Run, ci sono due piccoli passaggi da fare.
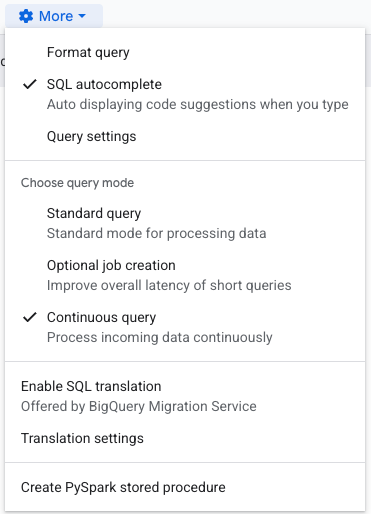
Prima di tutto, vedrete probabilmente un errore in rosso che segnala come l'esportazione su Pub/Sub sia supportata solo da continuous query: bisogna quindi impostarla come tale. Fate clic sull'icona dell'ingranaggio "More" sopra la query e selezionate "Continuous query", come mostrato qui:
Dovete scegliere il service account con cui eseguirla: selezionate di nuovo l'icona dell'ingranaggio "More" e poi "Query settings". In "Continuous query IAM permissions" indicate il service account creato in precedenza.
A questo punto, premete il pulsante Run e avviate il processo.
Nota: se non avete configurato la reservation né creato un'assegnazione per il progetto corrente per il tipo di job continuous, comparirà un messaggio di errore rosso simile a questo: "Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US." Per risolvere, dovrete creare una reservation e assegnarvi questo progetto per il tipo di job continuous, come indicato in precedenza in questo articolo.
A questo punto la query è in esecuzione e nell'interfaccia appare semplicemente come una query a lunga durata.
Nota: se rimuovete l'assegnazione o eliminate la reservation, il job verrà fermato.
Per testare la funzionalità di esportazione su Pub/Sub, eseguite lo script Python linkato sopra (qui) e caricate il file in un bucket GCS. Lanciate poi un caricamento rapido come questo:
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
Dopo qualche minuto, controllate la subscription Pub/Sub: dovreste vedere qualcosa di simile a questo:
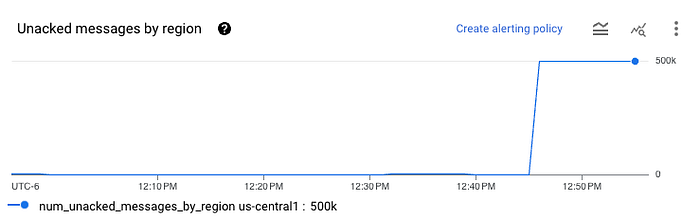
Significa che i dati sono stati caricati correttamente nella subscription. A quel punto, controllate il bucket: dovreste vedere comparire alcuni file Avro. Potete scaricarli da GCS e caricarli in un qualsiasi visualizzatore Avro online per ispezionarli. Vedrete una singola colonna chiamata data, con i dati JSON provenienti da Pub/Sub codificati in formato base64.
Mi sarebbe piaciuto un modo più pulito per arrivare ad Avro su GCS senza passare per Pub/Sub, ma le continuous queries supportano solo Pub/Sub e non la scrittura diretta su GCS. Sarebbe stato anche possibile scrivere colonna per colonna in linea con il vostro SQL BigQuery, ma purtroppo Google non lo ha ancora implementato.
I dati ci sono, e adesso?
A questo punto avete i vostri dati archiviati in formato Avro in un bucket GCS, da cui dovrebbero poter essere caricati praticamente in qualsiasi data warehouse o database con un po' di lavoro.
Visto che questo articolo è il seguito ideale della mia serie precedente, restiamo in tema e carichiamoli in ClickHouse. Tenete presente che potete altrettanto facilmente caricarli in Databricks, Snowflake, DuckDB e così via, con lo stesso metodo del codice SQL qui sotto.
Senza ulteriori indugi, ecco l'SQL ClickHouse per eseguire il caricamento. Ricordatevi solo di aggiornarlo con il nome del vostro bucket e con i dati GCP. Per le istruzioni sulla creazione di una chiave HMAC, fate riferimento a questo link.
SELECT
-- Extract the 'ticket_id' field from the JSON data as an integer.
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- Extract the 'assigned_to' field from the JSON data as a string.
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- Extract the 'assignment_time' field from the JSON data as a string,
-- then cast it to a DateTime64 type for proper timestamp handling.
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- The `s3` table function is used for querying files from S3 or S3-compatible services.
-- The function signature is `s3(url, [access_key_id], [secret_access_key], format, structure)`.
-- The URL should point to the GCS bucket endpoint using the HTTPS protocol.
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
Devo ringraziare Gemini per aver aggiunto i commenti al codice e per aver generato la parte DateTime, perché proprio non riuscivo a farla funzionare.
Vuoi "DoiT" meglio con BigQuery?
Se questo articolo le è stato utile e desidera avere a disposizione, on demand, un esperto di settore per affrontare problemi specifici come questo, oppure vuole una revisione delle proprie spese cloud, dia un'occhiata ai servizi offerti da DoiT.
Può scoprire di più su questi e sugli altri nostri servizi qui.