Cet article s'inscrit dans la continuité de ma précédente série (parties 1 et 2) consacrée à l'utilisation de ClickHouse avec des données répliquées depuis BigQuery, dans le but de réduire les coûts de requêtage. Le mécanisme principal abordé ici n'avait pas encore été annoncé à l'époque ; depuis sa mise en disponibilité générale plus tôt cette année, il constitue désormais une meilleure méthode pour répliquer ces données.
Cet article se concentre sur une fonctionnalité appelée Continuous Queries. Il s'agit en somme d'un moyen de faire tourner une requête sans fin qui retourne des résultats au fur et à mesure que des données sont chargées ou mises à jour dans les tables BigQuery. Pour celles et ceux qui viennent du monde des bases relationnelles, c'est une version allégée du change-data-capture (CDC) que la plupart des SGBD relationnels traditionnels proposent.
Sans plus attendre, entrons dans le vif du sujet. Tout d'abord, voici un aperçu rapide du workflow envisagé :
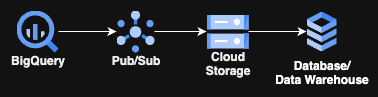
Pas besoin de Cloud Run, de GKE ou d'autres services de compute : 3 services managés GCP suffisent, plus le stockage de votre choix pour la dernière étape. Et le meilleur dans tout ça : le seul code à écrire se résume à quelques lignes de SQL !
C'est parti !
Avant de commencer
Le seul véritable prérequis est de disposer des bonnes permissions IAM pour créer des réservations et exécuter des requêtes dans votre projet. Si vous avez le rôle Owner ou Editor, c'est parfait, mais BigQuery Admin suffit amplement. En revanche, aucun des autres rôles " BigQuery * Admin " ne vous donnera les permissions nécessaires.
Le workflow
Le fonctionnement n'est guère plus compliqué que le schéma ci-dessus. Il repose sur une requête qui s'exécute en continu (d'où son nom de Continuous Query) sur BigQuery et qui alimente un topic Pub/Sub, lequel pousse à son tour les données vers un bucket GCS via les souscriptions Pub/Sub associées. Ensuite, un processus ETL/ELT récupère les données pour les déposer à leur emplacement final, ou pour les transformer.
Tarification
Je préfère toujours tempérer les attentes avant de plonger dans les détails d'implémentation, parce que tout le monde adore les nouveaux jouets technologiques… jusqu'à ce qu'on en voie le prix.
Plusieurs composants génèrent ici des coûts :
- Coûts BigQuery
- Coûts Pub/Sub
- Coûts GCS
- Coûts d'egress (potentiellement)
Je vais détailler ce à quoi s'attendre pour chacun, en m'appuyant sur les tarifs en vigueur au moment de la rédaction, afin que vous ne soyez pas surpris par une facture inattendue.
- Coûts BigQuery
BigQuery comporte de nombreuses composantes tarifaires, mais dans ce cas précis, un seul coût nous concerne : celui du compute associé à la continuous query via une réservation BigQuery Editions.
Les continuous queries imposent l'utilisation d'une réservation Enterprise ou Enterprise Plus, qui relève du modèle de facturation à la capacité. Notez que vous NE POUVEZ PAS utiliser le modèle on-demand (autrement dit le modèle à 5 ou 6,25 $ par TiB scanné) pour les continuous queries. En raison de cette limitation, si vous utilisez actuellement uniquement le modèle on-demand, vous devrez peut-être créer un projet distinct et l'assigner à une réservation pour y exécuter la continuous query. Je vous recommande FORTEMENT de lire mon article original sur BigQuery Editions ici avant d'activer cette option pour toute votre organisation. Activer Editions à l'aveugle peut s'avérer très coûteux.
Selon Google, les continuous queries consomment toujours au moins un slot, ce qui se traduit par un minimum (ou baseline) de 50 slots alloués dès lors que la requête tourne. Le mieux est donc de créer une réservation avec une baseline de 50, puis d'ajuster le maximum de slots selon les besoins de votre requête. Pour des tests basiques, une baseline et un maximum de 50 slots sont largement suffisants. Pensez simplement à supprimer l'assignation ou à remettre la baseline à zéro lorsque la requête ne tourne pas, pour éviter des frais inutiles.
Les tarifs par slot/heure varient selon la région et l'Edition ; le mieux est de consulter la table tarifaire officielle ici.
- Coûts Pub/Sub
Dans cet exemple, Pub/Sub n'engendre qu'un seul coût : celui du débit des souscriptions Cloud Storage, documenté ici.
Au moment de la rédaction, ce tarif est de 50 USD par TiB (attention, TiB et non TB) transitant par Pub/Sub vers GCS. À noter : avec une souscription non-basic, le palier gratuit de 10 GiB ne s'applique pas.
Pour estimer ce coût, observez la croissance du stockage de votre table sur 30 jours (visible dans la vue TABLE_STORAGE_USAGE_TIMELINE à l'aide des exemples de requêtes fournis par Google), puis multipliez ce volume par 50 $/TiB pour obtenir vos coûts mensuels Pub/Sub.
Je pars du principe que l'on utilise les paramètres par défaut, sans période de rétention ni filtres, et que les messages ne restent pas non acquittés au-delà de 24 heures. Tout cela engendrerait des frais supplémentaires, mais nous ne les utiliserons pas dans cet exemple.
- Coûts GCS
Les coûts GCS sont un peu plus complexes et difficiles à estimer précisément, en raison du nombre de facteurs en jeu. Nous allons donc faire des calculs approximatifs.
Le premier coût est celui du stockage : combien de données vous stockez et pendant combien de temps. Dans la plupart des cas que j'ai observés, les clients déposent les données dans GCS, puis les chargent immédiatement dans une nouvelle base ou un nouveau data warehouse, avec une rétention d'environ 7 jours avant suppression automatique.
Dans ce cas, le calcul est simple : Go (en GB, pas GiB) stockés × tarif de stockage (la table tarifaire est ici) × (7 jours de rétention / 30 jours par mois)
Le coût suivant concerne les opérations GCS, réparties en deux catégories : opérations de Classe A et de Classe B. Voici la documentation officielle à ce sujet. Dans notre contexte, les opérations de Classe A correspondent aux écritures de fichiers individuels (storage.objects.insert) et celles de Classe B aux lectures de fichiers individuels (storage.objects.get).
C'est là que ça se complique : le degré de temps réel dont vous avez besoin déterminera le nombre d'opérations effectuées. Pub/Sub effectuera une seule lecture par fichier, et le chargement de ces données vers la destination finale constituera une nouvelle lecture du même fichier. Vous aurez donc une écriture et au moins une lecture (plus si vous chargez vers plusieurs destinations) pour chaque fichier que Pub/Sub écrit dans GCS.
Lors de la configuration de votre souscription Pub/Sub, vous pouvez définir des seuils de taille maximale et de durée pour la livraison ; dès qu'une de ces conditions est remplie, le fichier est écrit dans GCS. Comme la modification de ces seuils, combinée à des volumes de données variables, change considérablement le nombre d'opérations effectuées, cela ajoute plusieurs variables à l'équation. Et tout ingénieur ou scientifique ayant suivi un cours d'équations différentielles à plusieurs variables vous le dira : modéliser une équation multivariée n'a rien d'évident.
Je conseille donc de se concentrer sur l'aspect temporel, car comme disent souvent les Américains, time is money. Pour rendre le calcul abordable, supposons une durée maximale de 5 minutes, un flux de données constant (ce qui est irréaliste) et une seule destination qui lit également toutes les 5 minutes.
Cela représente, toutes les 5 minutes, une opération de Classe A et une opération de Classe B, soit 8 640 opérations de chaque type par mois (43 200 minutes pour 30 jours / 5 minutes).
Le coût mensuel sera donc le suivant (la table tarifaire se trouve ici) :
Classe A : (8640/1000) × 0,0050 $ = 0,0432 $
Classe B : (8640/1000) × 0,0004 $ = 0,003456 $
Total : 0,047 $/mois
Cela peut sembler dérisoire, mais gardez à l'esprit qu'il s'agit d'un workload faible et constant. Ce scénario ne se produirait jamais en pratique et fournirait des données vieilles de 5 minutes, mais c'est une bonne base pour estimer un prix raisonnable pour la plupart des utilisateurs.
- Coûts d'egress
Cela ne concerne pas tout le monde, mais sachez que si votre destination ne se trouve pas dans la même région ou que vous franchissez les frontières d'un cloud depuis le bucket GCS, des frais d'egress s'appliqueront probablement lors du chargement des données.
La grille tarifaire est disponible ici pour référence.
Configuration GCS
La toute première étape (sans doute la plus simple) consiste à créer un bucket GCS. Le plus rapide est de suivre la documentation officielle ici, en prêtant attention à la localisation. Je recommande vivement de placer le bucket dans la même région que la destination (et idéalement que le dataset BigQuery source) pour éviter tout frais d'egress.
Configuration Pub/Sub
L'étape suivante consiste à créer un topic Pub/Sub. Le sujet a déjà été abordé de nombreuses fois, je me contenterai donc de renvoyer à la documentation officielle ici. Assurez-vous simplement de pouvoir créer ce topic et de disposer des permissions/rôles appropriés.
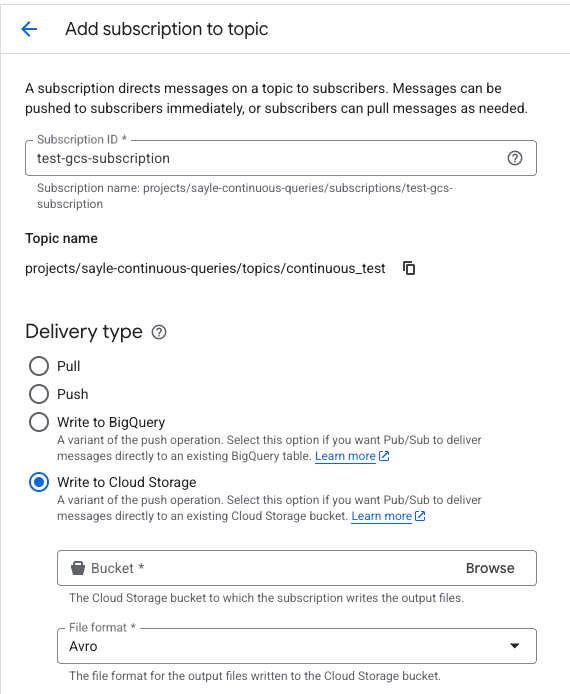
Avant de poursuivre, vous devrez créer une souscription pour ce topic avec les options Write to Cloud Storage et le format Avro activés, comme ci-dessous :
Note : si vous n'avez jamais configuré de souscription GCS dans le projet auparavant, le message ci-dessous peut s'afficher. Le cas échéant, cliquez simplement sur le bouton Set permission, puis sur les liens d'attribution de rôles qui apparaissent dans la barre latérale.
Configuration du compte de service (IAM)
Au moment de la rédaction, les continuous queries ont une limitation lorsqu'elles s'exécutent sous un compte utilisateur : elles doivent être redémarrées tous les deux jours, comme indiqué ici. La meilleure approche est d'utiliser un compte de service, ce qui repousse cette limite à 150 jours.
Pour cette étape, créez donc un compte de service avec les permissions suivantes :
pubsub.topics.publish
pubsub.topics.get
Il aura également besoin du rôle BigQuery Data Viewer (roles/bigquery.dataViewer). Je n'ai pas réussi à le faire fonctionner avec moins que toutes les permissions de ce rôle ; il semble que BigQuery effectue en interne des opérations qui les requièrent toutes.
Je recommande de créer un rôle personnalisé regroupant uniquement ces permissions afin de respecter le principe du moindre privilège.
À noter qu'après la première exécution d'une continuous query, le rôle BigQuery Continuous Query Service Agent sera automatiquement ajouté à ce compte de service.
Configuration BigQuery
La deuxième pièce de ce petit puzzle, c'est BigQuery et la mise en place de la continuous query.
Avant d'aller plus loin, il peut être utile de lire la page d'introduction de Google sur les continuous queries ici. Vous y découvrirez les capacités et limitations de cette fonctionnalité. Je recommande de prêter attention aux limitations relatives au SQL et aux régions, pour vérifier qu'elles ne seront pas bloquantes. Un blocage important relevé au cours de la rédaction de cet article : la fonctionnalité ne prend pas en charge les tables alimentées par Datastream (appelées CDC upsert data dans la documentation). Si vous utilisez Datastream, mieux vaut donc attendre que ce soit corrigé, ou déplacer les données vers une nouvelle table sur laquelle la continuous query pourra s'exécuter.
Lorsque vous êtes prêt à démarrer, je recommande de parcourir rapidement cette page de la documentation pour mettre en place les permissions nécessaires à la création de jobs et à l'export de données. Cela vient s'ajouter à un rôle permettant la lecture et l'écriture sur Pub/Sub, généralement les rôles Pub/Sub Viewer et Publisher.
Ensuite, identifiez la table — au singulier au moment de la rédaction, puisque les jointures ne sont pas encore autorisées — dont vous voulez exporter les nouveaux enregistrements. Dans l'exemple ci-dessous, nous l'appellerons tickets, avec le nom complet myproject.test_dataset.tickets, et 3 colonnes : ticket_id, assigned_to et assignment_time.
Voici le DDL correspondant :
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
Pour charger des données dans cette table, j'utilise un simple script Python disponible ici sous forme de gist, qui génère des données d'exemple aléatoires. Je l'exécute et dépose les fichiers résultants dans un bucket GCS pour les étapes suivantes.
Exécution du workflow
Avant d'écrire la requête, ouvrez un onglet supplémentaire vers votre topic Pub/Sub afin de pouvoir copier-coller facilement le chemin à l'étape suivante.
Ensuite, lancez l'éditeur BigQuery Studio et collez cette requête (en adaptant le nom du projet et celui du topic Pub/Sub) :
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
Décortiquons ce que fait cette requête :
Elle déclare d'abord qu'elle exportera les résultats vers un topic Pub/Sub (voir le paragraphe suivant pour récupérer rapidement ce chemin), construit ensuite une struct contenant les 3 colonnes de la table, puis encapsule le tout dans une chaîne JSON sous une colonne nommée message — ce qui est requis par le service d'export vers Pub/Sub. Je filtre sur assigned_to IS NOT NULL à titre d'exemple ; avec le code de génération fourni, ce cas ne se produira jamais.
Pour l'option URI ci-dessus, je recommande de copier le nom du topic depuis la page Pub/Sub (en haut de page, on trouve quelque chose comme projects/<project_name>/topics/<topic_name> avec un bouton de copie à côté) et de l'insérer dans l'URI après la chaîne https://pubsub.googleapis.com pour éviter les fautes de frappe.
L'appel APPENDS est une nouveauté ajoutée par Google tard dans la phase de preview, qui récupère simplement tous les nouveaux enregistrements dans l'intervalle de temps spécifié. Comme il s'agit d'un test, je le règle sur 1 minute. Si vous devez remonter plus loin pour récupérer des données antérieures, augmentez cet intervalle.
Avant de cliquer sur Run, deux petites étapes restent à effectuer.
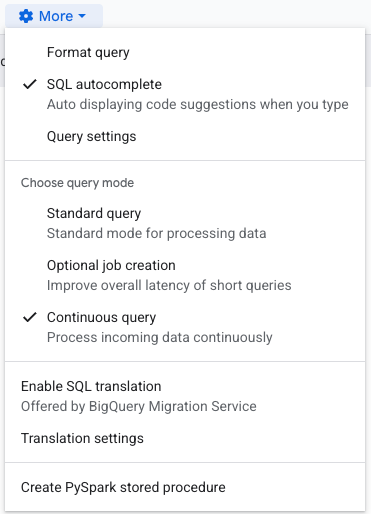
D'abord, vous verrez probablement un message d'erreur en rouge indiquant que l'export Pub/Sub n'est pris en charge qu'en continuous query : il faut donc la définir comme telle. Cliquez sur le More sprocket au-dessus de la requête et sélectionnez Continuous query, comme ci-dessous :
Vous devez choisir le compte de service sous lequel exécuter la requête : cliquez à nouveau sur le More sprocket et sélectionnez Query settings. Sous Continuous query IAM permissions, choisissez le compte de service créé précédemment.
Il ne vous reste plus qu'à cliquer sur Run pour lancer le processus.
Note : si vous n'avez pas configuré votre réservation ni créé d'assignation pour le projet courant pour le type de job continu, un message d'erreur rouge apparaîtra du type : Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US. Pour le résoudre, créez une réservation et assignez-y ce projet pour le type de job continu, comme expliqué plus haut.
À ce stade, la requête s'exécute, et apparaît dans l'interface comme une requête de longue durée.
Note : si vous supprimez l'assignation ou la réservation, le job s'arrête.
Pour tester l'export vers Pub/Sub, exécutez le script Python évoqué plus tôt (ici) et déposez le fichier dans un bucket GCS. Lancez ensuite un chargement rapide comme celui-ci :
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
Après quelques minutes d'attente, consultez la souscription Pub/Sub : vous devriez voir quelque chose comme ceci :
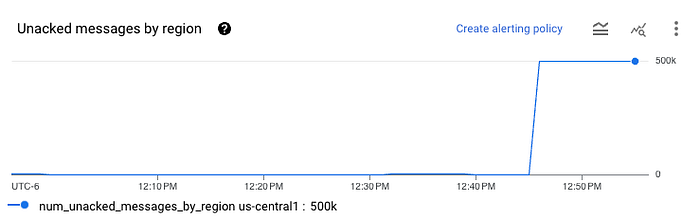
Cela signifie que les données ont été correctement transmises à la souscription. Vérifiez ensuite votre bucket : vous devriez y voir apparaître des fichiers Avro. Vous pouvez les télécharger depuis GCS et les charger dans n'importe quel visualiseur Avro en ligne pour les inspecter. Vous y verrez une seule colonne nommée data contenant les données JSON issues de Pub/Sub, encodées en base64.
J'aurais préféré une méthode plus propre pour produire des fichiers Avro directement sur GCS sans passer par Pub/Sub, mais les continuous queries ne savent envoyer leurs données qu'à Pub/Sub, pas directement vers GCS. Cela permettrait également d'écrire colonne par colonne pour coller à votre SQL BigQuery, mais Google ne l'a pas encore implémenté.
Les données sont là, et maintenant ?
À ce stade, vos données sont stockées au format Avro dans un bucket GCS et peuvent être chargées, moyennant un peu d'effort, dans à peu près n'importe quel data warehouse ou base de données.
Cet article étant la suite spirituelle de ma précédente série, restons dans le thème et chargeons-les dans ClickHouse. Notez qu'avec la même méthode et un SQL similaire à celui présenté ci-dessous, vous pouvez tout aussi facilement charger ces données dans Databricks, Snowflake, DuckDB, etc.
Sans plus attendre, voici le SQL ClickHouse pour effectuer le chargement. Pensez simplement à mettre à jour le nom du bucket et vos informations GCP. Consultez ce lien pour savoir comment créer une clé HMAC.
SELECT
-- Extract the 'ticket_id' field from the JSON data as an integer.
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- Extract the 'assigned_to' field from the JSON data as a string.
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- Extract the 'assignment_time' field from the JSON data as a string,
-- then cast it to a DateTime64 type for proper timestamp handling.
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- The `s3` table function is used for querying files from S3 or S3-compatible services.
-- The function signature is `s3(url, [access_key_id], [secret_access_key], format, structure)`.
-- The URL should point to the GCS bucket endpoint using the HTTPS protocol.
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
Un grand merci à Gemini pour avoir commenté mon code et généré la partie DateTime, que je n'arrivais tout simplement pas à faire fonctionner.
Envie d'aller plus loin avec BigQuery grâce à DoiT ?
Si cet article vous a été utile et que vous souhaitez bénéficier à la demande d'un expert pour vous accompagner sur des problématiques pointues comme celle-ci, ou pour faire auditer vos dépenses cloud, jetez un œil aux services proposés par DoiT.
Vous trouverez plus d'informations sur ces services et sur l'ensemble de notre offre ici.